kubernetes-k8s ☁️
- 1. 面试问题
- 2. 开发调试工具
- 基础设施即代码 IaC
- 3. deploying springcloud
- 4. what and why
- 5. 搭建环境
- 6. Quickstart
- operator
- 7. 集群结构 underlying infrastructure 基础设施
- 8. 管理的各种资源
- 8.1. 各种资源的关系
- 8.2. 3 common properties
- 8.3. node
- 8.4. pod
- 8.5. label
- 8.6. Taint(污点)和 Toleration(容忍)
- 8.7. controllers(各种控制器)
- 8.8. service
- 8.9. ingress
- 8.10. volume
- 8.11. secret
- 8.12. config map
- 8.13. flannel
- 8.14. name
- 8.15. name namespace (用来划分多环境)
- 9. 垃圾回收
- 10. 资源描述文件
- 11. 注解
- 12. 命名空间
- 13. pod 管理
- 14. pod 通信
- 15. 命令
- 16. cka ckad 证书考试
- 17. dashboard
- 18. rancher
- 19. Harbor
- 20. Helm
- 21. reference materials
1. 面试问题
为什么需要 pod? 为什么不能简单地把所有进程都放在一个单独的容器中?
- 如果在单个容器中运行多个不相关的进程, 那么保持所有进程运行(如失败重启)、 管理它们的日志会困难(日志会混在一起)。
为什么要将一个 app 的 前端服务器 和 后端服务器 分为 两个 pod 部署?
造成计算资源浪费: 如果部署到同一个 pod, 那么对于 双节点 k8s, 将总是只能利用一个节点
扩缩容不便: k8s 扩容基本单位就是 pod, 前后端若部署到同个 pod, 会造成扩缩容粒度太大. 而且对于 数据库服务器, 扩缩容无法这样简单处理
如何决定是否将多个 container 划分到一个 pod?
- 扩缩容是否能够一起进行
- 是否可以在同个主机运行
11 年运维工作经验,现从事腾讯工业互联网运维工作; DevOps 运维工程师,开源爱好者; 3 年+Kubernetes 平台经验,对 Kubernetes 生态有自己的认识;掌握 Jenkins+Gitlab+Helm 持续集成/持续交付工具链;对消息队列,缓存等中间件,软件架构体系有一定的了解;熟练掌握 shell 编程,熟悉 Python,Go 语言; TODO
2. 开发调试工具
一般来说k8s使用的容器网络与开发者的所在的办公网络并不能直接连通,如何在本地开发环境访问服务器上的k8s的服务?
- https://github.com/alibaba/kt-connect 阿里出品
- https://github.com/telepresenceio/telepresence windows 系统上安装复杂
- 利用 kubectl forward在本地建立 k8s 中服务的代理
kubectl port-forward <generated target pod name> <local port>:<target port>这里 pod name 名字不固定, 更好的办法是指定 deploymentkubectl port-forward deployment/<your pod name> <local post>:<target port>更好 或者 deployment 替换为 rs/svc
基础设施即代码 IaC
Infrastructure as Code : 通过编写简单的声明式语言来描述他们需要的基础架构资源,然后 Terraform 会自动完成创建、更新和删除等操作,从而简化了基础架构管理的过程
Terraform
Terraform 支持多种基础架构提供商,例如 Amazon Web Services(AWS)、Microsoft Azure、Google Cloud Platform(GCP)、OpenStack、VMware 等,以及多种基础架构资源,例如虚拟机、网络、存储、负载均衡、数据库等。用户可以在一个 Terraform 配置文件中定义他们需要的资源,然后使用 Terraform 命令行工具来执行这些操作。
可以用来管理 kubernetes
opentofu
IBM Cloud Schematics
3. deploying springcloud
https://github.com/Fenderon/springcloud-kubernetes-example
http://www.enmalvi.com/2022/05/27/springcloud-spring-cloud-kubernetes/
SpringCloud 通过 spring cloud kubernetes starter, 屏蔽了spring cloud 原来组件和 k8s 原生能力的差异
使用spring-cloud-kubernetes框架,该框架可以调用kubernetes的原生能力来为现有SpringCloud应用提供服务
服务发现. k8s的service
通过Spring Cloud Kubernetes Discovery自动将 HTTP 访问中的服务转换为 full qualified domain name
负载均衡.
采用 Kubernetes Service 本身的负载均衡能力实现,可以不再需要 Ribbon 这样的客户端负载均衡了
配置中心. k8s 的 Secret & ConfigMap
通过 springcloud kubernetes config 自动将 configMap 内容注入到 springboot 配置文件中并实现动态更新
最佳实践: Git维护配置的版本,CI/CD部署到Kubernetes集群的ConfigMap/Secret。
网关: k8s 提供 Ingress
网关部分 springcloud kubernetes 仍然保留了 Zuul,未采用 Ingress 代替。这里有两点考虑,一是 Ingress Controller 不算是 Kubernetes 的自带组件,它可以有不同的选择(KONG、Nginx、Haproxy,等等),同时也需要独立安装
熔断、降级、限流
Kubernetes本身没有熔断器,因此微服务框架中的熔断组件是有必要的 (Sentinel, Hystrix)
将在基于 Istio 的服务网格架构中解决这个问题
认证授权
仍然采用 Spring Security OAuth 2,Kubernetes 的 RBAC 授权可以解决服务层面的访问控制问题,但 Security 是跨越了业务和技术的边界的,认证授权模块本身仍承担着对前端用户的认证、授权职责,这部分是与业务相关的。
容器环境感知.
springcloud k8s 引入了 fabric8 的 kubernetes client
<!-- 整合了 k8s 的功能, 提供服务发现, 可以去掉 eurake 了 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-kubernetes</artifactId>
</dependency>
<!-- 负载均衡 -->
<!-- spring.cloud.loadbalancer.ribbon. enabled=false
-->
<!-- 本地调用kubernetes中的服务, 将spring.cloud.kubernetes.ribbon.mode修改为service,然后再将对应的服务开放一个端口出来,放一个nodeport出来就可以直接调用了。 -->
<!-- 本地项目中调用另一个本地服务是用的@FeignClient注解来实现的,那么就可以在@FeignClient注解中添加url参数来实现忽略name的功能从而实现本地请求到本地 ,
如 @FeignClient(name = "svcb-service",url = "${local.feign.server.svcb-service.url:}",fallback = ServiceBClient.ServiceBClientFallback.class) , 然后就可以在配置文件中配置 local.feign.server.svcb-service.url 为目标 ip:port, 建议配置成环境变量, 不要写死
-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-kubernetes-ribbon</artifactId>
</dependency>
<!-- 配置中心, 可以去掉 config server 了 -->
<!-- 但是不建议替换配置中心, config server 的存在方便配置文件的溯源 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-kubernetes-config</artifactId>
</dependency>
<!-- 自动维护 k8s deployment, service 资源定义文件, 产物在 meta-inf/fabric8 下 -->
<!-- 也可以自己在 src/main/fabric8 下重写deployment.yml, service.yml定义文件 -->
<build>
<plugins>
<plugin>
<groupId>io.fabric8</groupId>
<artifactId>fabric8-maven-plugin</artifactId>
<version>${fabric8.maven.plugin.version}</version>
<executions>
<execution>
<id>fmp</id>
<goals>
<goal>resource</goal>
<goal>build</goal>
</goals>
</execution>
</executions>
<configuration>
<!--docker需要开启远程访问-->
<dockerHost>http://haiyang.dockerhost.com:2375</dockerHost>
<enricher>
<config>
<fmp-service>
<type>NodePort</type>
</fmp-service>
</config>
</enricher>
<!--registry地址,用于推送镜像-->
<!-- <registry>ccr.ccs.tencentyun.com</registry>-->
<!--认证配置,用于私有registry认证,如果忘记了可以去阿里的registry查看-->
<authConfig>
<push>
<username>your usernmae</username>
<password>your password</password>
</push>
</authConfig>
</configuration>
</plugin>
</plugins>
</build>
<!-- fabric8插件生成的deployment还会自动生成readinessProbe和livenessProbe。 -->
<!-- 需要引入 actuator -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
3.1. using configMap
apiVersion: v1 by d
kind: ConfigMap
metadata:
# 必须和 应用名称一样
name: client-service
data:
# 这里的内容会被 client-service 作为配置文件, 覆盖应用内的配置
application.properties: |-
bean.message=Testing reload! Message from backend is: %s <br/> Services : %s
3.2. 部署到 k8s 后还是有缺点
随着 Kubernetes 集群中的 Pod 数量规模越来越庞大,到一定程度之后,运维的同学无奈地表示已经不可能够依靠人力来跟进微服务中出现的各种问题了:一个请求在哪个服务上调用失败啦?是 A 有调用 B 吗?还是 C 调用 D 时出错了?为什么这个请求、页面忽然卡住了?怎么调度到这个 Node 上的服务比其他 Node 慢那么多?
k8s 下的 springcloud 可配置, 可观测特性还有待加强 --> istio
4. what and why
4.1. k8s 是做什么的
抽象了数据中心的硬件基础设施,对外暴露统一的接口,具体包括
- 调度: k8s 自动决定组件部署到具体的哪一台 服务器节点。
- 自动修复: 自动检查节点的健康状态, 吧程序迁移到健康的节点上
- 水平伸缩: 自动检测业务的负载情况, 如果 CPU 负载太高, 或者相应时间太长, 会自动进行扩容
只需要告诉 k8s 要做什么 (比如保持某个 pod 有三个副本), 而不必告诉它怎么做, 就像 sql 只告诉 数据库要查询那些数据, 而没有告诉数据库怎么查数据
Kubernetes就是一个“数据库”(数据实际持久存储在etcd中);
其API就是“sql语句”;
API设计采用基于resource的Restful风格, resource type是API的端点(endpoint);
每一类resource(即Resource Type)是一张“表”,Resource Type的spec对应“表结构”信息(schema);
每张“表”里的一行记录就是一个resource,即该表对应的Resource Type的一个实例(instance);
Kubernetes这个“数据库”内置了很多“表”,比如Pod、Deployment、DaemonSet、ReplicaSet等;
4.2. 为什么使用:
当 container 太多, 需要管理, 单机情况下, 还能依靠 docker-compose 这些工具, 当有很多机器时, 就必须通过 k8s 来将 容器合理地分配到这些机器中去
- 服务发现和负载均衡
- 自动部署 and 回滚
- 替换失败容器 (自我修复)
4.3. compare with spring cloud
Spring Cloud 通过整合Neflix相关开源组件实现了一套完整的微服务方案,但是必须借助于K8S这样的容器编排工具才能实现理想的效果。而K8S却可以自成体系构建微服务系统
k8s 对构建的应用无侵入性,有更低的改造成本。
对开发语言无要求,Go、nodeJS、Java、PHP都是可以的。
程序的版本管理更加灵活,不受制与Spring Cloud的版本。
Spring Cloud 体系的程序如果部署在K8S的环境, 很多微服务特性都是重复的
5. 搭建环境
5.1. 本地环境
sealos + orbstack 搭建本地环境
腾讯云竞价实例,最低配 2h2g 1 小时 3 分钱,选南京三区的
kubesphere 官网有提供免费白嫖 10 小时
5.2. 生产服务器上安装
https://github.com/eip-work/kuboard-spray 离线安装, 基于 web 界面
https://github.com/labring/sealos 一键安装基于 k8s 的云操作系统
https://github.com/TimeBye/kubeadm-ha 基于二进制安装 k8s
https://github.com/lework/kainstall
https://github.com/easzlab/kubeasz 使用Ansible脚本安装K8S集群
5.3. vagrant 搭建 k8s 环境
一个 master node: docker, kubeadm, kubelet, kubectl 两个 worker node:
Vagrantfile:
Vagrant.configure("2") do |config|
(1..3).each do |i|
config.vm.define "k8s-node#{i}" do |node|
# 设置虚拟机的Box
node.vm.box = "centos7"
# 设置虚拟机的主机名
node.vm.hostname="k8s-node#{i}"
# 设置虚拟机的IP
# 192.168.56.xxx 需要在 virtualbox 先创建 host only network 192.168.56.1
node.vm.network "private_network", ip: "192.168.56.#{99+i}/24", netmask: "255.255.255.0"
# 设置主机与虚拟机的共享目录
# node.vm.synced_folder "~/Documents/vagrant/share", "/home/vagrant/share"
# VirtaulBox相关配置
node.vm.provider "virtualbox" do |v|
# 设置虚拟机的名称
v.name = "k8s-node#{i}"
# 设置虚拟机的内存大小
v.memory = 4096
# 设置虚拟机的CPU个数
v.cpus = 4
end
end
end
end
虚拟机准备
# 登录 machine sshd, 保证可以通过账号密码登录 (默认仅仅 ssh 登录)
# 若使用 tmux + ssh config 则无需无需这一步, 直接通过 ssh 登录即可
vagrant ssh k8s-node1
sudo su
vi /etc/ssh/sshd_config # 修改 为 PasswordAuthentication yes
service sshd restart
# 设置默认网卡
# show default SoftEther
# We can find that the default soft ether is eth0, the three machine have the same eth0 ip.
# This is because eth0 default to 网络地址转发(nat) 类型. in order to make the machines can
# access to each other, etho should be type: Natnetwork
ip route show
# 操作 virtualbox 图形界面, 全局新建 natnetwork 网络. 为每个 machine 默认网卡1 即 eth0 指定 这个类型, 刷新高级设置
# 里的 网卡mac 地址
# 然后在各个 machine 内 互相 ping 是否通
# close firewall
systemctl stop firewalld
systemctl disable firewalld
# disable selinux (永久)
sed -i 's/enforcing/disabled/' /etc/selinux/config # 替换了 enforcing 为 disable
# 当前会话关闭 selinux (临时)
setenforce 0
# 关闭 swap 永久
sed -ri 's/.*swap.*/#&/' /etc/fstab # 其实就是注释掉一行 #/swapfile none swap defaults 0 0
# 关闭 swap (内存交换) 临时
swapoff -a
# 添加 主机名 and ip 映射
# hostname 会显示 主机名 k8s-node1/2/3
# 若 hostname 显示不正常可以修改: hostnamectl set-hostname <new hostname>
vi /etc/hosts
# eth0 网卡就是 默认网卡, 用来machine 互联的
# <node1 eth0 ip> k8s-node1
# <node2 eth0 ip> k8s-node2
# <node3 eth0 ip> k8s-node3
10.0.2.15 k8s-node1
10.0.2.4 k8s-node2
10.0.2.5 k8s-node3
# 将桥接的 ipv4 的流量传递到 iptables 的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# 验证
sysctl --system
# 同步三台机器的时间
yum install ntpdate -y
ntpdate time.windows.com
# 将只读文件系统 改为 读写
mount -o remount rw /
安装 docker 等
# docker参照官网即可
# 安装 k8s 需要 aliyun 镜像 推荐
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
# ustc 的镜像
cat <<EOF > /etc/apt/sources.list.d/kubernetes.list
deb http://mirrors.ustc.edu.cn/kubernetes/apt kubernetes-xenial main
EOF
# centos
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
deb http://mirrors.ustc.edu.cn/kubernetes/apt kubernetes-xenial main
EOF
systemctl enable kubelet
systemctl start kubelet
# >>> 在 master node 上
# 需要拉去 k8s 相关的镜像, 默认仓库 k8s.gcr.io 背墙, 这里重新指定
# service-cidr 是 service 间通信的网段/子网
# pod network-cidr 是 pod 间通信网段/子网
kubeadm init --apiserver-advertise-address=<master node eth0 ip> \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--kubernetes-version v1.19.4 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=10.244.0.0/16
# 按照 输出提示, 如下步骤需要做:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# master 生成的 命令, 在 worker node 执行即可加入 cluster.
# 2h 内有效
kubeadm join 10.0.2.15:6443 --token 0tpws3.y1uhbzg0rgal4okz \
--discovery-token-ca-cert-hash sha256:0a25a082e0babbc18d1646ebfa9954d82838fa86ec66ee3d88c0d57fc9c0f35e
# 过期之后, 如下生成永久的 token
kubeadm token create --print-join-command
kubeadm token create --ttl 0 --print-join-command # 复制生成的 token 到上面命令即可
# 创建网络
# 这里选定 flannel 提供的网络扩展插件 (addons)
# 具体有哪些可用的插件: https://kubernetes.io/docs/concepts/cluster-administration/addons/
curl -L https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml -o flannel_network.yml
# 上传到 master node
scp ~/flanel.yml root@xxx/root
# 子节点加入到 cluster 后, master 会同步 flanel 相关的 pod 到 子节点上, 可以监控, 等待一段时间再查看 nodes
kubectl apply -f flannel.yml
# 查看 flanel 相关 的 pods 是否启动
kubectl get po --all-namespaces
# 如果是 失败的, 那么小替换 flanel.yml 中 image 相关地址, 到 docker hub 上找, 如 https://hub.docker.com/r/easzlab/flannel
# 删除 , 重新创建
kubectl delete -f flannel.yml
# 此时可以在子节点上执行添加 node 命令了 >>> 在 worker node 上
# 监控 所有节点上的 指定ns 的 pod
# 等待 所有节点 上 flanel 相关的 pod 都正常启动后再在 master 上查看 nodes 状态, 保证所有 node 状态为 ready 则 cluster 搭建成功
watch kubectl get po -n kube-system -o wide
# 安装 ingress controller,
# 有多重实现, 选择一种即可 https://kubernetes.io/docs/concepts/services-networking/ingress-controllers/
# 这里选择 ingress-nginx https://kubernetes.io/docs/concepts/services-networking/ingress/
# ref: https://www.cnblogs.com/minseo/p/12455320.html
5.4. 众多的发行版
5.4.1. k3s
https://github.com/k3s-io/k3s https://rancher.com/docs/k3s/latest/en/ 官网 https://www.rancher.cn/k3s/ 中文官网
https://oldj.net/article/2022/04/17/install-k3s-and-rancher/
轻量级的 k8s, 内核机制还是和 K8s 一样,但是剔除了很多外部依赖以及 K8s 的 alpha、beta 特性
将其应用于 IoT 设备(比如树莓派), CI, development 是非常好的选择
5.4.1.1. multipass + auatok3s
setup a k3s env by using autok3s and multipass under mac
https://yifei.me/note/2947 multipass + autok3s https://www.cnblogs.com/dagger9527/p/17084343.html 使用国内镜像
# create three node
multipass launch -n node-1 -c 1 -d 10G -m 1G
multipass launch -n node-2 -c 1 -d 10G -m 1G
multipass launch -n node-3 -c 1 -d 10G -m 1G
# mount local file system to instances
multipass mount $HOME node-1:/home/ubuntu/Home
multipass mount $HOME node-2:/home/ubuntu/Home
multipass mount $HOME node-3:/home/ubuntu/Home
# 为了方便,把宿主机默认的 ssh key 复制过去
# 在每个虚拟机中都执行
cat Home/.ssh/id_rsa.pub >> .ssh/authorized_keys
multipass ls # 查看 ip
ssh ubuntu@192.168.205.3 # 测试 免密码登录, 每个 node 都试一下
# 通过 arkade 安装 auto3s
# Arkade 是一个 kubernetes 相关工具的快捷安装包
brew install arkade
arkade get autok3s # 从 Github 安装, 如果m1芯片, 会失败, 考虑手动从 github下载m1 版本的 autok3s
# 如果还不行, 只能从脚本安装 autok3s 了
curl -sS https://rancher-mirror.rancher.cn/autok3s/install.sh | INSTALL_AUTOK3S_MIRROR=cn sh
# 开始创建集群,集群名为 mbp
# native provider 指的是使用普通的 Linux 节点,因为 autok3s 还支持众多云厂商。
# --name:集群名称
# --ssh-user:ssh登录服务器时的用户名,(3台节点用户名要一致)
# --ssh-key-path:ssh登录密钥
# --master-ips:master节点ip
# --worker-ips:从节点ip
# --k3s-install-script 不要从默认的 Github 上下载安装脚本, 使用指定脚本
#--k3s-install-mirror 指定使用的 mirror 镜像源名字
autok3s -d create \
--provider native \
--name mbp \
--ssh-user ubuntu \
--ssh-key-path $HOME/.ssh/id_rsa \
--master-ips 192.168.205.9 \
--worker-ips 192.168.205.7,192.168.205.6 \
--k3s-install-script https://rancher-mirror.oss-cn-beijing.aliyuncs.com/k3s/k3s-install.sh \
--k3s-install-mirror INSTALL_K3S_MIRROR=cn
# 万一中途因为网络或者 ssh 配置错误等原因失败了,可以删掉有问题的集群重来
autok3s list
# 卸载集群
autok3s -d delete --provider native --name mbp
# 如果还有没清理干净的残留,可以登录到虚拟机上使用 k3s-uninstall 脚本继续清理
# 按照日志提示, 切换到新建的集群
autok3s kubectl config use-context mbp
# 现在可以使用了
autok3s kubectl get pods -A
# 安装后的 kubeconfig 文件默认在 ~/.autok3s/.kube/config 中,复制出来可以即可直接使用 kubectl
mkdir -p ~/.kube
cp ~/.autok3s/.kube/config ~/.kube/config
kubectl get pods -A
# 使用 arkade 安装 portainer 管理面板
arkade install portainer
kubectl port-forward -n default svc/portainer 9000:9000
# 打开 localhost:9000 就可以看到 portainer 的界面啦~
# 安装 kuboard
autok3s kubectl apply -f https://addons.kuboard.cn/kuboard/kuboard-v3.yaml
# 查看是否就绪, 查看 ip
kubectl get pods -n kuboard -o wide
# 访问 : http:// 192.168.205.3:30080
5.4.1.2. k3d
https://github.com/k3d-io/k3d 将 k3s 跑在 docker 里
https://cloud.tencent.com/developer/article/1791688 原理教程
For macOs, we can just download the binary file from github release page or by using brew install k3d
5.4.1.2.1. 使用 helmChart controller
Helm Controller 定义了一个新的HelmChart自定义资源, 部署到 kubernetes 中, 用于管理 Helm 图表。
用于简化 helm 命令行的使用, 类比 docker 命令行之于 docker-compose
Helm Controller实际上就是一个CRD Controller,管理的是HelmChart类型的CRD API
Helm是 Kubernetes 的包管理器, Helm 由客户端 (helm) 和服务器端组件Tiller组成,用于管理 Helm 图表的部署和生命周期。在 k3s 中,Tiller 被替换为Helm Controller;
Helm v3 中,Tiller 被移除了, 新的 Helm 客户端会像 kubectl 命令一样,读取本地的 kubeconfig 文件,使用我们在 kubeconfig 中预先定义好的SA权限来进行一系列操作。这样做法即简单,又安全。
HelmChart部署应用,有以下好处:
1、HelmChart把Helm的操作变成对CRD API的管理,当需要对应用进行修改时,只需修改HelmChart相关属性即可,Helm-controller会主动监听API对象是否发生变化;
2、省去在宿主机上安装helm的步骤;
---
apiVersion: helm.cattle.io/v1
kind: HelmChart
metadata: # Kubernetes object metadata
name: # Chart name (required)
# 对于 k3s,这必须是kube-system,因为 Helm Controller 仅配置为监视此命名空间以获取新的 HelmChart 资源。
namespace: kube-system # Namespace Helm Controller is monitoring to deploy charts (required)
spec: # resource specification
chart: test-helmchart # char name / url
targetNamespace: test-namespace # which ns will be used to install the chart
version: 0.0.1 # chart version
repo: https://example.com/helm-charts # chart repo url
# 要提供给 Helm 的配置值的字典/映射。键应指定为字符串。值可以是整数或字符串。
# 如果需要更复杂的值,请使用valuesContent
set:
key1: "value1"
key2: "value2"
valuesContent: |-
config:
application:
admin_username: admin
admin_password: insecure_password
server:
port: 8080
tls_enabled: false
相应的命令行:
$ helm install test-helmchart --namespace test-namespace \
--version 0.0.1 \
--repo https://example.com/helm-charts \
--set-string key1=value1 \
--set-string key2=value2 \
# values.yaml 包含valuesContent字段下的内容
--values values.yaml
安装: k3s kubectl apply --filename node-red-helmchart.yaml, 或者将资源定义复制到服务器的manifest目录 /var/lib/rancher/k3s/server/manifests/ (Helm Controller 不断监视此目录中的新 CRD。当它检测到添加了新资源时,它将自动部署图表)
更新: 修改 yml 文件后, 再次执行 kubectl apply --filename node-red-helmchart.yaml
删除: kubectl --namespace kube-system delete helmchart <char name, eg. node-red>
5.4.1.2.2. 操作 kubeconfig
# 获取 kubeconfig 文件 (最新版k3d 会自动更新 ~/.kube/config, 我们无需手动修改 kubectl 即可操作k3d 创建的集群)
k3d kubeconfig get --all
5.4.1.2.3. 支持的命令
k3d version
# 默认值创建一个单节点集群
k3d cluster create [--servers 2 ...]
# delete the default cluster or the specified cluster
k3d cluster delete [mycluster]
kubectl cluster-info # 检查是否启动完成
kubectl get all --all-namespaces [--output wide] # 检查内部结构, 发现 K3s还部署了DNS、metrics和ingress(traefik)服务
kubectl get nodes --output wide # 仅看到了一个节点, k3d node list 发现有两个节点, 有另一个“节点”作为负载均衡器
# 可以看到几个比较常用见的组件
# local-path-provisioner: 这个提供本地存储pv动态创建
# metrics-server: 用于pod metrics的收集
# traefik: 这个用于请求转发
# coredns: 集群域名解析
# (其它的如Kube-proxy, kube-scheduler是没有,这个可以理解,用k3d创建出来的集群不管多少个agent,本质上还是一台实体机)
kubectl get pod --all-namespaces
# 都默认创建了一个 1个负载均衡器容器
k3d cluster create two-node-cluster --agents 2 [-image rancher/k3s:v1.19.3-k3s2]
k3d cluster create three-node-cluster --server 3
# 通过--api-port 127.0.0.1:6445,您可以使用k3d将Kubernetes API端口(6443内部)映射到127.0.0.1 / localhost的端口6445
# --volume /home/me/mycode:/code@agent[*]绑定将你的本地目录/home/me/mycode挂载到所有([*] agent 节点)内部的路径/code。使用索引(0或1)替换*,以便只把它挂载到其中一个节点。
k3d cluster create mycluster --api-port 127.0.0.1:6445 --servers 3 --agents 2 --volume '/home/me/mycode:/code@agent[*/0/1/2/3....]' --port '8080:80@loadbalancer'
k3d cluster create mycluster \
--api-port 127.0.0.1:6443 \
-p 80:80@loadbalancer \ # 在宿主机的 80, 443 端口访问 ingress 资源。
-p 443:443@loadbalancer \
-i rancher/k3s:v1.18.6-k3s1 \
--volume "${HOME}/registries.yaml:/etc/rancher/k3s/registries.yaml" \ # 配置国内镜像加速
--k3s-server-arg "--no-deploy=traefik" # 禁用默认的 Traefik
# registries.yaml 内容
mirrors:
"docker.io":
endpoint:
- "https://fogjl973.mirror.aliyuncs.com"
- "https://docker.mirrors.ustc.edu.cn"
- "https://registry-1.docker.io"
# 切换集群
kubectl config use-context k3d-two-node-cluster
# crate node and insert into current cluster
k3d node create <prefix name> --role server [--image ...]
k3d node list
k3d registry list
5.4.1.2.4. 国内镜像
k3d cluster create mycluster \
--api-port 127.0.0.1:6443 \
-p 80:80@loadbalancer \ # 在宿主机的 80, 443 端口访问 ingress 资源。
-p 443:443@loadbalancer \
-i rancher/k3s:v1.18.6-k3s1 \
--volume "${HOME}/registries.yaml:/etc/rancher/k3s/registries.yaml" \ # 配置国内镜像加速
--k3s-server-arg "--no-deploy=traefik" # 禁用默认的 Traefik
# registries.yaml 内容
mirrors:
"docker.io":
endpoint:
- "https://fogjl973.mirror.aliyuncs.com"
- "https://docker.mirrors.ustc.edu.cn"
- "https://registry-1.docker.io"
5.4.1.2.5. 导入镜像
# k3d 中的镜像和 docker 不通, 需要手动导入
# 编写 deployment 时注明 imagePullPolicy: Never 从不拉取, 仅仅使用k3d 内部镜像
k3d image import <customized image name>
或者自己搭建 image registry
5.4.1.2.6. k3s 包括以下一些组件
Containerd:一个类似 Docker 的运行时容器,但是它不支持构建镜像;
Flannel:基于 CNI 实现的网络模型,默认使用的是 Flannel,也可以使用 Calico 等其他实现替换;
CoreDNS:集群内部 DNS 组件;
SQLite3:默认使用 SQLite3 进行存储,同样也支持 etcd3, MySQL, Postgres;
Traefik:默认安装 Ingress controller 是 traefik 1.x 的版本;
Embedded service loadbalancer:内嵌的一个服务负载均衡组件。
5.4.1.2.7. 完整的 k3d yml 配置文件
or taking a yaml file to create cluster:
apiVersion: k3d.io/v1alpha2
kind: Simple
name: mycluster
servers: 1
agents: 2
kubeAPI:
# 可通过 localhost:6443 访问 控制平面的 api
hostPort: "6443" # same as `--api-port '6443'`
# 向主机暴露的端口
ports:
# 将本地主机的端口8080映射到负载均衡器(serverlb)上的端口80
# 即: 可通过 8080 访问集群内部 80
- port: 8080:80 # same as `--port '8080:80@loadbalancer'`
# 指定应用的哪些节点, loadbalancer 是节点角色名称
# 如果内部Service 是 NodePort 类型 (通过节点暴露出去), 那这里的端口映射应该限制只作用于 loadbalancer 节点
# 如果内部Service 通过 ingress 暴露, 那这里无需指定 nodeFilter
nodeFilters:
- loadbalancer
- port: 8443:443 # same as `--port '8443:443@loadbalancer'`
nodeFilters:
- loadbalancer
=================
apiVersion: k3d.io/v1alpha4
kind: Simple
metadata:
name: k3s-default
servers: 1 # same as `--servers 1`
agents: 2 # same as `--agents 2`
image: docker.io/rancher/k3s:v1.25.6-k3s1
kubeAPI: # same as `--api-port myhost.my.domain:6445` (where the name would resolve to 127.0.0.1)
host: '127.0.0.1' # important for the `server` setting in the kubeconfig
# hostIP: "192.168.1.200" # where the Kubernetes API will be listening on
hostPort: '6445' # where the Kubernetes API listening port will be mapped to on your host system
ports:
- port: 80:80 # same as `--port '8080:80@loadbalancer'`
nodeFilters:
- loadbalancer
options:
k3d: # k3d runtime settings
wait: true # wait for cluster to be usable before returining; same as `--wait` (default: true)
timeout: '60s' # wait timeout before aborting; same as `--timeout 60s`
disableLoadbalancer: false # same as `--no-lb`
disableImageVolume: false # same as `--no-image-volume`
disableRollback: false # same as `--no-Rollback`
loadbalancer:
configOverrides:
- settings.workerConnections=2048
k3s: # options passed on to K3s itself
extraArgs: # additional arguments passed to the `k3s server|agent` command; same as `--k3s-arg`
- arg: '--tls-san=127.0.0.1 --tls-san=ks.newbe.io'
nodeFilters:
- server:*
kubeconfig:
updateDefaultKubeconfig: true # add new cluster to your default Kubeconfig; same as `--kubeconfig-update-default` (default: true)
switchCurrentContext: true # also set current-context to the new cluster's context; same as `--kubeconfig-switch-context` (default: true)
registries: # define how registries should be created or used
config:
| # define contents of the `registries.yaml` file (or reference a file); same as `--registry-config /path/to/config.yaml`
mirrors:
"docker.io":
endpoint:
- "https://mirror.ccs.tencentyun.com"
k3d cluster create --config /path/to/mycluster.yaml
5.4.1.2.8. 部署一个 NGINX
https://blog.bwcxtech.com/posts/ea0ef82f/ 使用 Traefik2 代替 1
now write a k3d-cluster.yml
apiVersion: k3d.io/v1alpha4
kind: Simple
metadata:
name: cluster-3
servers: 1
agents: 2
kubeAPI:
hostPort: "6443"
ports:
- port: 8087:30080
nodeFilters:
- loadbalancer
- port: 8443:443
nodeFilters:
- loadbalancer
k3d cluster create --config /path/to/cluster.yml
now let's create the simplest nginx deployment and service:
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-deployment
labels:
app: web-deployment
spec:
selector:
matchLabels:
app: web-pod
template:
metadata:
labels:
app: web-pod
spec:
containers:
- name: web-container
image: nginx
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: web-service
labels:
app: web-service
spec:
selector:
app: web-pod
type: NodePort
ports:
- port: 80
targetPort: 80
check the following picture to get a further understanding
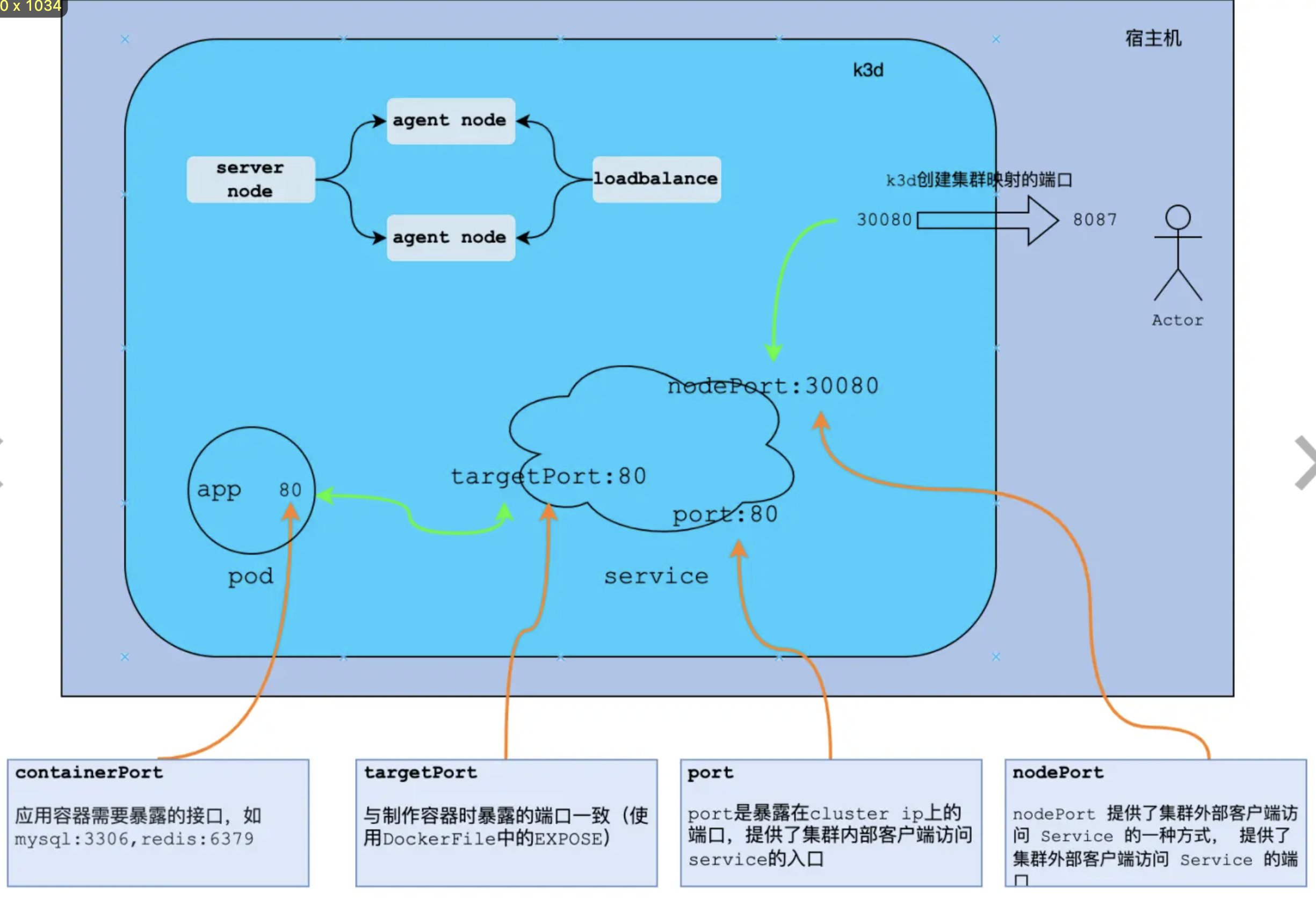
kc get pods,services -o wide to check if the resources ready, and we can check http://localhost:8087/ for the nginx welcome page
now try to bring in the Ingress resource: k3d cluster delete cluster-3, and update the service section in the yml:
# Service type is set up to clusterIP (default)
# we can expose this service by using ingress
apiVersion: v1
kind: Service
metadata:
name: web-service
labels:
app: web-service
spec:
selector:
app: web-pod
ports:
- port: 80
targetPort: 80
ingress:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: web-ingress
labels:
name: web-ingress
spec:
rules:
# 即使用哪一个域名来访问service
- host: localhost
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: web-service
port:
number: 80
the cluster yml file also need some updates:
apiVersion: k3d.io/v1alpha4
kind: Simple
metadata:
name: cluster-3
servers: 1
agents: 2
kubeAPI:
hostPort: "6443"
ports:
# ingress默认端口是80, 将其映射到宿主机的 9001
# 不要添加 nodeFilters:
# - loadbalancer
- port: 9001:80
http://localhost:9001/ To check the nginx welcome page
5.4.2. k0s
https://github.com/k0sproject/k0s 体积下, 更精简的 k8s
5.4.3. microk8s
https://github.com/canonical/microk8s
5.4.4. docker desktop (推荐使用 rancher desktop 替代)
it's the easiest way to install k8s locally I think.
5.4.5. kind (推荐使用 k3d 代替)
https://guoxudong.io/post/k3d-vs-kind/ 对比
https://github.com/kubernetes-sigs/kind/
在 docker 中运行 k8s, 更快更方便
https://www.cnblogs.com/laochiji/p/13813743.html 多节点
# install
# install golang && install docker
docker pull kindest/node:v1.19.1
# --name: specify a name for the cluster. default name : kind
# --wait 30s: wait until the cluster reaches a ready status
# --wait 5m
# --kubeconfig: specify cluster config file; default location : ${HOME}/.kube/config
kind create cluster [--name kind] [--wait]
# 构建镜像
docker build -t my-custom-image:unique-tag ./my-image-dir
# 加载到 kind
kind load docker-image my-custom-image:unique-tag
kubectl apply -f my-manifest-using-my-image:unique-tag
# context name 规则: <kind>-<cluster_name>
# 仅仅一个 cluster 时, 可省略 context
kubectl cluster-info [--context kind-kind]
# 默认删除 kind 名字的 cluster
kind delete cluster [--name kind]
# 加载 images 到 cluster
# 默认 将 镜像加载到 kind 名字的 cluster
kind load docker-image <img_name> [--name cluster_name]
# 进入 kind 启动的 docker 内部, 执行 crictl images, 可以看
# 到用来模拟 k8s 的一系列镜像
docker exec -it kind-control-plane crictl images
5.4.6. minikube
create single node k8s cluster for dev, 原理是 创建虚拟机,
minikube version
minikube start
minikube dashboard
# 可用的扩展/插件
minikube addons list
# 开启插件
minikube addons enable metrics-server
# 关闭插件
minikube addons disable metrics-server
minikube stop
minikube delete
# 当前 node ip
minikube ip
6. Quickstart
6.1. 以Java 为例
https://mritd.com/2022/11/08/java-containerization-guide/
6.2. 以 go 为例
6.2.1. using pod directly
here is a piece of code in go:
package main
import (
"io"
"net/http"
)
func main() {
// Register a router
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
io.WriteString(w, "[v1] Hello, k8s!")
})
// Start the server and listening on port 80
http.ListenAndServe(":80", nil)
}
now we write a dockerfile for this go app
FROM golang:1.20 AS builder
# create /src, then jump into it
WORKDIR /src
# pre-copy/cache go.mod for pre-downloading dependencies and only redownloading them in subsequent builds if they change
# COPY go.mod go.sum ./
# RUN go mod download && go mod verify
# copy all host files to /src
COPY . ./
# required, if missing then go.mod is needed
RUN go env -w GO111MODULE=auto
RUN CGO_ENABLED=0 go build -a -sw -ldflags '-extldflags "-static"' -v -o main .
# ---
FROM scratch
WORKDIR /
COPY --from=builder /src/main .
EXPOSE 80
ENTRYPOINT ["/main"]
so now we can build our image and push it to docker hub:
go build . -t xiaoyureed/hellok8s:v1
# check
docker images | grep xiaoyureed
# login docker hub
docker login
docker push
then write the pod resource yml:
apiVersion: v1
kind: Pod
metadata:
name: hello-k8s-pod
labels:
name: hello-k8s
spec:
containers:
- image: xiaoyureed/hellok8s:v1
name: hello-k8s-container
# optional
resources:
limits:
memory: '128Mi'
cpu: '500m'
apply the yml to create pod
kubectl apply -f xxx.yaml
# Wait for about 30s,
# so that the resources can be created
# check pod list
kubectl get pods
# check pod info
kc describe pod <pod name>
# post forwarding (Temporary use only, just for debugging)
kubectl port-forward hello-k8s-pod 4000:80
# enter the container in the pod
kubectl exec -it hello-k8s-pod -- /bin/bash
# echo "hello kubernetes by nginx!" > /usr/share/nginx/html/index.html
# visit localhost:4000
# check log 跟踪日志文件, 类似 tail -f
kubectl logs --follow hello-k8s-pod
# exec cmd "ls"
kubectl exec hello-k8s-pod -- ls
# delete resources
kubectl delete pod hello-k8s-pod
# or
kubectl delete -f xxx.yaml
Another example by using nginx:
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
labels:
name: nginx-pod
spec:
containers:
- name: nginx-container
image: nginx
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 80
then
# 80:80 may produce error since permission denied
kc port-forward ngixn-pod 8000:80
kc logs --follow nginx-pod
# now we can check localhost:8000
6.2.2. using deployment
Let's write a yml file to define a deployment to manage the pods
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-k8s-deployment
spec:
replicas: 3
selector:
matchLabels:
app: hello-k8s
template:
metadata:
labels:
app: hello-k8s
spec:
containers:
- name: hello-k8s-container
image: xiaoyureed/hellok8s:v1
resources:
limits:
memory: "128Mi"
cpu: "500m"
then apply and check the results:
# create
kc apply -f k8s_resources/deployment.yml
# check deployment info
kc get deployments
# check pods info
# Note: the pods name is generated by deployment and it's unique
kc get pods
# Try to delete a pod, and then you will find that the pod number recovers after a moment
kc delete pod hello-k8s-deployment-6bb465758-5d8lk
operator
https://tonybai.com/2022/08/15/developing-kubernetes-operators-in-go-part1/
7. 集群结构 underlying infrastructure 基础设施
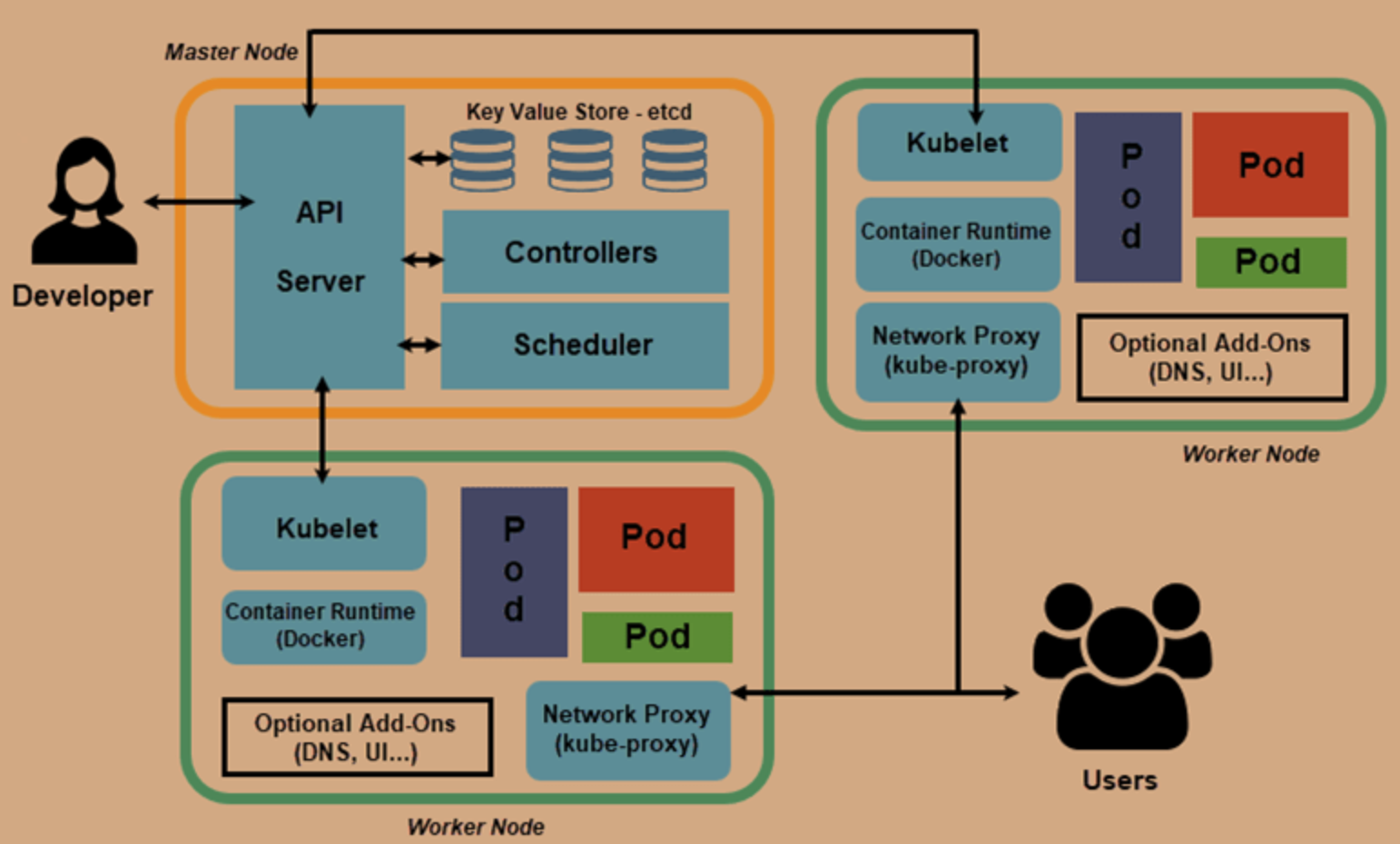
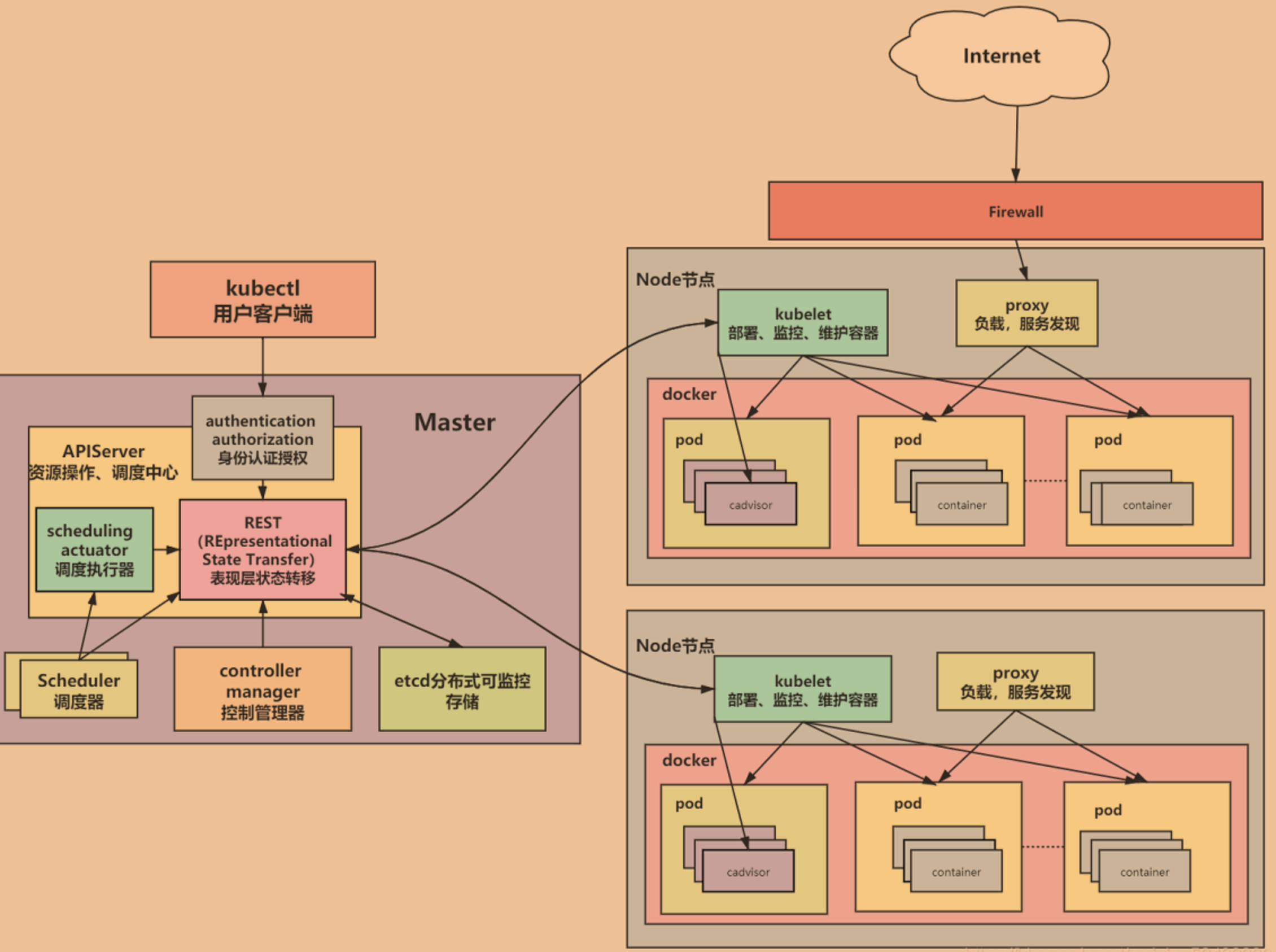
控制平面(control plane): Also known as "master" node, designed to manage the hole cluster to make it work properly
配置存储中心: ETCd
distributed data storage; used to store the cluster status
api server
Provide the api interface to interactive with the developer.
scheduler
调度, 决定哪个 pod 部署到哪个节点;
control manager
整个集群的管家,用来管理资源对象: 如 复制节点, 持续跟踪工作节点
- node controller 在节点出现故障时进行通知和响应
- Replication Controller 维护正确数量的 Pod
- Endpoints Controller 填充端点(Endpoints)对象(即加入 Service 与 Pod)
computer machines (计算节点 Node): Also known as Node, designed to run the real application; 是所有 Pod 运行所在的工作主机,可以是物理机也可以是虚拟机
kubelet: 相当于节点的代理, 和 master 节点交互
和 master 节点的 api server 通信, 以管理所在的 节点/机器上的 pod (创建、修改、监控、删除)
kube-proxy: 负责一组 pods 的负载均衡
是 K8s 集群内部的负载均衡器。它是一个分布式代理服务器, 在 K8s 的每个节点上都有一个;这一设计体现了它的伸缩性优势,需要访问服务的节点越多,提供负载均衡能力的 Kube-proxy 就越多,高可用节点也随之增多。与之相比,我们平时在服务器端做个反向代理做负载均衡,还要进一步解决反向代理的负载均衡和高可用问题。
Fluentd,主要负责日志收集、存储与查询
container runtime engine (需要符合 oci 标准的运行时, 如 docker, containerd, rkt, CRI-O): 负责创建容器
核心附件:
cni 网络插件: flannel/calico
服务发现插件: coredns
服务暴露插件: nginx-ingress/traefik-ingress
gui 管理插件: dashboard
8. 管理的各种资源
即各种 api object,
像 pod, rc, rs, deployment 都属于 api object
8.1. 各种资源的关系
在 K8S 中,应用会被封装在 Container 中暴露出来一个 Port. 一个和多个 Container 组成了一个 Pod。 Pod 是 K8S 的基本执行单元。Pod 会被分配到 Node 上运行。而多个 Node 组成了一个 K8S Cluster.
8.2. 3 common properties
8.2.1. metadata
metadata (contains 3 factors at least):
namespace 命名空间为 Kubernetes 集群提供虚拟的隔离作用
Kubernetes 集群初始有两个命名空间,分别是默认命名空间 default 和系统命名空间 kube-system
name
uid
used to identify api obj
8.2.2. spec
used to declare the configuration that we want
8.2.3. status
8.3. node
是 K8S 的集群工作节点,可以是物理机也可以是虚拟机;
# check node info
kubectl describe node <NODENAME>
# 禁止Pod调度到该节点上
kubectl corndon NODENAME
# 驱逐该节点上的所有 Pod
kubectl drain NODENAME
8.4. pod
由 一个或多个相互关联的 container 组成, 这些 container 共享网络地址和文件系统, 是 k8s 管理的基本单位, 代表着集群中的一个虚拟主机
一个 pod 只可能存在于一个 worker node 上, 不可跨节点, 一组 pod 可以分布在不同 node 上
一个 pod 内的所有容器共享相同的 Linux network 命名空间. 这样每个 pod 就像一台独立的 主机, 有自己的 ip (集群内部地址), 主机名, 端口 (pod 中的 containers 共享 该 ip 以及 端口空间, 具有相同的 loopback 网络接口,可使用 localhost 相互通信).
(可以和 docker-compose 启动的多个 container 类比)
container (容器) 的本质是进程,而 pod 是管理这一组进程的资源
Here is the yml spec file for pod:
apiVersion: v1
kind: Pod
metadata:
name: hello-k8s-pod
# optional
labels:
name: hello-k8s
spec:
containers:
- name: hello-k8s-container
image: xiaoyureed/hellok8s:v1
# IfNotPresent 仅本地没有镜像时才远程拉,Always 永远都是从远程拉,Never 永远只用本地镜像,本地没有则报错
# optional
imagePullPolicy: IfNotPresent
# optional
resources:
limits:
memory: '128Mi'
cpu: '500m'
use these commands to check the pods info
# check list
kc get pod[s]
# check list, including more info
kubectl get pods -o wide
# enter a specific pod
kubectl exec -it <pod name> /bin/bash
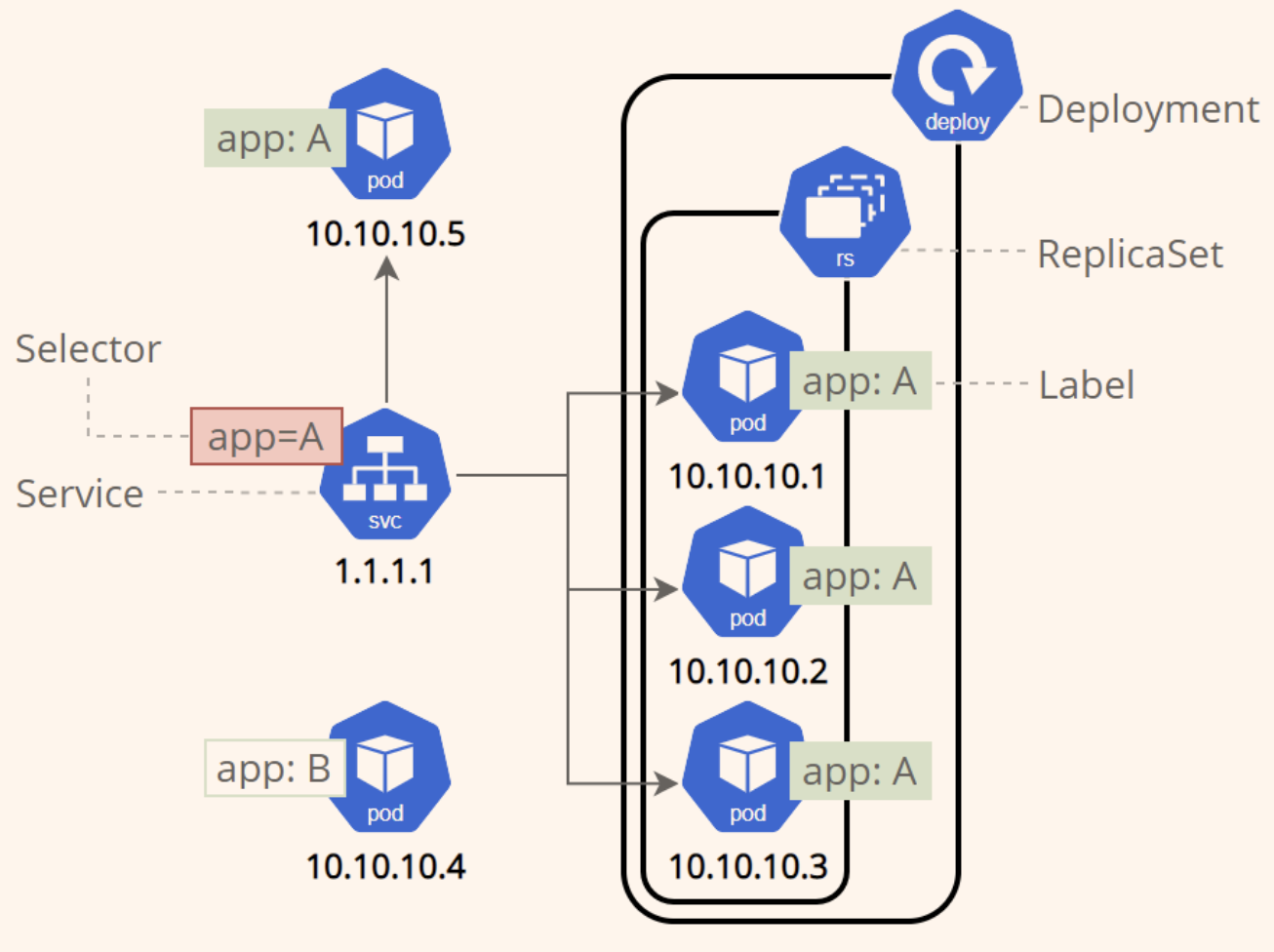
8.5. label
label 是资源上的标识,用来对它们进行区分和选择,
通常在资源对象确定时定义,也可以在资源创建后动态添加或删除;
一个 label 会以 kv 形式附加到各种对象上(node, pod, service ...)
常用 label:
版本标签:“version”:“release”,
环境标签:"environment": "dev", "environment": "qa", "environment": "production"
架构标签:"tier": "frontend" ,"tier": "backend","tier": "cache"
8.5.1. Label selector 使用
- 包含/不包含 特定 key 的 资源
- 包含特定 key, value 的 资源
- 包含 特定 key, 且 value 和指定的不同的资源
8.6. Taint(污点)和 Toleration(容忍)
可以作用于 node 和 pod 上, 用于控制和优化 pod 在 node 上的调度
具有 taint 的 node 和 pod 是互斥关系,而具有节点亲和性 (toleration) 关系的 node 和 pod 是相吸的
Taint 和 toleration 相互配合,可以用来避免 pod 被分配到不合适的节点上。每个节点上都可以应用一个或多个 taint ,这表示对于那些不能容忍这些 taint 的 pod,是不会被该节点接受的。如果将 toleration 应用于 pod 上,则表示这些 pod 可以(但不要求)被调度到具有相应 taint 的节点上。
另外还有可以给 node 设置 label,通过给 pod 设置 nodeSelector 将 pod 调度到具有匹配标签的节点上。
8.6.1. taint
作用在 node 上.
Node 被设置上污点之后,就和 Pod 之间存在了一种相斥的关系,进而拒绝 Pod 调度过来,甚至可以将已存在的 Pod 驱逐出去;
污点格式:key=value:effect,key和value是污点的标签,effect描述污点的作用,支持如下三个选项:
- PreferNoSchedule: k8s尽量不把pod调度到该污点Node上,除非没有其他节点可调度;
- NoSchedule: k8s将不会把Pod调度到该污点Node上,已存在的Pod将继续运行;
- NoExecute:k8s将不会把Pod调度到具有该污点的Node上,同时也会将Node上已存在的Pod驱逐;
使用语法:
# 设置污点
kubectl taint nodes <node name> <key>=<value>:<effect>
# 去除污点
kubectl taint nodes node1 <key>:<effect>-
# 去除所有污点
kubectl taint nodes node1 <key>-
# 例如:
# 为node1设置污点
kubectl taint nodes node1 tag=test:PreferNoSchedule
# 为node1取消污点
kubectl taint nodes node1 tag:PreferNoSchedule-
# 为node1删除去除污点
kubectl taint nodes node1 tag-
# 查看node1 污点
kubectl describe node node1
8.6.2. toleration
作用在 pod 上
若将 pod 调度到一个有污点的 node 上去,需要用到容忍; Node 通过污点拒绝 pod 调度上去,pod 通过容忍忽略拒绝;
8.7. controllers(各种控制器)
pod 控制器, 部署/管理 pods
8.7.1. RC (replica controller 副本控制器)
outdated
保证 Pod 高可用的 API 对象; 创建/复制 pod 实例, 确保 pod 副本数量 (it kill the pod or start pod to ensure that the pod number consit with the configuration)
Best practice: remember that always start pod by using RC
kubectl run ... 会创建一个 rc, 然后 rc 创建 pod (所以删除这样的 pod, 需要先删除 rc)
工作流程:寻找 符合 label selector 的 pod, 比较找到的 pod 和期望数量, 少了就从当前模板创建新的 pod 副本 , 多了, 就删除多的 pod
三个部分:
label selector: 用于确定 ReplicationController 作用域中有哪些 pod
replica count (副本个数), 指定应运行的 pod 数量
pod template (pod 模板), 用于创建新的 pod 副本
在新版的 K8s 中,建议使用 ReplicaSet 作为副本控制器,ReplicationController 不再使用了
8.7.2. RS (replica set, 代替 RC)
副本集
副本集对象一般不单独使用,而是用 Deployment 来管理。
RC 和 RS 主要是控制提供无状态服务的,其所控制的 Pod 的名字是随机设置的,一个 Pod 出故障了就被丢弃掉,在另一个地方重启一个新的 Pod,名字变了。名字和启动在哪儿都不重要,重要的只是 Pod 总数;
对于 RC 和 RS 中的 Pod,一般不挂载存储或者挂载共享存储,保存的是所有 Pod 共享的状态
8.7.3. Deployment (管理 RS)
表示用户对 Kubernetes 集群的一次更新操作。可以是创建/更新一个新的服务,也可以是滚动升级一个服务
滚动升级一个服务,实际是创建一个新的 RS,然后逐渐将新 RS 中副本数增加到理想状态,将旧 RS 中的副本数减小到 0 的复合操作
比 replica set 使用范围更广, 一般使用 deployment 来管理 replica set
Here is the yml spec file:
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-k8s-deployment
spec:
# Control the scale up/back through this filed
replicas: 1
# required, used to select pods which can be managed by this deployment
selector:
matchLabels:
app: hello-k8s
template:
# Note: no need to specify "name" in metadata since the deployment will create the unique pod name automatically
metadata:
# required, used to be selected by deployment's selector
labels:
app: hello-k8s
spec:
containers:
# required, the final container name contains this field
- name: hello-k8s-container
image: xiaoyureed/hellok8s:v1
# optional
resources:
limits:
memory: '128Mi'
cpu: '500m'
# 环境变量 可以在 springboot应用中通过 ${xxx} 使用
env:
- name: xxx
value: yyy
# optional
ports:
- containerPort: 80 # 指定 container 中应用暴露的端口, 应该保持和 dockerfile 中的 expose 一样
8.7.3.1. scale up/back (扩容缩容)
With regards to Scale up/back, we just need update the "spec.replicas" field, then rerun kubectl apply -f xxx.yml
We can use
kc get pods --watchto monitor the pod list
or we can use this cmd kubectl scale deployment test-k8s --replicas=5
8.7.3.2. version upgrade (版本升级)
When talking about the app Version Upgrade, after make the code change, just need rebuild the image (note version number should change from v1 to v2) and push to docker hub, then update the yml image field, finally exec kc apply ...
Use
kubectl describe pod xxxto check the pod details info, so that you can see the version info
8.7.3.3. rolling update (滚动升级)
像上面那样的部署方式是可以的,但是也会带来一个问题,就是所有的副本在同一时间更新,这会导致我们 hellok8s 服务在短时间内是不可用的,因为所有 pod 都在升级到 v2 版本的过程中,需要等待某个 pod 升级完成后才能提供服务
这个时候我们就需要滚动更新,在保证新版本 v2 的 pod 还没有 ready 之前,先不删除 v1 版本的 pod。
spec.strategy.type 's possible values include:
RollingUpdate: 逐渐增加新版本的 pod,逐渐减少旧版本的 pod。
(可以通过 maxSurge 和 maxUnavailable 字段来控制升级 pod 的速率)
- maxSurge: 最大峰值,用来指定可以创建的超出期望 Pod 个数的 Pod 数量。
- maxUnavailable: 最大不可用,用来指定更新过程中不可用的 Pod 的个数上限。
Recreate: 在新版本的 pod 增加前,先将所有旧版本 pod 删除。
apiVersion: apps/v1
kind: Deployment
metadata:
name: hellok8s-deployment
spec:
strategy:
# specify the upgrade type
rollingUpdate:
# 指定 pod 的最大超出个数
# 最大可能会创建 4 个 hellok8s pod (replicas + maxSurge)
maxSurge: 1
# 指定 pod 的最大不可用个数
# 最小会有 2 个 hellok8s pod 存活 (replicas - maxUnavailable)。
maxUnavailable: 1
replicas: 3
selector:
matchLabels:
app: hellok8s
template:
metadata:
labels:
app: hellok8s
spec:
containers:
- image: guangzhengli/hellok8s:v2
name: hellok8s-container
8.7.3.4. 回滚 版本回退 查看历史
# roll back to last deployment version
kubectl rollout undo deployment hellok8s-deployment
# check the history version
kubectl rollout history deployment hellok8s-deployment
# roll back to the specified version
kubectl rollout undo deployment/hellok8s-deployment --to-revision=2
8.7.3.5. livenessProbe (存活探针)
在生产中,有时候因为某些 bug 导致应用死锁或者线程耗尽了,最终会导致应用无法继续提供服务,这个时候如果没有手段来自动监控和处理这一问题的话,可能会导致很长一段时间无人发现
apiVersion: apps/v1
kind: Deployment
metadata:
name: hellok8s-deployment
spec:
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
replicas: 3
selector:
matchLabels:
app: hellok8s
template:
metadata:
labels:
app: hellok8s
spec:
containers:
- image: guangzhengli/hellok8s:liveness
name: hellok8s-container
# 如果服务器上 /healthz 路径下的处理程序返回成功代码,则 kubelet 认为容器是健康存活的。 如果处理程序返回失败代码,则 kubelet 会杀死这个容器并将其重启
livenessProbe:
# 使用 HTTP GET 请求的方式探活
httpGet:
# Specify the application route (api path)
path: /healthz
# specify the application port
port: 3000
# 告诉 kubelet 在执行第一次探测前应该等待 3 秒
# 即容器启动后要等待多少秒后才启动存活和就绪探测器
initialDelaySeconds: 3
# 执行探测的时间间隔(单位是秒)。默认是 10 秒。最小值是 1。
periodSeconds: 3
# timeoutSeconds:探测的超时后等待多少秒。默认值是 1 秒。最小值是 1。
# failureThreshold:当探测失败时,Kubernetes 的重试次数。 对存活探测而言,放弃就意味着重新启动容器。 对就绪探测而言,放弃意味着 Pod 会被打上未就绪的标签。默认值是 3。最小值是 1。
通过 kubectl get pods 查看状态 or kubectl describe pod hellok8s-68f47f657c-zwn6g 查看原因,
8.7.3.6. readinessProbe (就绪探针)
在生产环境中,升级服务的版本是日常的需求,这时我们需要考虑一种场景,即当发布的版本存在问题,就不应该让它升级成功。kubelet 使用就绪探测器可以知道容器何时准备好接受请求流量,当一个 pod 升级后不能就绪,即不应该让流量进入该 pod,在配合 rollingUpate 的功能下,也不能允许升级版本继续下去,否则服务会出现全部升级完成,导致所有服务均不可用的情况。
apiVersion: apps/v1
kind: Deployment
metadata:
name: hellok8s-deployment
spec:
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
replicas: 3
selector:
matchLabels:
app: hellok8s
template:
metadata:
labels:
app: hellok8s
spec:
containers:
- image: guangzhengli/hellok8s:bad
name: hellok8s-container
readinessProbe:
httpGet:
path: /healthz
port: 3000
# 初次探测前等待时间, 默认是 0 秒,最小值是 0
initialDelaySeconds: 1
# 被视为成功的最小连续成功数。默认值是 1。 存活和启动探测的这个值必须是 1。最小值是 1。
successThreshold: 5
8.7.4. SC (stateful set)
有状态应用部署 (如 MySQL, ZooKeeper、etcd )
StatefulSet 中的每个 Pod 的名字都是事先确定的,会被固定住
StatefulSet 中的 Pod,每个 Pod 挂载自己独立指定的存储,
如果一个 Pod 出现故障,从其他节点启动一个同样名字的 Pod,要挂载上原来 Pod 的存储继续以它的状态提供服务
使用 StatefulSet,Pod 仍然可以通过漂移到不同节点提供高可用,而存储也可以通过外挂的存储来提供高可靠性,StatefulSet 做的只是将确定的 Pod 与确定的存储关联起来保证状态的连续性。
Service 的 CLUSTER-IP 是空的
Pod 创建和销毁是有序的,创建是顺序的,销毁是逆序的
如下部署 MongoDB:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mongodb
spec:
replicas: 1
selector:
matchLabels:
app: mongodb
serviceName: mongodb
template:
metadata:
labels:
app: mongodb
spec:
containers:
- name: mongo
image: mongo:4.4
# IfNotPresent 仅本地没有镜像时才远程拉,Always 永远都是从远程拉,Never 永远只用本地镜像,本地没有则报错
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /data/db # 容器里面的挂载路径
name: mongo-data # 卷名字,必须跟下面定义的名字一致
volumes:
- name: mongo-data # 卷名字
hostPath:
# 把节点上的一个目录挂载到 Pod,但是已经不推荐使用了
path: /data/mongo-data # 节点上的路径
type: DirectoryOrCreate # 指向一个目录,不存在时自动创建
---
apiVersion: v1
kind: Service
metadata:
name: mongodb # 固定的
spec:
selector:
app: mongodb
type: ClusterIP
# HeadLess
clusterIP: None
ports:
- port: 27017
targetPort: 27017
8.7.4.1. 数据持久化 persist
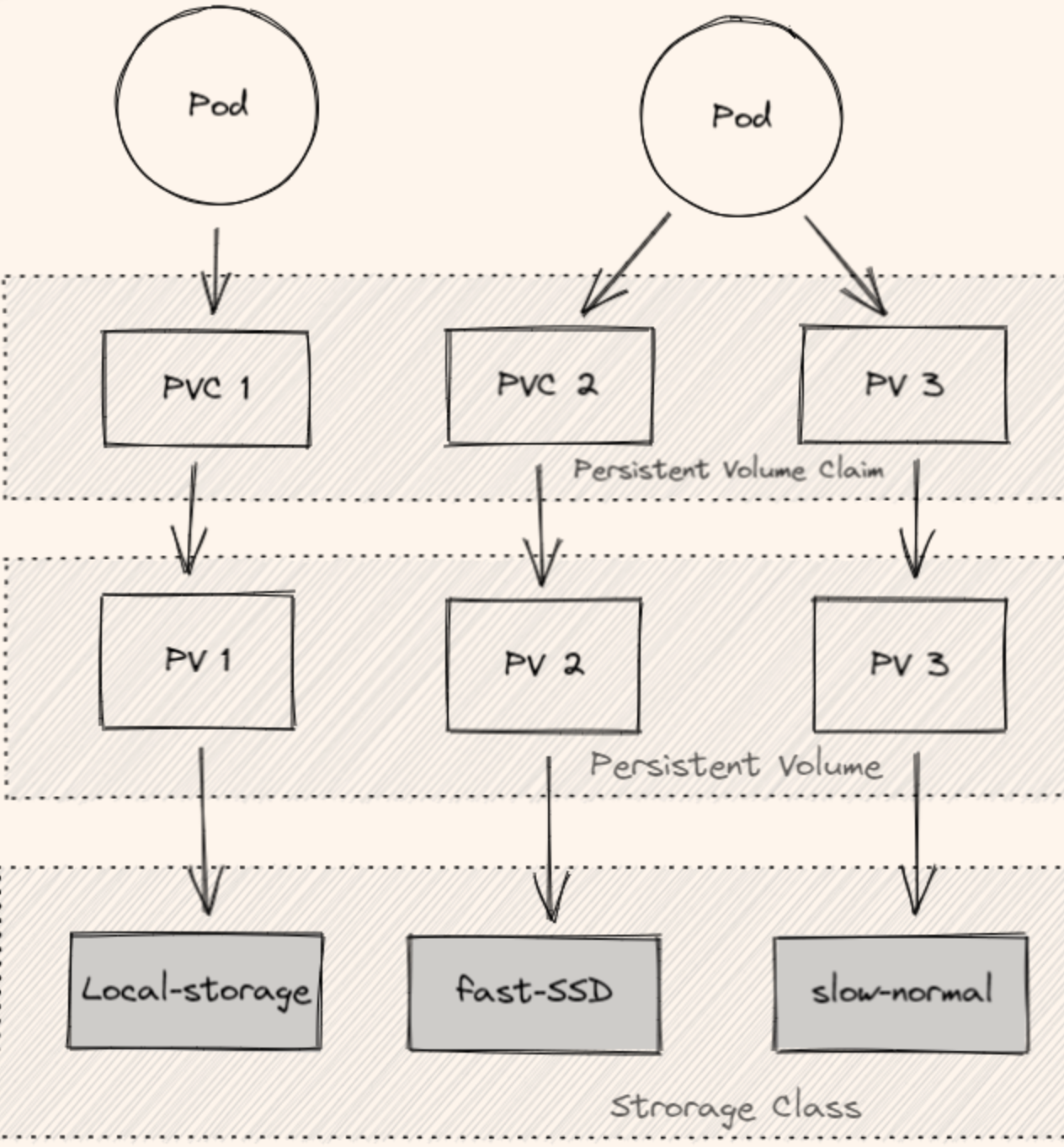
Storage Class (SC) : 将存储卷划分为不同的种类,例如:SSD,普通磁盘,本地磁盘
Persistent Volume (PV) : 描述卷的具体信息,例如磁盘大小,访问模式
Persistent Volume Claim (PVC): 对存储需求的一个申明,可以理解为一个申请单,系统根据这个申请单去找一个合适的 PV
还可以根据 PVC 自动创建 PV。
PersistemVolume(PV)用来定义存储卷,PersistemVolumeClaim(PVC)用来声明在Pod中用哪个PV。通常PV和PVC是一一对应的。但是如果每次都要去创建PV太麻烦了,所以K8S还提供了StorageClass来动态创建PV。前面的StatefulSets因为要保证Pod的状态持久化落盘,它就依赖于PV和PVC这玩意儿做持久化。
8.7.5. DS (daemon set 后台支撑服务集)
确保每个 working node 都运行一个指定 pod (working node 可能是所有集群节点也可能是通过 nodeSelector 选定的一些特定节点)
这个 pod 可能是用来专门支撑业务系统运行的基础服务, 比如对集群中的每个 working node 做日志采集,性能指标监控
8.7.6. job (一次性任务)
Job 管理的 Pod 根据用户的设置把任务成功完成就自动退出了
成功完成的标志根据不同的 spec.completions 策略而不同:
- 单 Pod 型任务有一个 Pod 成功就标志完成;
- 定数成功型任务保证有 N 个任务全部成功;
- 工作队列型任务根据应用确认的全局成功而标志成功。
Job 完成时不会再创建新的 Pod,不过已有的 Pod 通常也不会被删除
保留这些 Pod 使得你可以查看已完成的 Pod 的日志输出,以便检查错误、警告或者其它诊断性输出。 可以使用 kubectl 来删除 Job(例如 kubectl delete -f hello-job.yaml)。当使用 kubectl 来删除 Job 时,该 Job 所创建的 Pod 也会被删除
apiVersion: batch/v1
kind: Job
metadata:
name: hello-job
# 例如下面就会先创建 3 个 pod 并发执行任务,
# 一旦某个 pod 执行完成,就会再创建新的 pod 来执行,直到 5 个 pod 执行完成,Job 才会被标记为完成。
spec:
# 并发执行的 pod 的数量
parallelism: 3
# 创建 Pod 的数量
completions: 5
template:
spec:
# pod 内的 container 异常而结束时, Pod 会继续保留在当前 node, 但是重启内部 container
# 可选值: Never, ...
restartPolicy: OnFailure
containers:
- name: echo
image: busybox
command:
- "/bin/sh"
args:
- "-c"
- "for i in 9 8 7 6 5 4 3 2 1 ; do echo $i ; done"
kubectl apply -f hello-job.yaml
kubectl get jobs
kubectl get cronjob[s]
kubectl get pods -w
kubectl logs -f xxx_pod
8.7.7. cronjob (定时任务)
用法除了需要加上 cron 表达式之外,其余基本和 Job 保持一致。
# ┌───────────── 分钟 (0 - 59)
# │ ┌───────────── 小时 (0 - 23)
# │ │ ┌───────────── 月的某天 (1 - 31)
# │ │ │ ┌───────────── 月份 (1 - 12)
# │ │ │ │ ┌───────────── 周的某天 (0 - 6)(周日到周一;在某些系统上,7 也是星期日)
# │ │ │ │ │ 或者是 sun,mon,tue,web,thu,fri,sat
# │ │ │ │ │
# │ │ │ │ │
# * * * * *
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello-cronjob
spec:
schedule: "* * * * *" # Every minute
jobTemplate:
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- name: echo
image: busybox
command:
- "/bin/sh"
args:
- "-c"
- "for i in 9 8 7 6 5 4 3 2 1 ; do echo $i ; done"
8.8. service
用来代理一组 pods, 通过 label selector 选择一批 pods
Pod重建后ip是会重新分配的,而且一个服务Pod有好几个, 所以服务之间的调用肯定不能用Pod的ip,需要 service 提供代理; 但是这个Service代理和Nginx这样的反向代理还是不一样的,它本质上是和LVS类似的四层代理,也就是传输层代理, 它是不区分应用层是http流量还是mysql的流量的
提供访问服务的固定地址(服务发现, 负载均衡).
每个 Service 会对应一个集群内部有效的虚拟 IP,集群内部通过虚拟 IP (or service name) 访问一个服务
RC、RS 和 Deployment 只是保证了支撑服务的微服务 Pod 的数量,但是没有解决如何访问这些服务的问题。一个 Pod 只是一个运行服务的实例,随时可能在一个节点上停止,在另一个节点以一个新的 IP 启动一个新的 Pod,因此不能以确定的 IP 和端口号提供服务。要稳定地提供服务需要服务发现和负载均衡能力。
在 K8 集群中,客户端需要访问的服务就是 Service 对象, 类似 微服务中注册中心的角色, 通过某个 service, 可访问一组提供相同服务的 pods
kubectl get service[s]
8.8.1. Endpoint
被 selector 选中的 Pod,就称为 Service 的 Endpoints
它维护着 Pod 的 IP 地址,只要服务中的 Pod 集合发生更改,Endpoints 就会被更新
# check list
kubectl get endpoints
8.8.2. 多端口
apiVersion: v1
kind: Service
metadata:
name: test-k8s
spec:
selector:
app: test-k8s
type: NodePort
ports:
- port: 8080 # 本 Service 的端口
name: test-k8s # 多端口时必须配置 name
targetPort: 8080 # (被 Service 代理的)容器端口
nodePort: 31000 # 节点端口,范围固定 30000 ~ 32767
- port: 8090
name: test-other
targetPort: 8090
nodePort: 32000
K8S 的结构可以大致分为 3 层,Node, Pod, Container, 为了保护 Container 里面的应用,各层都进行了隔离。为了能够访问到 Pod 里面的 Container, Service 定义了几种 Port 类型:
Port - exposes the Kubernetes service on the specified port within the cluster. Other pods within the cluster can communicate with this server on the specified port.
是暴露在集群内部 Ip 上的端口, 提供集群内部访问 service 的入口, 即
clusterIP:port这时的 service 类型即 clusterIp 类型 (k8s 默认的 service type), 仅仅能在内部互相访问
TargetPort - is the port on which the service will send requests to, that your pod will be listening on. Your application in the container will need to be listening on this port also.
即 Pod / Container 监听的 Port.
NodePort - exposes a service externally to the cluster by means of the target nodes IP address and the NodePort.
NodePort is the default setting if the port field is not specified.
暴露端口到节点,可以让外网能够访问到 Pod/Container.
范围固定 30000 ~ 32767
8.8.3. ClusterIP (默认使用的类型)
Service 的默认类型,自动分配一个仅Cluster内部可以访问的虚拟IP, 通过 kubernetes 集群的内部 IP 暴露服务
当我们只需要让集群中运行的其他应用程序访问我们的 pod 时,就可以使用这种类型的 Service
(kubectl expose deployment/<deployment name> 可以直接创建 clusterIP 的 Service, 等价于 kc apply -f xxx)
输出结果为 service/xxx exposed
apiVersion: v1
kind: Service
metadata:
name: service-hellok8s-clusterip
spec:
# optional, 默认就是这样
type: ClusterIP
# associate with pods by using the label selector
selector:
app: hellok8s
ports:
# 当前 service 在集群内部暴露的端口, 即集群内部其他client通过这个端口访问当前 service
- port: 3000
# 指定当前 service 管理的 pod 上的端口(与制作容器时暴露的端口一致(即DockerFile中的EXPOSE))
# 从port/nodePort上来的数据,经过kube-proxy流入到后端pod的targetPort上,最后进入容器。
targetPort: 3000
8.8.3.1. Headless
service type 还是 clusterIP, 但是 clusterIp 设置为 None 就变成 Headless 了,不会再分配 IP
适合数据库
8.8.4. NodePort
在ClusterlP基础上为Service在每台机器上绑定一个端口,这样就可以在 cluster 外部通过<NodeIP>:NodePort 来访问该服务
比如外部用户要访问 k8s 集群中的一个 Web 应用,那么我们可以配置对应 service 的 type=NodePort,nodePort=30001。其他用户就可以通过浏览器 http://node:30001 访问到该 web 服务。
而数据库等服务可能不需要被外界访问,只需被内部服务访问即可,那么我们就不必设置 service 的 NodePort。
但是 node port 数量是有限的, 六万多个吧, 如果都用这种方式暴露服务给集群外部访问, 总有用完的时候, 这是需要 ingress
NodePort 服务会路由到自动创建的 ClusterIP 服务。
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
type: NodePort // 配置NodePort,外部流量可访问k8s中的服务
ports:
- port: 30080 // 服务访问端口,集群内部访问的端口
targetPort: 80 // pod控制器中定义的端口(即 container 定义中的端口)
nodePort: 30001 // NodePort,外部客户端访问的端口, 范围固定 30000 ~ 32767
selector:
name: nginx-pod
8.8.5. LoadBalancer
在NodePort的基础上,创建一个外部负载均衡器, 将请求转发到内部 Service 上; 需要第三方负载均衡服务来实现,可以是软件的也可以是硬件的。
一般是使用云提供商的负载均衡器向外部暴露服务。 这个外部负载均衡器可以将流量路由到自动创建的 NodePort 服务和 ClusterIP 服务上.
8.8.6. ExternalName
此类型的Service节点会将所有流量直接转发到某个预定义的外部服务。
通常情况下,在集群内使用ExternalName Service类型,将某个外部服务作为集群内部服务的别名来使用,使得内部服务使用起来更加方便和简单
8.8.7. 手动端口转发
kubectl port-forward <pod name> <node port>:<container port>, 用于临时调试
8.8.8. service 如何工作
Pod 通过 label 键值对与 Service 上的 label selector 相关联。Service 会自动发现带有与选择器匹配的标签的新 Pod。
8.9. ingress
可为 Service 提供外部可访问的域名绑定(默认端口 80, 通过域名进行流量转发)、负载均衡、 SSL/TLS
和 Service 区别: service 毕竟只是内部使用的负载均衡, 无法提供给外界访问(虽然也能通过 node port 类型来暴露给外界, 但不经不是专门用来干这个的); Service 工作在网络传输层, 只能识别 ip 和端口来处理网络流量 ingress 则用于将外部网络流量路由到适当的Service上; ingress 工作在应用层, 能识别 http协议, 更细的路由控制
为什么需要? - NodePort的方式有个问题,每个 working node 端口65535个,总有用完的时候,要是暴露的服务特别多,65535就不够用了,所以还是得上nginx这样的反向代理,因此K8S还有个Ingress的东西。避免了对外暴露集群节点端口
可以根据域名、路径把请求转发到不同的 Service, 相当于 nginx
常用的实现是 nginx-ingress, kong-ingress, Traefik Ingress; k8s 也只是定义了 ingress 资源的各个属性,ingress 资源的创建需要借助 ingressController,ingressController 则需要有第三方服务来提供。
原理: Ingress Contronler 通过与 Kubernetes API 交互,动态的去感知集群中 Ingress 规则变化,然后读取它,按照自定义的规则,规则就是写明了哪个域名对应哪个 service,生成一段 Nginx 配置,再写到 Nginx-ingress-control 的 Pod 里,这个 Ingress Contronler 的 pod 里面运行着一个 nginx 服务,控制器会把生成的 nginx 配置写入/etc/nginx.conf 文件中,然后 reload 一下 使用配置生效。以此来达到域名分配置及动态更新的问题。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: hello-ingress
annotations:
# We are defining this annotation to prevent nginx
# from redirecting requests to `https` for now 关闭 https 连接
nginx.ingress.kubernetes.io/ssl-redirect: "false"
spec:
rules:
- http:
paths:
- path: /hello
pathType: Prefix
backend:
service:
name: service-hellok8s-clusterip
port:
number: 3000
- path: /
pathType: Prefix
backend:
service:
name: service-nginx-clusterip
port:
number: 4000
支持这些命令
# create
kubectl apply -f ingress.yaml
# check list
kubectl get ingress
8.9.1. install ingress-nginx
https://docs.rancherdesktop.io/zh/how-to-guides/setup-NGINX-Ingress-Controller
8.9.2. Traefik
todo Traefik
8.10. volume
即在 pod 中可访问的文件目录, 用来存储大数据量的内容
每个 Pod 中声明的存储卷由 Pod 中的所有容器共享
可被挂载到 pod 中的一个/多个 container 的指定路径 下
8.11. secret
Secret 是用来保存和传递密码
好处是可以避免把敏感信息明文写在配置文件里
Secret 的资源定义和 ConfigMap 结构基本一致,唯一区别在于 kind 是 Secret,还有 Value 需要 Base64 编码
echo "db_password" | base64
# ZGJfcGFzc3dvcmQK
echo "ZGJfcGFzc3dvcmQK" | base64 -d
# db_password
for example:
# hellok8s-secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: hellok8s-secret
data:
DB_PASSWORD: "ZGJfcGFzc3dvcmQK"
从中查询信息:
kubectl get secret my-mongo-mongodb -o json
kubectl get secret my-mongo-mongodb -o yaml > secret.yaml
8.12. config map
将非机密性的数据保存到键值对中
用docker的时候有一个volume可以把宿主机的存储挂载到容器中,在k8s里也差不多,但是有两种场景:
挂载配置文件. 在 docker 里给应用进行配置, 可以使用 env环境变量传到容器里. 还有一种是通过配置文件挂载到容器里面。用环境变量的方式还好说,k8s也提供了env变量,但是配置多了env管理起来不方便,还是配置文件好。 但是k8s有的服务Pod可能部署在多台机器, 所以 configMap 出现了, 可以和 微服务的配置中心类比 (这两者的区别在于ConfigMap是直接把中心化的配置映射到各个容器内,让容器内的应用感觉像是读本地的文件一样,而配置中心是需要应用层搞一个客户端与配置中心通信拉取配置给SpringCloud用)
挂载数据存储, 这个请看数据持久化
ConfigMap 在设计上不是用来保存大量数据的。在 ConfigMap 中保存的数据不可超过 1 MiB。如果你需要保存超出此尺寸限制的数据,你可能考虑挂载存储卷。
# hellok8s-config-dev.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: hellok8s-config
data:
DB_URL: "http://DB_ADDRESS_DEV"
# hellok8s-config-test.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: hellok8s-config
data:
DB_URL: "http://DB_ADDRESS_TEST"
分别在 dev test 两个 namespace 下创建相同的 ConfigMap,名字都叫 hellok8s-config,但是存放的 Pair 对中 Value 值不一样
kubectl apply -f hellok8s-config-dev.yaml -n dev
kubectl apply -f hellok8s-config-test.yaml -n test
# check list in all ns
kubectl get configmap --all-namespaces
在 pod 部署中使用 configMap
apiVersion: v1
kind: Pod
metadata:
name: hellok8s-pod
spec:
containers:
- name: hellok8s-container
image: guangzhengli/hellok8s:v4
# used to declare an env var
env:
- name: DB_URL # the value have to consist with code
# specify that getting db_url from the specified config map
valueFrom:
configMapKeyRef:
# config map 的name
name: hellok8s-config
key: DB_URL
8.13. flannel
是 CoreOS 团队针对 Kubernetes 设计的一个网络规划服务, 简单来说, 它的功能是让集群中的不同节点主机创建的 Docker 容器都具有全集群唯一的虚拟 IP 地址, 让属于不同节点上的容器能够直接通过内网 IP 互通
8.14. name
由于 K8S 内部,使用“资源”来定义每一种逻辑概念(功能)故每种"资源”, 都应该有自己的"名称”
"资源”有 api 版本( apiVersion )类别( kind )、元数据( metadata)、定义清单( spec)、状态( status )等配置信息
"名称”通常定义在"资源”的"元数据”信息里
8.15. name namespace (用来划分多环境)
可以使用 namespace 划分出多个“虚拟集群”,这些 ns 之间可以完全隔离, 例如 dev 环境给开发使用,test 环境给 QA 使用
也可以跨 ns,让一个 ns 中的 service 访问到其他 ns 的服务
名字空间作用域仅针对带有名字空间的对象,例如 Deployment、Service 等。
namespace: isolate all all kinds of resources. resources of the same kind cannot have the same name in the same namespace
default initialized namespaces: default, kube-system, kube-public
apiVersion: v1
kind: Namespace
metadata:
name: dev
---
apiVersion: v1
kind: Namespace
metadata:
name: test
# create
kubectl apply -f namespaces.yaml
# check list
kubectl get namespaces
# specify the namespace when creating resources
kubectl apply -f deployment.yaml -n dev
# check pods in specified ns
kubectl get pods -n dev
# 创建命名空间
kubectl create namespace testapp
# 切换命名空间
kubens kube-system
# 回到上个命名空间
kubens -
# 切换集群
kubectx minikube
9. 垃圾回收
9.1. 级联删除
所有者删除,从属对象也被删除;
分为前台级联删除 Foreground 和后台级联删除 Background 模式;
Foreground 前台级联删除:所有从属对象删除完毕后删除所有者对象;当所有者删除时会进入“正在删除”状态,仍可以通过 RestApi 查询到当前对象;
Background 后台级联删除: 立即删除所有者的对象,并由垃圾回收器在后台删除其从属对象 ; 不用等待删除从属对象的时间;
9.2. 孤儿删除 orphan
所有者删除,从属对象变成孤儿
直接删除所有者对象,并将从属对象中的 ownerReference 元数据设置为默认值。之后垃圾回收器会确定孤儿对象并将其删除;
10. 资源描述文件
10.1. 查看属性说明
如 当前 k8s 支持的 apiVersion ...
kc explain deployment , kc explain deployment.spec.template.spec
10.2. 通过命令生成 yml
kubectl create deployment tomcat6 --image=tomcat:6.0.53-jre8 --dry-run -o yaml > tomcat6.yml
kubectl apply -f xxx.yaml
10.3. pod 的 yaml 描述文件
apiVersion : v1 #(k8s api server version)
# Deployment、Job、Ingress、Service
kind: Pod #(对象类型)
metadata: #包括名称、命名空间、标签和关于该容器的其他信息
name: kubia-manual
# optional, default ns: default
namespace: xxx
# optional
labels:
xxx_key: xxx
yyy_key: yyy
# 包括一些container,storage,volume, 探针...
spec:
containers:
- image: xxx
name: xxx
ports:
- containerPost: 8080 # 容器会监听的端口, 仅仅是展示, 没有 指定作用
protocal: TCP
resources:
requests:
cpu: 100m
memory: 100Mi
# 存活探针, 用于 pod
# 在生产中 运行的pod, 一定 要定义 一 个存 活探针
# optional
livenessProbe:
httpGet:
path: /
port: 8080
# 如果没有设置初始延迟,探针将在启动时立即开始探测容器, 这通常会导致探测失败, 因为应用程序还没准备好开始接收请求。 如果失败次数超过阅值,在应用程序能正确响应请求之前, 容器就会重启。
initialDelaySeconds: 15 # 在第一次探测前, 等待 15s
[delay: 0] # 示在容器启动后立即开始探测。
[timeout: 1] # 容器必须在1秒内进行响应, 不然这次探测记作失败
[period: 10] # 每10秒探测一次容器
[failure: 3] # 探测连续三次失败(#fa辽ure= 3)后重启容器
status: #包含运行中的 po 的当前信息,例如 po 所处的条件 每个容器的描述和状态,以及内部 IP 和其他基本信息
10.4. deployment 的描述文件
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
## optional
nodeSelector:
gpu: 'true' #使用 标签选择器使得 pod 只被调度到符合要求的 worker node
# optional
# select pods that will be affected by this deployment
# have to match labels that specified in template.metadata.labels
selector:
matchLabels:
app: nginx
# optional
replicas: 2 # tells deployment to run 2 pods matching the template
# define pods
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:alpine
ports:
- containerPort: 80
10.5. service
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
type: LoadBalancer
ports:
- name: nginx
port: 80
targetPort: 80
selector:
app: nginx
11. 注解
注解: TODO
12. 命名空间
K8S namespace: 为 对象资源提供了一个作用域, 在不同的 作用域中可以使用相同的资源名, 但这相同的资源名代表了不同的资源。 类比 java package
通过 label 对 pod 进行分组, 每个 组 可能有 pod 重叠, 通过 k8s namespace 分组可以完全避免重叠
ns 只隔离资源, 不隔离运行的对象 (资源实例), 如 不同 ns 中的 pod 仍然可通信
适用于多用户 使用 k8s, 限制某个用户的资源使用量
从 ymal 文件创建 ns:
apiVersion: vl
kind: Namespace
metadata:
name: custome-ns
kubectl create -f custom-ns.yaml
通过命令创建 ns: kubectl create namespace custom-namespace
切换 ns: kubectl config set-context $(kubectl config current-context) --namespace <other ns>
13. pod 管理
13.1. 探测 pod 是否健康
k8s 会保持 pod 始终正常运行, 如果容器的主进程崩溃, Kubelet 将重启容器。 当容器被强行终止时,会创建一个全新的容器—-而不是重启原来的容器
但是 进程没有崩溃, 有时应用程序也会停止正常工作。 例如, 具有内存泄漏的 Java 应用程序将开始抛出 OutOfMemoryErrors, 但 JVM 进程会一直运行
方法 1: 从 app 内部自己检测, 可以在应用中捕获这类错误, 并在错误发生时退出该进程。
存在问题: 应用因为无限循环或死锁而停止响应, 这个方法就无效了
方法 2: 须从外部检查应用程序的运行状况
存活探针 (liveness probe) - 检查容器是否还在运行
HTTP GET 探针, 返回 2xx, 3xx 则代表正常, 不重启
TCP 套接字探针, 和 pod 正常建立 链接, 正常, 不重启
Exec 探针 , 进入 pod 某个 container, 执行任意命令, 并检查命令的退出状态码。如果状态码是 0, 则探测成功
apiVersion: vl
kind: Pod
metadata:
name: custome-pod
spec:
containers:
- image: xxx
name: xxx
livenessProbe:
httpGet:
path: /
port: 8080
13.2. pod 副本
ReplicationController 是一种 Kubernetes 资源,负责创建和管理 pod 副本
被 ReplicationController 创建的 pod 为 “托管 pod”, 直接创建的 pod 为 “非托管 pod”。托管 pod 异常退出 (如 worker node 崩溃, 或 该 pod 崩溃)后, ReplicationController 会 创建新的 pod 代替
apiVersion: vl
kind: Replicationcontroller
metadata:
name: kubia
spec:
replicas: 3
# 定义ReplicationController时不要指定 选择器,让Kubemetes从pod模板中提取它。这样YAML更简短。
# rc 创建后, label selector 不会再更改
# 一般创建后会更改 template
[selector:
app: kubia]
# 创建新 pod 所用的 模板
template:
metadata:
# 这里的 标签必须和 前面的 标签选择器 匹配, 否则将无休止地创建新的容器
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
ports:
- containerPort: 8080
kubectl create -f kubia-rc.yaml
rc 创建后,由于没有任何 pod 有 app=kubia 标签, ReplicationController 会根据 pod 模板启动三个新的 pod
由 ReplicationController 创建的 pod 并不是绑定到 ReplicationController。 在任何时刻, ReplicationController 管理与标签选择器匹配的 pod。 通 过更改 pod 的标签, 可以将它 从 ReplicationController 的作用域中添加或删除
尽管一个 pod 没有绑定到一个 ReplicationController ,但 pod 在 metadata.ownerReferences 中引用它 以轻松使用它 来找到一 pod 的 Replication controller
升级 pod 可以这么做:编辑 rc 的 template 后, 删除 所有要升级的 pod, rc 会自动创建升级后的 pod
================水平缩扩容:
方法 1:kubectl scale re kubia --replicas=3
方法 2:kubectl edit re kubia 更新 spec.replicas 值
======================新的替代者 ReplicaSet
ReplicaSet:ReplicaSet 的行为与 ReplicationController 完全相同, 但标签选择器的表达能力更强。
- 单个 rc 无法将 pod 与 ( label env=prod 和 env=dev ) 同时匹配,它只能匹配带有 env=devel 标签的 pod 或带有 env=dev 标签的 pod
- rs 可以仅仅根据 是否有 label key 存在 来匹配
apiVersion: apps/v1beta2
kind: ReplicaSet
metadata:
name: kubia
spec:
replicas: 3
selector:
# 指定了多个表达式,则所有这些表达式都必须为true才能使选择器与
# pod匹配。如果同时指定matchLabels和matchExpressions, 则所有标签都
# 必须匹配,并且所有表达式必须计算为true以使该pod与选择器匹配
[matchLabels:
hah: hoo]
matchExpressions:
- key: hah # 要求 pod 包含 key 为 hah 的 label
# 要求 label 值为 hoo
# operator 可选 In (label 值需要匹配 value 中的一个), NotIn (label 值需要不在 values 中),Exists (label 必须有指定 key,不指定 values)
# DoesNotExist (pod不得包含有指定名称的标签。values属性不得指定)
operator: In
values:
- hoo
# 创建新 pod 所用的 模板
template:
metadata:
# 这里的 标签必须和 前面的 标签选择器 匹配, 否则将无休止地创建新的容器
labels:
hah: hoo
spec:
containers:
- name: kubia
image: luksa/kubia
ports:
- containerPort: 8080
================ DaemonSet 在每个 worker node 上部署一个 pod
用来运行系统服务,如 kube-proxy
DaemonSet 管理下的 pod 不是随机分布在 worker node 上, 而是保证 每个 node 只存在一个 pod。
若 node 下线, DaemonSet 不会在其他地方创建新的 pod, 但是当某个 node 的 pod 被意外删除,会重新创建新的 pod 代替
但是 当新的 node 添加进 集群, DaemonSet 会立即部署一个新 pod 到这个 node。
通过 spec.nodeSelector (节点选择器,原理是给 node 打标签) 只在特定 node 部署 pod
======================= Deployment ======= 更加方便的管理 Replica Set
Deployment 额外的特性:
事件,状态查看:可以查看 Deployment 的升级详细进度和状态
回滚:当升级 pod 镜像或者相关参数的时候发现问题,可以使用回滚操作回滚到上一个稳定的版本或者指定的版本
版本记录: 每一次对 Deployment 的操作,都能保存下来,给予后续可能的回滚使用
暂停和启动:对于每一次升级,都能够随时暂停和启动
多种升级方案:
Recreate:删除所有已存在的 pod,重新创建新的;
RollingUpdate:滚动升级,逐步替换的策略,同时滚动升级时,支持更多的附加参数,例如设置最大不可用 pod 数量,最小升级间隔时间等等。
================= HPA 弹性伸缩 根据资源的使用情况自动缩扩容
13.3. 运行单个任务 Job
到目前为止, 我们只谈论了需要持续运行的 pod, 这些 pod 由 rc, rs, ds 管理。 你会遇到只想运行完成工作后就终止任务的清况, 这种 pod 由 Job 管理
该 pod 在内部进程成功结束时, 不重启容器。一旦任务完成, pod 就被认为处千完成状态
apiVersion: batch/v1
kind: Job
metadata:
name: ba七ch-job
spec:
[completions: 5] # 顺序运行 5 个 pod
[parallelism: 2] # 最多可以 2 个 pod 并行运行
[activeDeadlineSeconds: 120] # job 超时时间,若 pod 超时还没结束,系统将终止 pod, 标记 job 为失败
[backOffLimit: 6] # job 标记为失败前的重试次数, 默认 6
template:
metadata:
# Job 的 pod 选择器 将自动根据这里的 labels 创建
labels:
app: batch-job
spec:
# 重启策略, 指定 容器中进程结束后, k8s 做什么
# 不能是 默认的 Always
# 这里 Never 亦可
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job
13.4. 定时任务 CronJob
TODO
14. pod 通信
14.1. proxy
14.2. Service
pods 有自己的内部地址, 但是无法从 cluster 外部访问, 通过 service 可以暴露到 cluster 外部
service 是一个逻辑结构, 定义一系列 pods, 以及他们的访问策略(通过类型指定)
- ClusterIP (default): 只能在 cluster 内部访问到 service
- NodePort: 外部可以使用
<NodeIP>:<NodePort>访问 service - LoadBalancer: 给 service 分配一个静态 ip, 可以负载均衡多个 pods
- ExternalName: 通过随机名字访问 service (可通过 externalName 在配置中指定). This type requires v1.7 or higher of kube-dns.
a default service named kubernetes will be created with type ClusterIP
可以定义配置文件, 指定标签选择器, 选择包含哪些 pods
14.3. pod 间通信
Service
作用:
- 服务的主要目标就是使集群内部的其他 pod 可以访问当前这组 pod
- 对外暴露服务
如何创建?
方式 1:kubectl expose rc kubia --type=LoadBalancer --name kubia-http
方式 2:通过 kubectl create -f xxx-service.yml
apiVersion: vl
kind: Service
metadata:
name: kubia
spec:
# 配置会话亲和性
# 特定客户端产生的所有请求每次都指向同 一个 pod
# 还可选 None, 默认值。不支持 cookie
[sessionAffinity: ClientIP]
ports:
- port: 80 # service 的可用端口
# 可以引用 Pod 中 的 port name
targetPort: 8080 # service将链接转发到 容器的端口
# 不是必须, 多端口映射必须
[name: xxx]
selector:
app: kubia
多端口映射
apiVersion: vl
kind: Service
metadata:
name: kubia
spec:
# 配置会话亲和性
# 特定客户端产生的所有请求每次都指向同 一个 pod
# 还可选 None, 默认值。不支持 cookie
[sessionAffinity: ClientIP]
ports:
- port: 80 # service 的可用端口
targetPort: 8080 # service将链接转发到 容器的端口
name: xxx
- port: 443
targetPort: 8443
name: yyy
selector:
app: kubia
如何发现 service
通过环境变量发现服务
每个 pod 内会有环境变量表示 Service ip (
<pod name>_SERVICE_HOST), port (<pod name>_SERVICE_PORT)通过 dns
kube-system ns 中有个 pod 为 kube-dns,就是 dns server。在集群 中的其他 pod 都被配置成使用其作为 dns ( Kubemetes 通过修改容器的 /etc/resolv.conf 实现)。运行在 pod 上的进程 DNS 查询都会被 Kubemetes 自身的 DNS 务器响应
pod 是否使用内部的 DNS 服务器是根据 pod 的 spec.dnsPolicy 属性来决定的
通过 FQDN (全限定域名) 连接服务
curl http://kubia.default.svc.cluster.local
14.4. 通过 Service 连接外部服务
pod 如何访问 k8s 外部 服务?
14.4.1. 通过手动生成 endpoint
Service 和 pod 中间不是直接相连, 而是插着 Endpoint,就是一个 ip:port 列表,在创建 Service 时 根据 该服务的 label selector 产生
如果 Service 没有指定 pod selector, 就不会自动生成 endpoints,需要手动生成,这时可以指定地址为任意 外部的 ip:
demo-service.yml:
apiVersion: vl
kind: Service
metadata:
name: demo-service
spec:
# 没有配置 selector
# 将接收端口80上的传入连接
ports:
- port: 80
demo-service-endpoints.yml
apiVersion: vl
kind: Endpoints
metadata:
# Endpoint的名称必须和 service 的名称相同
name: demo-service
subsets:
# Service将把请求重定向到 下面的 地址
- addresses:
- ip: 11. 11. 11. 11
- ip: 22.22.22.22
ports:
- port: 80
如果稍后决定将 外部服务迁移到 Kubemetes 中运行的 pod, 可以为服务添加选择器,从而对 Endpoint 进行自动管理
14.4.2. 通过 externalName 类型的 Service
另外的方式来访问外部服务:创建 ExtemalName 类型的 Service
apiVersion: vl
kind: Service
metadata:
name: external-service
spec:
# 默认为 ClusterIP,只能 pod 间通信
# 还有很多种 type
type: ExternalName
externalName: someapi.somecompany.com
ports:
- port: 80
然后在 pod 中通过 external-service[.default.svc.cluster.local] 访问 someapi.somecompany.com
在以后如果将其指向不同的服务,只需简单地修改 externalName 属性,或者将类型重新变回 ClusterIP 并为服务创建 Endpoint
14.5. 将服务暴露给外部
14.5.1. 将服务的类型设置成 NodePort
每个集群节点都会在节点上打开一个端口(端口号相同)。并将传入的连接转发给 pod
apiVersion: vl
kind: Service
metadata:
name: kubia-nodeport
spec:
type: NodePort
ports:
- port: 80
targetPort: 8080
# 通过 集群任意节点的 30123 端口可以访问 这个 service
# 如果不指定,Kubernetes将选择一个随机端口
nodePort: 30123
selector:
app: kubia
worker node ip 如何获取:kubectl get nodes -o jsonpath='...'
14.5.2. 将服务的类型设置成 LoadBalance
NodePort 类型的一 种扩展, 在 client 和 worker node 间 放了一个 LoadBalancer, 防止节点单点故障
负载均衡器拥有自己独一无二的可公开访问的 IP 地址, 并将所有连接重定向到服务。可以通过负载均衡器的 IP 地址访问服务
apiVersion: vl
kind: Service
me七adata:
name: kubia-loadbalancer
spec:
type: LoadBalancer
# 仅将外部通信重定向到接收连接的节点上运行的pod
# 如果没有本地pod存在, 则连接将挂起。因此, 需要确保负载平衡器将连接转发给至少具有一个pod的节点。
# 可避免额外的网络跳转。但是可能会导致跨节点的 pod 的负载分布不均衡
[externalTrafficPolicy: Local ]
portS:
- port: 80
targetPort: 8080
selector:
app: kubia
14.5.3. 创建一 个 Ingress 资源
通过一 个 IP 地址公开多个服务,它运行在 HTTP 层(网络协议第 7 层)上, 因此可以提供比工作在第 4 层的服务更多的功能
为什么需要 Ingress:每个 LoadBalancer 服务都需要自己的负载均衡器,每个 loadbalancer 都需要自己的 ip, 而 Ingress 只需要一个公网 IP 就能为许多服务提供访问
当客户端向 Ingress 发送 HTTP 请求时, Ingress 会根据请求的主机名和路径决定请求转发到的服务。
Ingress 工作在 应用层 基于 cookie 的会话亲和性 (session affinity)
已经确认集群中正在运行 Ingress 控制器, 因此现在可以创建一个 Ingress 资源:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kubia
spec:
rules:
# Ingress 将这个域名映射到你的 service
- host: kubia . example.com
http:
paths:
# 将请求发送到 kubia-nodeport 服务的 80 端口
- path: /
backend:
serviceName: kubia-nodeport
servicePort: 80
kubectl get ingresses 获取 Ingress 控制器 内网 ip,配置到 dns server
为 ingress 创建 tls 认证 TODO
15. 命令
15.1. kubectl
15.1.1. 基本信息
kubectl version
kubectl cluster-info
kubectl get nodes
# 获取kube-scheduler和kube-controller-manager组件状态
kubectl get cs # 健康状况
15.1.2. 创建 create expose
# create depend on a spec file.
#
# 和 kubectl apply 区别:
# - create 是创建新资源。这里我们需要注意的是,如果再次运行相同的命令,就会抛出错误,因为资源名称在名称空间中应该是唯一的。
# - apply 使配置在资源上生效, 可能是创建, 也可能是根据资源定义文件更新资源, 可重复执行 (推荐)
#
kubectl create -f xxx.yml
# 递归从 dir 下查找资源定义文件, 并创建
kc create -R -f <dir>
# >>> deployment,
# dep-name 不能随便设置, 必须符合域名命名规范.
# 自动创建的 ReplicaSet 名字为 dep_name + random uuid
# 自动创建 pod 名字为 ReplicaSet-name + random uuid
# 镜像地址 include the full repository url
# 自动创建 label -> run={dep name}
# auto create selector -> run={dep name}
kubectl create deployment <dep name> --image=k8s.gcr.io/echoserver:1.4
kubectl create deployment tomcat6 --image=tomcat:6.0.53-jre8 # 不指定 url 前缀, 默认从 docker hub 拉取
# >>> proxy
# pods 默认仅仅能被 同个集群的 pods, service 访问
# 创建临时的 代理, 可以将外部命令转发到 cluster 内部的 pod
# Ctrl +c 关闭
kubectl proxy
# 查 版本
curl http://localhost:8001/version
# 访问指定 pod 的服务
curl http://localhost:8001/api/v1/namespaces/default/pods/$POD_NAME/proxy/
# >>> pod
kubectl run <pod name> --image=nginx --restart=Never --port=80
# --generator=run/vl 表示同时创建 rc 管理 pod
kubectl run <pod name> --image=luksa/kubia --port=8080 --generator=run/vl
# 从描述文件创建 资源, 可以 pod, rc。。。, 可指定 ns, 默认 default
kubectl create -f kubia-manual.yaml [-n xxx_ns]
# >>> service
# 创建 service, 名字同 deployment
# The LoadBalancer type makes the Service accessible through the minikube service command
# Port 8080 is specified in image code, so cannot be other port here
# --port : service 暴露在 cluster ip 下的端口, 通过这个端口, 可以在 cluster 内部访问到多个 pod. 通过这个 service 负载均衡了 多个 pod
# --targetPort 容器的端口, 默认=== port, 与制作镜像时暴露的端口一致, 不能随便指定
# --type: service 类型,
# NodePort: 创建一个 service 并暴露到 cluster 外部, service 的端口还是 --port 指定, 同时 service 有自己的 cluster url, node 会指定一个随机端口映射到 service 的 端口, 若指定了 --nodePort, 就用指定端口映射到 service 端口; 如 type=NodePort,而且配置 nodePort=30001, 那么外部机器 可以 scheme://nodeIP:30001访问到该服务
# LoadBalancer:
kubectl expose deployment <dep name> --type=LoadBalancer --port=8080
# 查找暴露的随机端口
kubectl describe service mywebservice | grep NodePort
# service port 80 will mapping to random node port ,and this service can be visited by someone outside cluster
# 若扩容, 则在各个有 pod 运行的节点都能通过 node 端口访问 这个 service
kubectl expose deploy tomcat6 --port=80 --target-port=8080 --type=NodePort
# 创建一个负载均衡服务 service 对象. 可以从外部访问 pod
# rc 为 replicationController 缩写
kubectl expose rc <po name> --type=LoadBalancer --name kubia-http
# >>> label
# 语法: kubectl label <obj_type, eg: pod, service> <obj_name> <label, eg: app=v1>
kubectl label pod $POD_NAME app=v1
# >>> 命名空间
# 创建
kubectl config set-context Kubernetes --namespace=beta
# 验证
kubectl config view | grep namespace command
15.1.3. 执行命令到容器 exec
# 仅有 一个容器在 pod, 无需指定容器
kubectl exec [-c container_name] $POD_NAME -- env
# 进入 pod 内部随机一个容器
kubectl exec -ti $POD_NAME -- bash
15.1.4. 修改
# >>> 扩容
# 指定 replicas 可以缩扩容
$ kubectl scale deployments/<dep_name> --replicas=4
kubectl scale deployment.apps/tomcat6 --replicas=2
kubectl scale deployment tomcat6 --replicas=2
# >>> 滚动更新
# 更新 image version
$ kubectl set image deployments/<dep_name> <dep_name>=jocatalin/kubernetes-bootcamp:v2
# 验证更新是否成功
$ kubectl rollout status deployments/kubernetes-bootcamp
# >>> 回滚
# 取消之前的部署,这将执行反向操作,将负载移动至之前版本的容器
$ kubectl rollout undo deployments/kubernetes-bootcamp
15.1.5. 资源列表 get
单复数均可
# 所有
kubectl get all
# >>> deployment
kubectl get deployments
# >>> pods
# --show-labels 同时显示所有标签。
# -A 查看所有 pods, 包括 kube-system 命名空间 下的 pods
# --all-namespaces 所有空间的 pods
kubectl get pods [--show-labels]
# -o 输出格式; wide 表示输出文本信息, 列出 ip , 节点 name
# -o yaml
kubectl get pods -o wide
# 通过标签过滤
kubectl get pods -l <label>
# 获取 pod 完整 yaml/json 文件
# 缩写 po
kubectl get po <pod name> -o yaml
kubectl get po <pod name> -o json
kubectl get node
# 根据模板获取 信息
export POD_NAME=$(kubectl get pods -o go-template --template '{{range .items}}{{.metadata.name}}{{"\n"}}{{end}}')
export NODE_PORT=$(kubectl get services/kubernetes-bootcamp -o go-template='{{(index .spec.ports 0).nodePort}}')
# >>> service
# 查看 service 的 endpoint 列表
kubectl get endpoints <service name>
# 查看所有 svc
# 缩写 svc
kubectl get services
# >>> ReplicaSet
kubectl get rs
# 端口转发, 将会运行一个端口转发代理
# 将 local port 8888 转发到 pod 的 8080
kubectl port-forward <pod name> 8888:8080
# 标签
# 列出 pods 的所有标签
kubectl get pods --show-labels
# 只列出感兴趣的标签, 标签按照列展示
kubectl get po -L creation_method,env
# 添加
kubectl label po <pod name> creation_method=manual
# 修改
kubectl label po <pod name> creation_method=manual --override
# 标签选择器
kubectl get po -1 creation_method=manual
kubectl get po -1 creation_method!=manual
kubectl get po -1 env
# 列出没有 env 的pod
kubectl get po -1 '!env'
# 选择带有env标签且值为prod或devel的pod
kubectl get po -1 env in (prod, devel)
kubectl get po -1 env notin (prod, devel)
# 使用 label 分类 worker node
kubectl get nodes
kubectl label node <node name> gpu=true # 每个 node 都有一个默认 label, kubernetes.io/hostname:主机名
kubectl get nodes -l gpu=true
# 命名空间
# 查看所有 ns, 有 default, kube-public, kube-system,默认我们使用的是 default
kubectl get ns
# 列出只属于该命名空间的 pod, 可使用 -n
kubectl get po --namespace kube-system
# 编辑 rc 的 yaml
# 一般仅仅编辑 rc 的 template, 不动 label selector
# 用来升级 pod
kubectl edit rc kubia
# 增加 副本数, 水平扩容
kubectl scale rc kubia --replicas=3
# 等同 parallelism
kubectl scale job xxx_job --replicas 3
# 远程在 pod 中某个 container 执行命令
# “--” 表示 kubectl 命令结束, 后面的是在 pod 内执行的
kubectl exec <pod name> -- curl -s http://10.23...
# 列出环境变量,如 Service 的 ip, 端口
kubectl exec kubia-3inly env
# 在 pod 中执行 shell
kubectl exec -it kubi-3inly bash
# >>> 配置文件
kubectl config view
# >>> 事件
kubectl get events
# 通过 describe 也能得到 object 相关的事件
15.1.6. 查询详细描述 describe
# >>> pods
# 查看资源描述, 附加信息, 作为 kubectl get xxx xxx 补充, 可用于排查问题
# 如 pod 是否正在运行, 重启原因, 退出码 137,143 表示 pod 被迫终止
kubectl describe pods [pod_name]
# >>> service
kubectl describe services/<srv name>
# >>> deployment
$ kubectl describe deployment
15.1.7. 查询日志 logs
kubectl logs <pod name> [-c container_name] [--previous]
# 查指定 pod 下的 container 日志
# 若pod 只有一个 container, 无需指定 container
kubectl logs $POD_NAME
# 如果容器已经崩溃停止,您可以仍然使用
kubectl logs --previous
# 追踪
kubectl logs -f POD-NAME
# 实例:
# 追踪名称空间 nsA 下容器组 pod1 的日志
kubectl logs -f pod1 -n nsA
# 查看容器组 nginx 下所有容器的日志
kubectl logs nginx --all-containers=true
# 查看带有 app=nginx 标签的所有容器组所有容器的日志
kubectl logs -lapp=nginx --all-containers=true
# 查看容器组 nginx 最近20行日志
kubectl logs --tail=20 nginx
# 查看容器组 nginx 过去1个小时的日志
kubectl logs --since=1h nginx
# 需要 ssh 到 pod 所在的 worker node
docker logs <container_id>
# 无需 ssh, 可指定某个 container, 可指定看重启前的版本的日志
# 查看 k8s 资源
kubectl explain pods
kubectl explain pod.spec
15.1.8. 删除 delete
# delete by spec file
kubectl delete -f flask.yaml
# 删除 pod
# 无法直接删除, 只要 replicaSet 没有删除, 删了 po, 还会重现创建 po
# 可直接 通过删除 deployment 删除
kubectl delete po kubia-gpu [pod2 [pod3]]
# 删除当前 ns 下 all pod, 保留 ns
kubectl delete po --all
# 按照标签删除
kubectl delete po -1 creation_method=manual
kubectl delete service hello-node
kubectl delete deployment hello-node
# 删除 ns, 同时会删除 ns 下的所有 pod
kubectl delete ns custom-namespace
# 删除所有资源, 包括 rc, pod, service
kubectl delete all --all
# 删除 rc, rc 管理的 pods 也会删除
kubectl delete rc <rc name>
# 删除 rc, 但是保留 pods
kubectl delete rc <rc name> --cascade=false
kubectl delete rs kubia
# 删除所有 pod, deployment, service 资源
kubectl delete deployment,service --all
15.1.9. 操作上下文
# 更新上下文, 为当前上下文加上 namespace
kubectl config set-context $(kubectl config current-context) --namespace <other ns>
# check list
kubectl config get-contexts
# 更换上下文
kubectl config use-context docker-desktop
15.2. kubeadmin
kubeadm init # create a master node
kubeadm join <master_id:port> # add a node to cluster
16. cka ckad 证书考试
https://blog.csdn.net/vic_qxz/article/details/108338442 https://zhuanlan.zhihu.com/p/139052135 备考 cka ckad
https://training.linuxfoundation.cn/certificate/details/1 中国区
https://zhuanlan.zhihu.com/p/138796893 https://www.jianshu.com/p/629525af31c4 https://www.kubernetes.org.cn/peixun 考试要点 https://zhuanlan.zhihu.com/p/138796893 , https://www.zhihu.com/zvideo/1302356091591372800 真题
17. dashboard
17.1. k9s
https://k9scli.io/, 基于 Terminal 的轻量级 UI
17.2. kuboard
https://github.com/eip-work/kuboard-press 面板, 中文优先
17.3. kubernetes-dashboard
https://github.com/kubernetes/dashboard
# install
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/master/aio/deploy/recommended.yaml
# start
kubectl proxy
# start in background
kubectl proxy >/dev/null &
# create administrator
kubectl apply -f https://raw.githubusercontent.com/gotok8s/gotok8s/master/dashboard-admin.yaml
# and token
kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep kubernetes-dashboard-admin | awk "'{print $1}'")
# visit
http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/
17.4. kubesphere (推荐)
打通 devops 全套流水线, 对 cluster 要求高 https://github.com/kubesphere/kubesphere
(kuboard 也行, 对 cluster 要求不高)
https://www.zhihu.com/question/348609092 rancher 和 kubesphere 对比
https://www.bilibili.com/video/BV1cL4y167GV 视频教程
18. rancher
部署和管理 k8s 集群
19. Harbor
Harbor 是由 VMware 公司中国团队为企业用户设计的 Registry server 开源项目 (镜像仓库, 类似 docker hub)
20. Helm
来自 CNCF, 使用 helm chart 一键拉起整套环境(第三方部署k8s应用的工具). 也可以使用其应用商店, 一键部署别人写好的软件集群
Helm把Kubernetes资源(比如deployments、services或 ingress等)打包到一个chart中,而chart被保存到chart仓库。通过chart仓库可用来存储和分享chart。Helm使发布可配置,支持发布应用配置的版本管理,简化了Kubernetes部署应用的版本控制、打包、发布、删除、更新等操作。
20.1. How to create helm chart
We can use helm create <chart-name> to create a default chart template, 该命令默认会创建一些 k8s 资源定义的初始文件,并且会生成官网推荐的目录结构
helm create hello-helm
.
├── Chart.yaml
├── charts
├── templates // we can put our resource yml files into this folder, then our code can be put into the root path
│ ├── NOTES.txt
│ ├── _helpers.tpl
│ ├── deployment.yaml
│ ├── hpa.yaml
│ ├── ingress.yaml
│ ├── service.yaml
│ ├── serviceaccount.yaml
│ └── tests
│ └── test-connection.yaml
└── values.yaml
values.yml is used to define the env vars, we can extract the vars from cofigMap and then put the vars into this file.
好处是可以将所有可变的参数定义在 values.yaml 文件中,使用该 helm charts 的人无需了解具体 k8s 的定义,只需改变成自己想要的参数,即可创建自定义的资源!
for example:
# values.yml
application:
name: hellok8s
hellok8s:
image: guangzhengli/hellok8s:v6
replicas: 3
message: "It works with Helm Values[v2]!"
database:
url: "http://DB_ADDRESS_DEFAULT"
password: "db_password"
nginx:
image: nginx
replicas: 2
we can change the configMap like this:
# hello-k8s-configmap.yml
apiVersion: v1
kind: ConfigMap
metadata:
# 意思是从 values.yaml 文件中获取 application.name 的值 hellok8s,拼接 -config 字符串,
# 这样创建出来的 configmaps 资源名称就是 hellok8s-config。
name: {{ .Values.application.name }}-config
data:
DB_URL: {{ .Values.application.hellok8s.database.url }}
change secret yml like this:
# hellok8s-secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: {{ .Values.application.name }}-secret
data:
# 通过 b64enc 方法将值 Base64 编码
DB_PASSWORD: {{ .Values.application.hellok8s.database.password | b64enc }}
and change deployment like this:
# hello-k8s-deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Values.application.name }}-deployment
spec:
replicas: {{ .Values.application.hellok8s.replicas }}
selector:
matchLabels:
app: hellok8s
template:
metadata:
labels:
app: hellok8s
spec:
containers:
- image: {{ .Values.application.hellok8s.image }}
name: hellok8s-container
env:
- name: DB_URL
valueFrom:
configMapKeyRef:
name: {{ .Values.application.name }}-config
key: DB_URL
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: {{ .Values.application.name }}-secret
key: DB_PASSWORD
- name: NAMESPACE
# Helm 的内置对象
value: {{ .Release.Namespace }}
- name: MESSAGE
value: {{ .Values.application.hellok8s.message }}
20.2. helm chart 的打包发布
这里一 使用 github pages 存储为例
打包发布到 https://artifacthub.io/ (类似 dockerhub)
20.2.1. 手动打包发布
helm package <char name> # 将chart目录打包到chart归档中。
helm repo index . # 命令可以基于包含打包chart的目录,生成仓库的索引文件 index.yaml。
# 指定包进行安装使用
helm upgrade --install *.tgz
# or
helm upgrade --install hello-helm hello-helm-0.1.0.tgz
20.2.2. 利用 github action 自动打包发布
使用 char-release-action 自动发布 (该 action 会默认生成 helm chart 发布到 gh-pages 分支上)
ci.yml
name: Release Charts
on:
push:
branches:
- main
jobs:
release:
# depending on default permission settings for your org (contents being read-only or read-write for workloads), you will have to add permissions
# see: https://docs.github.com/en/actions/security-guides/automatic-token-authentication#modifying-the-permissions-for-the-github_token
permissions:
contents: write
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v2
with:
fetch-depth: 0
- name: Configure Git
run: |
git config user.name "$GITHUB_ACTOR"
git config user.email "$GITHUB_ACTOR@users.noreply.github.com"
- name: Install Helm
uses: azure/setup-helm@v1
with:
version: v3.8.1
- name: Run chart-releaser
uses: helm/chart-releaser-action@v1.4.0
with:
charts_dir: helm-charts
env:
CR_TOKEN: "${{ secrets.GITHUB_TOKEN }}"
20.3. 基本命令使用
# Chart 仓库其实就是一个带有index.yaml索引文件和任意个打包的 Chart 的 HTTP 服务器而已
# 可以利用 Github pages 搭建自己的仓库
#
# stable https://kubernetes-charts.storage.googleapis.com the offical repo from google
#
# Repos provided by Microsoft
# stable: http://mirror.azure.cn/kubernetes/charts/
# incubator: http://mirror.azure.cn/kubernetes/charts-incubator/
#
# provied by bitnami
# bitnami https://charts.bitnami.com/bitnami
#
# aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
# ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo list
helm repo remove <repo name>
helm repo add <repo name> <url>
helm repo update
# search from local added repo
helm search repo [chart name]
# search from helm hub
helm search hub [chart name]
# 查看一个 chart 的详细信息
helm inspect stable/mysql
# Chart name usually consists of repo_name + / + sub_name, eg. stable/mysql
# 安装 chart 会创建一个新 release 对象, 通过 --name 指定名字
# -f config.yaml 指定自定义配置文件
helm install [-f config.yaml] <char name> [--name <release name>]
# or
helm install <release name> <chart name> [--version 0.1.0]
# or
# 自己制作好 chart 后, 在 helm chart 目录下执行安装, 会创建好 resources
helm upgrade --install hello-helm --values values.yaml .
# 跟踪 release 状态或重新读取配置信息
helm status <release name>
# 查看 chart 上可配置自定义的选项
# 通过 yml 格式定义配置如 config.yml后,
# 可 helm install -f config.yaml stable/mysql --name mydb
# 亦可 --set persistence.enabled=false 来自定义配置
helm inspect values
# 更新/升级 (config.yml 中就是更新的内容)
helm upgrade -f config.yaml <release object> <chart name>
# 查看 已经安装的 charts list (即已经 release 的对象), 包括已经删除的
helm ls [--all]
# 删除
# 不代表就完全删除了
# 由于 Helm 保留已删除 release 的记录,因此不能重新使用 release 名称。(如果 确实 需要重新使用此 release 名称,则可以使用此 –replace 参数,但它只会重用现有 release 并替换其资源。)
# --purge 彻底删除
helm delete <release name> [--purge]
# 显示被删除掉 release
helm list --deleted
helm uninstall <chart name>
20.4. rollback
# 先查看历史
helm history <release object name>
# 比如, 我们对 values.yml 做了修改
# 更新 k8s 资源
helm upgrade --install hello-helm --values values.yaml .
# 发现更新有问题, 回滚上一个版本 (回滚后 REVISION 版本都会增大到 3 而不是回滚到 1)
helm rollback hello-helm 1
20.5. 多环境
create values-dev.yaml
# 可以多次指定'--values 或者 -f'参数,最后(最右边)指定的文件优先级最高
# 这里最右边的是 values-dev.yaml 文件,所以 values-dev.yaml 文件中的值会覆盖 values.yaml 中相同的值
# -n dev 表示在名字为 dev 的 namespace 中创建 k8s 资源
helm upgrade --install hello-helm -f values.yaml -f values-dev.yaml -n dev .
# 还可以再 cmd 中临时设置 values (此方法在 CICD 中经常用到。)
helm upgrade --install hello-helm -f values.yaml -f values-dev.yaml \
--set application.hellok8s.message="It works with set helm values" \
-n dev .
20.6. arkade
https://github.com/alexellis/arkade
使用arkade 可以简化我们部署charts 以及app 到k8s 集群中
curl -sLS https://dl.get-arkade.dev | sudo sh
arkade install - install an app
arkade update - update arkade
arkade info - the post-install screen for an app
21. reference materials
https://github.com/chaseSpace/k8s-tutorial-cn/tree/main https://github.com/guangzhengli/k8s-tutorials https://jp.v2ex.com/t/821329
https://github.com/techiescamp/kubernetes-learning-path https://github.com/guangzhengli/k8s-tutorials
https://www.bilibili.com/video/BV1Ja4y1x748 视频教程 https://edu.aliyun.com/roadmap/cloudnative?from=timeline