Rust 笔记🌈
- 1. 简单介绍
- 2. 开发环境配置
- 3. 标准库
- 4. 对比 2018
- 5. 语法
- 5.1. 注释
- 5.2. 变量赋值
- 5.3. 基本数据类型
- 5.4. 字符串
- 5.5. 集合
- 5.6. 类型转换
- 5.7. 所有权
- 5.8. 生命周期参数
- 5.9. 引用
- 5.10. 裸指针
- 5.11. 智能指针
- 5.12. 函数
- 5.13. 闭包
- 5.14. 条件循环
- 5.15. 泛型
- 5.16. trait
- 5.17. 元组
- 5.18. 结构体
- 5.19. 枚举
- 5.20. match 模式匹配
- 5.21. 错误处理
- 5.22. io
- 5.23. 面向对象 oop
- 5.24. 子进程
- 5.25. 反射
- 5.26. 宏
- 6. unsafe 屏蔽内存安全检查
- 7. 内存管理
- 8. 工程管理 模块
- 9. 单元测试
- 10. 交叉编译 and 条件编译
- 11. 并发
- 12. 异步并发
- 13. 简单文件系统
- 14. 网络编程
- 15. 消息中间件
- 16. 游戏开发
- 17. 爬虫
- 18. rpc 框架
- 19. 编写代理
- 20. 开发微信小程序-web 游戏
- 21. 第三方 crates
- 21.1. 事实上的标准库
- 21.2. markdown
- 21.3. 桌面开发
- 21.4. 视频处理
- 21.5. 图片处理
- 21.6. 游戏开发三方库
- 21.7. 系统信息
- 21.8. web 开发
- i18n
- 21.9. 序列化反序列化
- 21.10. 读写数据
- 21.11. 增强工具
- 21.12. 授权 Authorization
- 21.13. 日志系统
- 21.14. 文本解析器 parser
- 21.15. lazy static 延迟初始化
- 21.16. 电子书
- 21.17. 命令行程序
- 21.18. 异步编程
- 21.19. websocket
- 21.20. 缩小体积
- 21.21. http client
- 21.22. 容错运行时
- 21.23. 监控
- 21.24. 电子邮件
- 21.25. 分发工具
- 21.26. 并发编程
- 21.27. gui 图形库
- 可视化库
- 21.28. 底层网络 api
- 21.29. 正则
- 21.30. 随机
- 21.31. 搜索引擎
- 21.32. 开源集合容器
- 其他语言引擎
- 22. 开源项目
- 23. 参考链接
1. 简单介绍
1.1. Pros and Cons
Pros
- 在没有 GC 的加持下, 从语言层面实现了内存安全 (当然了, 代价就是引入了生命周期, 所有权机制...)
- 诞生的晚, 语言特性博采众长, 语法优美富有表现力 (我想这是很吸引人的一点)
- 如吸收了 scala中的Option,Some,None;
- golang中的初始化语法,channel
- js的async await
- 同时和其他语言的交互更方便, ffi 更容易使用....
Cons
- 编译特别慢, 尤其和老对手 go 比较
- 语法复杂, 特别是夹杂了生命周期的语法后, 代码特别难读
- 宏的语法很奇怪, 比如
#[cfg(all(not(baremetal), any(feature = “hazmat”, feature = “debug_print”)))], 使用‘=’来表示等价而不是赋值 - 允许变量重复定义(就是变量名相同, 但是类型不同)
我觉得是不好的设计; 官方说法是说为了可以在类型转换的时候方便地命名变量, 但是这样真的增加了阅读代码的心智负担
这个点好像有解: 开clippy lint可以禁掉
- if let语法糖, 存在一个语义不一致的问题
if和let都分别有各自的意思,if后面只能跟bool,let表达式并不evaluate成bool类型,这里的if let实现的是pattern match的功能,虽然let也可以用来pattern match,但是和if原本的语义不协调, 可以说设计的不够好
1.2. 架构
好的架构需要有清晰的概念, 软件史上优雅的架构设计通常有优雅的概念:
- socket
- stream /flow
- pipe
比如说, 现在需要对输入的一段文本统计某个单词的个数, 那么首先需要进行切割, 这个动作可以抽象出一个概念, 叫做 分词(tokenize), 然后是对每个词做处理, 这个处理可能是线性的, 也可能是并行的, 这个概念叫做 map ...
好的架构有定义清晰的接口
好的架构要能够延迟决策
- 函数是代码块的延迟绑定
- 类型是值的延迟绑定
- 泛型是类型的 延迟绑定
- 泛型函数是函数的延迟绑定
- 配置是业务逻辑的 延迟绑定
- 用户代码是延迟绑定的最高表现形式, 比如 nginx
1.3. 优点 对比
高性能: 零成本抽象
安全性: 所有权系统几乎解决了野指针, 强大的类型系统
表达力
生态工具完备: 自带测试, cargo 工具
https://opensource.com/article/20/5/rust-java 为什么java -> rust
1.4. 思想
明确 : 有很多其他语言像 Python, java, 为了照顾初学者他会把很多基本的概念隐藏在语法的后面, 比如每一条语句的变量分配, 在堆还是在栈执行, 都被屏蔽了, 在做一些性能优化, 和其他语言进行交互就会暴露问题
零成本抽象(zero cost abstract): (编译期间即可编译成机器码, 运行时没有开销), 没有 runtime 和 gc, 和 c 无缝交互, 比如 future 就是一个很漂浪的抽象
全能: 从系统层到 web 层, 都可以使用 rust 开发
1.5. 语义 概念
- 范式: 面向对象 , 函数式
- 语义: 所有权, move, copy, 借用, lifecycle, drop
- 类型系统: 泛型, trait, 多态, 类型推断
- 内存管理: heap, stack, raii
1, 2, 3 点涉及到开发者的操作, 2,3,4 编译器操作
2. 开发环境配置
2.1. install
git 环境支持
https://www.rust-lang.org/tools/install
会自动安装 cargo
安装完成后退出再次进入 terminal, rustc 等命令自动加入 path 了
给nightly通道用户的小提示:在更新rust之后使用cargo-sweep来帮助你清理垃圾 对于nightly通道的用户来说,通常在使用过程中会伴随着频繁的升级你的rust版本,而对于日常维护的项目,如果你升级了rust版本之后,target编译文件夹里面会生成多个版本的编译文件。这个时候就是使用cargo sweep的时候了,它会帮你清理掉除了当前版本以外的target目录下多余的文件。
用例: cargo sweep -i -r -v ~/src
-i 是开启保留~/src目录下target文件夹内当前电脑上已安装rust版本的编译文件。 -r 是开启递归(recursively)搜索 -v 是开启详细(啰嗦模式,开启之后会告诉你它干了啥。) 如果你的电脑上没有cargo sweep,可以用以下命令安装: cargo install cargo-sweep
Read More: https://www.reddit.com/r/rust/comments/jfdiao/tip_for_nightly_users_use_cargosweep_after/
2.2. 命令行工具使用
rustc --version
# 编译单个文件, 生成 xxx 可执行文件
rustc <xxx.rs>
# 编译 运行 dry.rs 下的 test mod, 无需 main函数
rustc --test dry.rs && ./dry
# 管理 rust 版本,
rustup update
# rust 有 stable (默认)、nightly 版本之分
rustup install nightly
# 当前项目下生效
rustup override set nightly
rustup override set stable
# 设置默认值, 对全局所有项目生效
rustup default stable
rustup default nightly
rustup default # show current version
2.3. IDE
vscode + rust-analyzer + CodeLLDB (debug, format) + even better toml (toml support) + crates (view crate version) + advanced-new-file + error lens (show error msg in editor) + github copilot + idea keybindings
clion/idea + rust 插件 + toml 插件 + NativeDebug插件
其他代码提示配置: (推荐 vscode + 插件, 就无需如下的配置了)
# https://www.jianshu.com/p/c952db541d79
# 代码提示
cargo install racer
# 如果不成功, 升级到 nightly
rustup install nightly
# 如果报错,则需要切换到nightly版本的编译器
# 然后再次 安装 racer
rustup default nightly
# 或者 直接
cargo +nightly install racer
# 代码分析
rustup component add clippy
2.4. 配置国内镜像
https://www.cnblogs.com/dhcn/p/12100675.html
[registry]
token = "xxx crate.io token" # 注册账号后由网站颁发, 用于发布包
# 放到 `$HOME/.cargo/config` 文件中
[source.crates-io]
registry = "https://github.com/rust-lang/crates.io-index"
# 替换成你偏好的镜像源
replace-with = 'rustcc'
#replace-with = 'ustc'
# 清华大学
[source.tuna]
registry = "https://mirrors.tuna.tsinghua.edu.cn/git/crates.io-index.git"
# 中国科学技术大学
[source.ustc]
registry = "git://mirrors.ustc.edu.cn/crates.io-index"
# 上海交通大学
[source.sjtu]
registry = "https://mirrors.sjtug.sjtu.edu.cn/git/crates.io-index"
# rustcc社区
[source.rustcc]
registry = "git://crates.rustcc.cn/crates.io-index"
# 命令别名
[alias]
b = "build"
t = "test"
r = "run"
rr = "run --release"
ben = "bench"
space_example = ["run", "--release", "--", "\"command list\""]
3. 标准库
3.1. path 路径
/// 路径
///
/// Path 可从 OsStr 类型创建
///
/// Path 分为两种:posix::Path,针对 类 UNIX 系统;以及 windows::Path,针对 Windows。
/// prelude 会选择并输出符合平台类型 的 Path 种类。(prelude 是 Rust 自动地在每个程序中导入的一些通用的东西)
///
/// Path 在内部并不是用 UTF-8 字符串表示的,而是存储为若干字节(Vec<u8>)的 vector。
/// 因此,将 Path 转化成 &str 并非零开销的(free),且可能失败(因此它 返回一个 Option)
///
fn path_demo() {
println!("-------------path_demo-------------");
use std::path::Path;
let path = Path::new(".");
// 路径是否存在
Path::new("/etc/hosts").exists()
// 或者
fs::metadata(path).is_ok()
// `display` 方法返回一个可显示(showable)的结构体
let display = path.display();
println!("path = {}", display);
// `join` 使用操作系统特定的分隔符来合并路径到一个字节容器,并返回新的路径
let new_path = path.join("a").join("b");
// 将路径转换成一个字符串切片
match new_path.to_str() {
None => panic!("new path is not a valid UTF-8 sequence"),
Some(s) => println!("new path is {}", s),
}
}
3.2. 时间
fn time_demo() {
let start = SystemTime::now();
for _ in 0..10000000 {
let _a = "hello".to_string();
}
println!("{} ms", SystemTime::now().duration_since(start).unwrap().as_millis());
}
4. 对比 2018
4.1. nll
// nll 特性
// 2015 edition 的周期检查会认为 变量有效直到作用域结束
// 2018 edition 会分析代码, 确认变量后面不会用到, 则提前销毁变量
{
let mut x = 2;
let y = &mut x;
*y += 1; // 2018 edition 在这一步后, 销毁 y
println!("{}", x); // 2015 到这一步才销毁 y
}
// 非词法作用域生命周期 (Non-Lexical Lifetime, NLL
fn foo<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() % 2 == 0 {
x
} else {
y
}
}
fn main(){
let x = String::from("hello");
//2015 中 error, 2018 引入了 nll, 不报错
let z;
let y = String::from("world");
z = foo(&x, &y); // 2015 认为到这里 y 已经失效了, 所以报错, 实际这不符合直觉
println!("{:?}", z);
}
// nll 无法解决的问题
fn get_default<'r,K:Hash+Eq+Copy,V:Default>(map: &'r mut HashMap<K,V>,
key: K)
-> &'r mut V {
match map.get_mut(&key) { // -------------+ 'r
Some(value) => value, // |
None => { // |
map.insert(key, V::default()); // |
// ^~~~~~ ERROR // |
map.get_mut(&key).unwrap() // |
} // |
} // |
}
// 修正如下:
fn get_default2<'r,K:Hash+Eq+Copy,V:Default>(map: &'r mut HashMap<K,V>,
key: K)
-> &'r mut V {
if map.contains_key(&key) {
// ^~~~~~~~~~~~~~~~~~ 'n
return match map.get_mut(&key) { // + 'r
Some(value) => value, // |
None => unreachable!() // |
}; // v
}
// At this point, `map.get_mut` was never
// called! (As opposed to having been called,
// but its result no longer being in use.)
map.insert(key, V::default()); // OK now.
map.get_mut(&key).unwrap()
}
4.2. Raw identifier
// 利用 Raw identifier 将语言关键字用作函数名 (一般用于 FFI 中,用于避免 C 函数名和 Rust 的关键字或保留字重名)
fn r#match(needle : &str , haystack : &str) - > bool
4.3. 简化模式匹配
// match 模式匹配
fn main() {
let o = &Some("h".to_owned());
// 2015
// ref也是一种模式匹配,是为了 解构 &Some(ref s)中 s 的引用,避免其中的 s 被转移所有权 。
match o {
&Some(ref v) => println!("{}", v),
_ => (),
}
// 2018
//不 需要再使用引用操作符和 ref来进行解构了。在新的版本中 , match 匹配会自动处理这种情况
match o {
Some(v) => println!("{}", v),
_ => (),
}
}
4.4. main 函数可以返回 Result
// 在 Rust 2015版本中, main 函数并不能返回 Result<T E>。但是在实际开发中, 二进制 可执行库也需要返回错误, 比如, 读取文件的时候发生了错误, 这时需要正常退出程序。于 是在 Rust 2018 版本中,允许 main 函数返回 Result<T, E>了
4.5. impl trait 抽象类型
// 可 以静态分发的抽象类型 impl Trait
5. 语法
5.1. 注释
//! Hello Demo
//! 包注释
//! crate spec...
use std::io::Read;
use std::io;
use std::fmt;
use std::io::{stdout, BufWriter};
use std::fs::File;
///
///
/// main 方法的注释
///
/// ```
/// 支持 md
/// ```
fn main() {
println!("Hello, world!");
}
5.2. 变量赋值
5.2.1. 默认是不可变的
fn variables() {
let a = 12;
// 二次赋值不行
// 也就是说 a 是不可变变量
// a = 10;
// 但是能二次绑定, 重影/遮蔽(Shadowing)
// 这里的 a 和之前的 a 没关系, 甚至类型都能改变
let a = 11;
println!("a = {}", a);
let a = "new a";
println!("a = {}", a);
// 可变变量
// 能够被二次赋值
let mut b = 10;
b = 33;
println!("b = {}", b);
// 这是不行的, 因为 b 已经被使用过了
// b = "bb";
// 手动指定类型, 无符号 64 位整型变量
// 如果没有声明类型,i 将自动被判断为有符号 32 位整型变量
let i: u64 = 12;
}
5.2.2. 字面量
// 字面量
//
// 带后缀的字面量,其类型在初始化时已经知道了。
let x = 1u8;
let y = 2u32;
let z = 3f32;
let s = "hello";
5.3. 基本数据类型
5.3.1. convert
https://stackoverflow.com/questions/41034635/how-do-i-convert-between-string-str-vecu8-and-u8
5.3.2. 值类型 and 引用类型
值类型是指数据直接存储在栈中的数据类型 ,一些原生类型,比如数值 、布尔值、结构体, 枚举等都是值类型。因此对值类型的操作效率一般比较高,使用完立即会被回收, 这些基本类型实现了 Copy trait, 赋值语句中会执行拷贝
引用类型将数据存储在堆中,而栈中只存放指向堆中数据的地址, 如数组, 字符串; 因此对引用类型的操作效率一般比较低
5.3.3. 常量 静态变量
// 常量, 静态变量: 在全局声明常量 or 变量
// 需要手动指定类型
// 区别/异同:
// - 都是在编译期求值的,所以不能用于存储需要动态分配内存的类型,比如 HashMap, vec
//
// - 静态变量有固定的内存地址 (分配在静态存储区), 可以是可变的 (用 mut 修饰), 可能有内存安全问题, 所以修改需要在 unsafe 中;
// - 常量没有固定的内存地址, 不可变 (会被内联, 在被用到的地方会被复制过去, 用不到内存地址)
// 普通常量 不能引用 静态变量
// 使用场景:
// 在存储的数据比较大、需要引用地址或具有可变性的情况下使用静态变量;否则,应该 优先使用普通常量
const MAX_POINTS: u32 = 100_000;
static LANGUAGE: &'static str = "Rust";//"string" 字面量默认生命周期就是 static 的
5.3.4. 数字
/// 对于 基本数据类型, 数据的克隆, 移动都是在栈上, 无需存储到堆中
fn basic_types() {
// 整型
// 占据 8 bit
const A: i8 = -2; // 有符号
const B: u8 = 2; // 无符号
// const b: u8 = -2; // 错误
// 占据 16 bit
// i16 u16
// 占据 32 bit
// i32 u32
// 64 bit
// i64 u64
// 128
// i128 u128
// arch 类型
// isize usize
//长度取决于所运行的目标平台,如果是 32 位架构的处理器将使用 32 位位长度整型。
const C: i16 = 10_000; // 10进制
const D: i16 = 0xff; // 16进制
const E: i16 = 0o77; // 8 进制
const F: i16 = 0b1111_0000; // 二进制
// 浮点数
let x = 2.0; // 默认 f64
let y: f32 = 3.0; // f32
// 相关函数
i32::min_value();-----2147483648
max_value()
// https://cloud.tencent.com/developer/article/1518453
5.3.5. 布尔值 字符 字节
// 布尔值, 类型 bool
let is_a = true;
// 字符, 单引号
//4 个字节, 支持中文
const CC: char = 'c';
let heart_eyed_cat = '😻';
// 字节字面量, 如 b'*' 表示 42u8
const G: u8 = b'A'; // 字节, 只能 u8 类型
const n: u8 = b'\n';
5.3.6. 数组
// 对于原始固定长度数组,只有实现 Copy trait 的类型才能作为其元素 ,也就是说,只有 可以在栈上存放的元素才可以存放在该类型的数组中 (只有确定大小类型(sized type)的实例才可以放到栈上,也就是,可以通过传值的方式传递)
// 不确定大小类型(unsized tpe)的实例不能放到栈上而且必须通过传引用的方式传递
// 可以自动推断类型
let a = [1, 2, 3, 4, 5];
// a 是一个长度为 5 的整型数组
let b = ["January", "February", "March"];
// b 是一个长度为 3 的字符串数组
// 明确指定类型, 数组类型可以通过 [T, N] 明确指定, T 为元素类型, N 为 个数; 如 [u8; 4] 这是静态类型 (因为已知大小了)
// [u8] 只能是动态大小类型, for don't know the size
let c: [i32; 5] = [1, 2, 3, 4, 5];
// c 是一个长度为 5 的 i32 数组
let d = [3; 5];// 使用默认类型 i32, 元素都为 3, 个数为 5 个
// 等同于 let d = [3, 3, 3, 3, 3];
let d = [3u8; 5];// 指定类型为 u8
// 数组访问
let first = a[0];
let second = a[1];
a[0] = 123; // 错误:数组 a 不可变
let mut a = [1, 2, 3];
a[0] = 4; // 正确
// 数组遍历
for ele in a.iter() {
println!("{}", ele);
}
//
// 连接两个 array 可以使用 join
// match 语法
// 通过匹配数组的不同元 可以实现指定的功能 。
// 挑选出以 3 结尾和第 二个元素为 2 的数组。
fn pick(arr: [i32; 3]) {// 这个有限制, 参数数组的元素个数不可变, 必须为 3
match arr {
[_, _, 3] => println!("ends with 3"),
[a, 2, c] => println!("{:?}, 2, {:?}", a, c),
// match匹配的最后一个分支,必须使用通配符或其他变量来穷尽枚举
[_, _, _] => println!("pass!"),
}
}
// 变长参数
// 利用数组切 片就可以模拟变长参数的函数
fn sum(num: &[i32]) { // 原素个数可变
match num {
[one] => println!(" at least two"),
[first, second] => println!("{:?} + {:?} = {:?} ", first, second, first+second),
_ => println!("sum is {:?}", num.iter().fold(0, |sum, i| sum + i) ),
}
}
fn main() {
sum(&[1]);
sum(&[1, 2]);
sum(&[1, 2, 3]);
sum(&[1, 2, 3, 5]);
}
// 二分查找
// 根据元素查找索引
if let Ok(9) = arr.binary_search(&13) {}
// 等价
arr.binary_search_by(|x| x.cmp(&13))
// binary search by_key
let s = [0, 1, 1, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55];
assert_eq!(s.binary_search(&13), Ok(9));
assert_eq!(s.binary_search(&4), Err(7));
let r = s.binary_search(&1);
assert!(match r { Ok(1...4) => true, _ => false, });
let seek = 13;
assert_eq!(
s.binary_search_by(|probe| probe.cmp(&seek)),
Ok(9)
);
let s = [(0, 0), (2, 1), (4, 1), (5, 1), (3, 1),
(1, 2), (2, 3), (4, 5), (5, 8), (3, 13),
(1, 21), (2, 34), (4, 55)];
assert_eq!(
s.binary_search_by_key(&13, |&(a,b)| b),
Ok(9)
);
5.3.7. Range 范围
// /包头不包尾
(1..5) <=> std::ops::Range {start: 1, end: 5}
(1..=5) <=> std::ops::RangeInclusive::new(1, 5)
(3..6).sum()
for i in 0..4 {
}
for i in 0..=4) {
}
5.3.8. 切片
///切片
///
/// 切片是对原始数据集合的部分引用, 没有原始 数据集合 的所有权 (原始数据集合可能是 数组, Vec);无法修改原始值
///
/// 若原始值 为 T, 则 切片类型为 &[T] or &mut[T]
///
/// ..y 等价于 0..y (包头不包尾巴)
/// x.. 等价于位置 x 到数据结束
/// .. 等价于位置 0 到结束
///
///
///
fn slice_vec() {
// 字符串切片
let s = String::from("broadcast");
let part1 = &s[0..5];// 截取子串, 字符串切片就是 &str 类型
let part2 = &s[5..9];
println!("{}={}+{}", s, part1, part2);
// 被切片引用的字符串禁止更改原始值
let mut s = String::from("xxxxxx");
let slice = &s[0..3];
s.push_str("yes!"); // 错误
//数组切片
let arr = [1, 3, 5, 7, 9];
let part = &arr[0..3];
for i in part.iter() {
println!("{}", i);//1, 3, 5
}
// 两个 const fn 方法: len(), is_empty()
// 通过 &mut 定义可变切片
let arr = &mut [1,2,3];
arr[1] = 0;
// 动态数组转切片
let arr = &vec![1,2,3][..];
}
5.3.9. str 字符串切片
// str 是典型的动态大小类型 (DST), 编译期不可知大小, 分配在堆上
//所以编译器要求必须以不可变借用的形式在代码中存在 即 &str, 这个借用的大小是确定的(一个指针+长度), &str 存储在栈上, 对应的 str 存在 堆上
//
// 字符串字面量是特殊的 str, 特殊在其具有静态生命周期, 必须以类型 &'static str 接收
//
//fat pointer(胖指针): 包含 DST 的地址信息 和 长度的指针, &str 即胖指针
let ss = "hello world";
let ptr = ss.as_ptr();
let s = unsafe {
let slice = std::slice::from_raw_parts(ptr, ss.len());
std::str::from_utf8(slice).unwrap()
// or
// turns invalid UTF-8 bytes into � and so no error handling is required.
let buf = &[0x41u8, 0x41u8, 0x42u8];
let s = String::from_utf8_lossy(buf).to_string();
};
if ss == s {
println!("equal");//equal
}
5.3.10. 原生指针 raw pointer
分为 不可变 raw pointer 和 可变 raw pointer
指针不同于 引用, 指针类型 *T, 引用类型 &T
#![feature(never_type)]
let mut a = 10;
let a_ptr = &mut a as *mut i32;
let b = Box::new(20);
let b_ptr = &*b as *const i32;
unsafe {
*a_ptr += *b_ptr;
}
println!("{:?}", a);//30
5.3.11. never 类型 感叹号
// 底类型 bottom type
// BangType
//
// Rust 中有很多种情况确 实没有值,但为了类型安全,必须把这些情况纳入类型系统进行统一 处理
//
// 发散函数 (Diverging Function ): 永远不会有返回值的函数, 如 panic! 或者 std::process: :exit ...
// continue 和 break 关键字
//loop循环
// 空枚举,比如 enumVoid{}
# ! [feature (never_type)]// 需要支持
fn foo() -> i32 {
// !表示永远不会有返回值的类型
let x: ! = {
return 11;// 直接foo函数返回退出了, 所以 x 永远不会有返回值, 是 ! 类型
};
// panic 宏在 match 分支中使用时, 即使没有返回和其他分支相同的类型, 也没报错, 为什么?
// 因为返回 了 ! 类型, (never 类型可以转为任何类型)
// 空枚举的用法场景:
enum Void {}
let res: Result<i32, Void> = Ok(11);
let Ok(num) = res;//当然这里也可以用 if let 语句处理
}
5.4. 字符串
5.4.1. 几种字符串区别
/// 字符串
///
/// - str 表示固定长度的字符串, 属 于动态大 小 类型 (DST),保证 有效 UTF-8 , 在编译期并不能确定其大小,所以在程序中最常见到的是 str 的切片 (Slice)类型 &str。
// &str 表示字符串字面量, 是引用类型; 字符串切片就是 &str, 和程序代码段存储在一起(在编译期间地址就知道了), 执行的是复制语义
///
/// - String 类型, 长度可变, 可修改, 存储为由字节组成的 vector(Vec<u8>),但保证了它一定是一个有效的 UTF-8 序列, 字符序列分配在堆, 执行的是移动语义
///
/// String 有一个字符开始位置属性 ptr, 和一个字符串长度属性 len, 和堆分配的容量 capacity, 这些属性位于 栈, 实际字符序列存在 堆
/// str 有 ptr 和 len, 属性, 内容都在 栈
//
// - CStr, 表示由C分配而被Rust借用的字符串, 一般用于和C语言交互。
// - CString, 表示由 Rust 分配且可以传递给 C 函数使用的 C 字符串 ,同样用 于和 C 语言交互。
//
// - OsStr, 表示和操作系统相关的字符串。这是为了兼容 Windows系统。
// - OsString,表示 OsStr 的可变版本 。与 Rust 字符串可以相互转换
// - Path,表示路径,定义于 std::path模块中。 Path包装了 OsS
// - PathBuf. ft~ Path 配对, 是 Path 的可变版本 。 PathBuf包装了 OsString。
///
5.4.2. 常用方法
fn str_string() {
// 字符串转义
// 长字符串
let long_string = "String literals
can span multiple lines.
The linebreak and \' indentation here
can be escaped too!";
println!("{}", long_string);
b' ' 表示 空格字符
let str_value: &'static str = "1234";// 字符串切片
//简单写法为
let str_value = "1234";
let s = string::new() // 此时还并未在堆上分配空间
let str1 = String::from("hello");
// 指定堆容量
let s = String : :with_capacity (20)
// 再次分配容量
s.reserve(lO)
let one = 1.to_string(); // 整数到字符串
let float = 1.3.to_string(); // 浮点数到字符串
let slice = "slice".to_string(); // 字符串切片到字符串
// 新增 添加
//定义一个可变字符串,并对其进行修改
let mut string_value: String = "1111".to_string();
// 或者
// let string_value = String::from("222");
string_value.push_str("333");// 添加字符串切片
string_value.push('!'); // 添加字符
// 插入
s.insert(0, 'f’)
s. insert_str(O,”bar”)
// 连接
// String 类型的字符串也实现了 Add<&str> 和 AddAssign<&str>两个 trait,这意味着可以使用“+”和“+=”操作符来连接字符串
// 操作符 右边的字符串必须为切片类型 (&str)
// 替换
//
string.replace("old_str", "new str");
// 删除
s .remove (3) //指定位置
s.pop()//最后一个字符, 并且返回
s. truncate (3)//指定位置到末尾删除
s .clear( );//清空
s .drain (..beta_offset) .collect()// 截取源的指定范围并返回, 源会改变, 只留下剩下的部分
s.drain(..)// 等价 clear, 截取源的全部, 源变空
// trim 首尾去除
//
let chars_to_trim: &[char] = &[' ', ','];
// 去除 string 首尾的字符, 这些字符在 chars_to_trim 中指定
let trimmed_str: &str = string.trim_matches(chars_to_trim);
// 查找
// 标准库中并没有提供正则表达式支持,这是因为正则表达式算是外部DSL, 如果 直接将其引入标准库中,则会破坏 Rust的一致性
// 第三方包 regex
// Rust 中这里使用 的字符匹配算 法并非 KMP,而是它的变种双向( Two-Way)字符串匹配算法 ,该算法的优势在于拥有常量级的空间复杂度。它和 KMP 的共同点在于其时间复杂度也是 O(n)
//
// 存在性判断。 相关方法包括contains (支持 字符/字符串/谓词)、 starts_with (支持字符/字符串)、 ends_with
// 位置匹配 。相关方法包括 find、 rfind (从右边开始搜索, 支持谓词)。
// 分割字符串 。相关方法包括 split、rsplit、split_terminator(去掉数组last元素的多余)、rsplit_terminator、splitn (指定分割后的数组长度)、rsplitn。
// 捕获匹配, 返回数组。 相关方法包括 matchs、 rmatches、 match_indices (返回的是元组数组, 包含了索引)、 rmatch_indices。
// 删除匹配。 相关方法包括 trim(删除两头空格, 不能指定 pattern 参数), trim_left, trim_right , trim_matches(可指定 pattern 参数)、trim_left_matches、trim_right_matches。
// 替代匹配。 相关方法包括 replace、 replacen(指定替换字符的个数)
// 统计长度
// 字符 字节
//
let s = "hello";
//字节
let len = s.len();// 5, 字节数, 每个英文字符占位1字节
let s = "你好";
let len = s.len();//6, 因为中文是 UTF-8 编码的,每个字符长 3 字节
let s = "hello你好";
let len = s.bytes().count();//提供了 bytes 和 chars 两个方法来分别返回按字节 和按字符迭代的法代器
//字符
let len = s.chars().count();// 7, 统计字符数 (统计字符的速度比统计数据长度的速度慢得多)
//遍历字符
for c in s.chars() {
print!("{} ", c);
}
// or
let s: String = s.chars() .enumerate() .map(| (i, c) | {}).collect()
// 按索引访问字符
let mut result = s.into_bytes();//通过 into_bytes方法将字符串转换为 Vec<u8>序列
(0..bs.len()).for_each(|i| println!("index = {:?}, value = {:?}", i, char::from(bs[i])));
let new_s = String: :from_utf8(result).unwrap()
// 获取单个字符
let s = String::from("EN中文");
let a = s.chars().nth(2); //nth 函数是从迭代器中取出某值的方法,不要在遍历中这样使用!因为 UTF-8 每个字符的长度不一定相等
println!("{:?}", a);//Some('中')
// 指定索引范围来获取字符串切片
let v = String::from("hello");
let s: Some<&str> = v.get(0..1);
v.get_mut((xxx))
assert ! (!v .is_char boundary(4)) ;//验证某个索引位置是否为合法的边界, 因为可能某个字符占据了多个索引位置(string的方法默认都是按照字节来处理的, 也就是一个索引位置对应一个字节, 某些字符英文字符外的字符可能不止一个字节)
// 分割
let bool_s = s.is_char_boundary(12)
s.split_at(12)// 需要先检查索引是否是合法字符边界
// 空格分割, 逆序
let pangram: &'static str = "the quick brown fox jumps over the lazy dog";
for word in pangram.split_whitespace().rev() {
println!("> {}", word);
}
// 字符串分割成字符,排序并移除重复值
let mut chars: Vec<char> = pangram.chars().collect();
chars.sort();
chars.dedup(); //去重
// 获取字节 遍历字节
// as_bytes()
//
fn first_word(s: &String) -> usize {
// 字节数组, 一个英文字符占一个字节
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {// 如果是空格
return i;
}
}
s.len()
}
first_word(&"hello world".to_owned());// 5
5.4.3. 字符串转换
//
//
// 复杂类型的类型转换 相互转换 互转
//
// String => &str
let s1 = String::from("hello");
// 方法1
let s2 = &s1[..];
let ssss = &s1[..2];// 截取子串
// 方法2
let sss: &str = &s1.as_str();
//
// 方法3
// *s1 是 str 类型, &*s1 即为 &str 类型
let new_str = &*s1;
//
//
// &str -> String
let new_string = new_str.to_string();//to_string底层调用的String::from
let new_string1 = s2.to_string();
println!("new_string = {}, new_string1 = {}", new_string, new_string1);
// &str -> String
let string = "hello".to_owned(); //最常用, 吧 "hello"从栈转移到堆, to_owned 方法利用 &str 切片字节序列生成新的 String字符串 , to_string方法是对 String::from 的包装, 两者性能相当
// &str -> String
let _s: String = "hello".into();
// string -> T
// std::str模块中提供的 parse泛型方法来将字符串转换为指定的类型
// 底层是 FromStr::from_str
//T -> string
// format!()
let s = format!("{}", xxx);
// 和数字互相转换
let int_value = 5;
let string_value = int_value.to_string();//int to String
let back_int = string_value.parse::<i32>().unwrap();//String to int
5.4.4. 格式化
// 拼接
// 新加的字符串必须是 &str
//
let str1 = String::from("hello");
let str2 = String::from("world");
let str3 = str1 + "-" + &str2;
// or
let s = format!("{} - {}", str3, str2);
//
// 格式化输出
// 由一些宏(macro)负责输出,这些宏定义在std::fmt中
//
// 原理是: 必须实现 std::fmt::Display 这个trait提供的 fmt 方法
//
// format!():向字符串中输出格式化字符串。
// print()!:向标准输出打印字符串。
// println()!:向标准输出打印字符串,同时会打印一个换行符。
// eprint()!:向标准错误打印字符串。
// eprintln()!:向标准错误打印字符串,同时也会打印一个换行符
// 占位符
// {} -> Display
// {:?} -> Debug
// {:#?} -> 格式化的 Debug
// {:o} -> 八进制
// {:x} -> 十六进制小写
// {:X} 十六进制大写
// {:p} 指针地址
// {:b} 二进制
// {:e} 数字格式, 指数小写
// {:E} 指数大写
println!("hello {}", "world");
println!("{0} {1}", "hello", "world");
println!("{h} {w}", h = "hello", w = "world");
// 以二进制的格式打印数字
println!(
"{} of {:b} people know binary, the other half doesn't",
1, 2
);
// 右对齐宽度为6
println!("{number:>width$}", number = 1, width = 6);// '.....1'
// 使用字符0填充对齐的字符串
println!("{number:>0width$}", number = 1, width = 6);// '000001'
let s = format!("hello {}", "world");
println!("{}", s);
// 十六进制输出
format!("0x{:X}", 100); //-> "0xDEADBEEF"
// 八进制输出
format!("0o{:o}", 100); //-> "0o33653337357"
5.4.5. 调试打印复合类型 Debug Display
//调试
//
// fmt::Debug 类似 Display 这个 trait, 但是能够由 rust 自动推导实现, 无需手动实现
//
// fmt::Debug是Rust标准库已经定义好的,我们可以通过继承的方式,获得fmt::Debug的能力,
//即定义 struct 时 添加 #[derive(Debug)]
//其他的还有 #[allow(dead_code)] 用于屏蔽对未使用代码的警告
#[derive(Debug)]
struct DebugDemo(i32);
let debug_demo = DebugDemo(11);
println!("Debug - {:?}", debug_demo);
println!("{0:?}", debug_demo);// 等效
//
// fmt::Display 自定义打印
//是一个用于自定义格式化输出的接口
//
// 对于泛型容器, 如 Vec<T>, 需要自己实现fmt::Display, 或者直接 用fmt::Debug
//
struct DisplayDemo(i32);
impl fmt::Display for DisplayDemo {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "({})", self.0)
}
}
let display_demo = DisplayDemo(11);
println!("display - {}", display_demo);
5.4.6. 问号操作符 多次写
// "?" 问号操作符: 尝试解包, 返回值为 解包后的值, 有异常, 返回异常, 没有则继续后续代码
//
//考虑这种场景: 对一个结构体想实现 fmt::Display,但是其中的元素需要一个接一个地写出去,
//问题在于每个 write! 都要生成一个 fmt::Result。
//
//解决: write!(f, "{}", value)?; 多次写
// 对 `write!` 进行尝试(try),观察是否出错。若发生错误,返回相应的错误。
// 否则(没有出错)继续执行后面的语句。 同 try!(xxx)
//
//
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
// 使用元组的下标获取值,并创建一个 `vec` 的引用。
let vec = &self.0;
write!(f, "[")?;//多次写
// 遍历下标
for (count, v) in vec.iter().enumerate() {
// 对每个元素(第一个元素除外)加上逗号。
// 使用 `?` 或 `try!` 来返回错误。
if count != 0 { write!(f, ", ")?; }
write!(f, "{}", v)?;
}
// 加上配对中括号,并返回一个 fmt::Result 值。
write!(f, "]")
}
}
5.5. 集合
std::collections 下有四种集合
- 线性序列: Vec(向量), VecDeque (双端队列), LinkedList (链表)
- 映射表: hashmap(无序哈希表), BTreeMap(有序哈希表)
- 集合: hashset(无序集合), btreeset(有序集合)
- 优先队列: binaryHeap (二叉堆)
5.5.1. Vec 动态数组
/// 向量 Vec
/// 动态数组, 类似 java中的 ArrayList
///
///Vector数组天生就可以作 为先进后出(FILO)的栈结构使用
///
//
println!("Vector -------------------------------");
//一个 vector 使用 3 个词来表示:一个指向数据的指针,vector 的长度,还有它的容量。此容量指明了要为这个 vector 保留多少内存。
//vector 的长度 只要小于该容量,就可以随意增长;当需要超过这个阈值时,会给 vector 重新分配一段 更大的容量。
//
// 扩容: 自动按照 2 倍扩容
//
let vec: Vec<i32> = Vec::new(); // 创建类型为 i32 的空向量
// 预分配 10 个单位
// 真正分配 的堆内存 大 小 等于数组中元素类型所占字节与给定容量值 之积
Vee::with capacity(1O)
let vector = vec![1, 2, 4, 8]; // 通过数组和宏创建向量 // v: Vec<i32>
let v = vec![0; 10]; // ten zeroes
let mut vec_fixed: Vec<_>= (0..10).collect();
// 获取
println!("{:?}, v[0] = {}", vec, vec[0]);//下标必须是 usize 类型
// vec 转换 数组/切片
let arr = vec[..];
// 长度
vec.len();
// 添加, 删除
// 类似 栈
vec.push(6);//尾插
vec.push(7);
if let Some(x) = vec.pop() {// 尾部删除返回
println!("popped: {}", x);// 7
} else {
println!("None");
}
println!("after pop: {:?}", vec); // [6]
// 从 0 位置开始清除到末尾, 等同清空数据, 但是内存没有释放, 只是擦除了数据
vec . truncate (0);
// 清空
vec.clear()
// 释放空闲容量
vec.shrink_to_fit() //方法,预分配的堆内存被释放了
// 交换
v.swap(1, 3);
// 全部替换
// copy_from_slice 方法可以使用一个数组切片将原 vec 数 组 中的元素全部替换, 数组切片必须和原数组等长, 只支持实现 Copy 语义的元素
// clone_from slice方法的效果和 copy_仕om slice是等价的, 但它们的区别是, clone from slice 方法支持实现 Clone 的类型元素。
// 添加另外的 vector
let mut v2 = vec![100, 101];
vec.append(&mut v2);
println!("vec: {:?}", vec);
println!("v2: {:?}", v2);//v2: []
// 处理下标越界
match vec.get(7) { // 返回的是 Option<T>
Some(x) => println!("Item 7 is {}", x),
None => println!("Sorry, this vector is too short.")
}
// contains、 starts with和 ends with
// 迭代
// 迭代出的是元素引用
for ele in &vec {
println!("不可变引用: {}", ele);
}
// 可变迭代
for ele in &mut vec {
println!("可变引用: {}", ele);
// 此时可以修改元素
*ele *= 10;// 第一个* 表示根据地址取得值, 第二个*是运算符
}
// 带下标迭代
for (i, v) in vec.iter().enumerate() {
println!("{}: {}", i,v);
}
for ele in vec {
println!("本体: {}", ele);
}
// 类型推断
//
// 因为有类型说明,编译器知道 `elem` 的类型是 u8。
let elem = 5u8;
// 创建一个空向量(vector,即不定长的,可以增长的数组)。
let mut vec = Vec::new();
vec.push(elem);
// 啊哈 聪明!现在编译器知道 `vec` 是 u8 的向量了(`Vec<u8>`)。
println!("{:?}", vec);
// 转换
//
// slices 是 &[u8] 类型
let v: Vec<u8> = slices.to_vec()
let s: String = String::from_utf8(v).unwrap();
// Vec<String> -> Vec<&str>
let v7: Vec<&str> = v.iter().map(|s| s.as_ref()).collect();
let v4: Vec<&str> = v.iter().map(|s| s as &str).collect();
let v6: Vec<&str> = v.iter().map(|s| { let s: &str = s; s }).collect();
let v5: Vec<&str> = v.iter().map(|s| &s[..]).collect();
let v2: Vec<&str> = v.iter().map(|s| &**s).collect();
let v3: Vec<&str> = v.iter().map(std::ops::Deref::deref).collect();
5.5.2. 双端队列 VecDeque
// 是一种 同时具有 队列(先进先出)和栈 (后进先出)性质的数据 结构 。 双端队列中的元素可 以从两端弹出,插入和删除操作被限定 在队列的两端进行
// 内部主要维护一个环形缓冲区 (RingBuffer), 由两个指针和 一 个可增长数组组成 。 这两个指针分别为 头指针( Head Pointer)和尾指针( Tail Pointer)。 其中头指针永远指向应该写入数据 的位置,而尾指针永 远指 向可以读取的第一个元素
// 缓冲区溢出
// 假设缓冲区数组初始大小为8, 环形 缓冲区为空 时,两个指针都指向位置 0。当有新元素 插入时,如果 直接插入位置 0,则将用于写入数据 的 Head 指针指向位置 1, 而用于读取数据的 Tail 指针依 旧指向位置 0
// 当插入第 8 个元素时, Head 和 Tail 指针将再次重叠,
// 如果这时继续给缓冲区添加新元素 , 那么位置 。 处的数据将被 其他数据覆盖,这就会造成缓冲区溢出攻击; 为了避免这种情况,需要空出一个位置, 不能插入元素 , 这样才可以区分头和尾
// 要判断环形缓冲区是否为满状态,就必须看容量和大小的差是否为 l
5.5.3. 链表 Linkedlist
因为是双向列表, 所以提供了 push back 和 push front 两类方法,方便操作 此链表。也提供了 append 方法 , 可以用来连接两个链表
5.5.4. hashmap 无序哈希表
Key必须是可哈希的类型, Value必须是在编译期已知大小的类型
5.5.4.1. 哈希表基本使用
///HashMap 的键可以是布尔型、整型、字符串,或任意实现了 Eq 和 Hash trait 的其他类型
///HashMap 在占据了多余空间时还可以缩小 自己
///
///
///
fn hash_table() {
use std::collections::HashMap;
let mut map = HashMap::new();//不会预分配内 存。若始终不添加元素, 会编译报错, 编译器认为 map 没有初始化
HashMap::with_capacity(unit) //创建具有一定初始容量的 HashMap
// 从 vector 构造
let keys = vec!["a", "b"];
let values = vec![0, 1];
let m: HashMap<_, _> = keys.iter().zip(values.iter()).collect();
// 另一种初始化方法
let map: HashMap<char, i32> = vec![
('I', 1),
('V', 5),
('X', 10),
('L', 50),
('C', 100),
('D', 500),
('M', 1000),
]
.into_iter()
.collect();
// 插入
// 如果被插入的值为新内容,那么 `HashMap::insert()` 返回 `None`,
// 否则返回 `Some(被覆盖的 value)`
map.insert("color", "red");// 没有声明散列表的泛型,是因为 Rust 的自动判断类型机制。
map.insert("size", "10 m^2");
//不存在才插入值 red, 并且返回该值的可变借用, (一般的插入则是有则覆盖旧的值)
// or_insert_with(FnOnce) 传递一个可计算的闭包作为要插入的值, 闭包没有参数
// key()
map.entry("color").or_insert("red");// , 返回 "red" 的 &mut T
//删除
map.remove(&("Ashley"));
// 获取
//
// 接受一个引用并返回 Option<&V>
let one = map.get(&"color");
// or
let one = map["color"]
println!("one is a Option<&V> , {}", *(one.unwrap()));
// 可变获取(修改)
let mut map = HashMap::new();
map.insert(1, "a");
if let Some(x) = map.get_mut(&1) {
*x = "b";
}
// 是否包含
if !book_reviews.contains_key("rust book") {
println!("find {} times ", book_reviews.len());// 长度
}
// 迭代
for p in map.iter() {//迭代元素是表示键值对的元组
println!("{:?}", p);
}
for (k, v) in &map {// 元素为 (&'a key, &'a value) 对
println!("{}, {}", k, v);
}
// 通过keys和values方法可以分别单独获取HashMap中的键/值的迭代器
for key in book_reviews.keys() {
println!("{}", key);
}
for val in book_reviews.values() {
println!("{}", val);
}
// 统计句子中的单词个数
let text = "aa bb cc bb";
let mut counter = HashMap::new();
for word in text.split_whitespace() {
let count = counter.entry(word).or_insert(0);//
*count += 1;
}
for (word, count) in counter {
println!("{}, {}", word, count);
}
// 合并多个 HashMap
// 合并两个或多个 HashMap, 尽量使用 extend或其他迭代器适配器方式, 而不要用 for循环来插入 ,否则会带来性能 问题
map1.extend(map2);//本质上, 在 extend方法内部也将 HashMap转换为法代器进行操作
map1.into_iter().chain(map2).collect()//同样是通过 into_iter得到 Chain迭代器 然后操作
// 被添加的 map_ref 是个引用, 原始 map 不会丢失所有权
map1.extend(
map_ref.into_iter()
.map(|(k, v)| (k.clone(), v.clone()))
);
5.5.4.2. 复合类型作为 key
// 基础类型的 浮点数, 无法作为 key
// 复杂类型作为键 key, 必须实现 Hash和Eq trait
//
//f32 和 f64 没有实现 Hash,这很大程度上是由于若使用浮点数作为 散列表的键,浮点精度误差会很容易导致错误
//
//对于所有的集合类(collection class),如果它们包含的类型都分别实现了 Eq 和 Hash,
//那么这些集合类也就实现了 Eq 和 Hash。例如,若 T 实现了 Hash,则 Vec<T> 也实现了 Hash
//
//自定义类型可以轻松地实现 Eq 和 Hash,只需加上一行代码:#[derive(PartialEq, Eq, Hash)]
//
// Eq 要求你对此类型推导 PartiaEq。
#[derive(PartialEq, Eq, Hash)]
struct Account<'a>{
username: &'a str,
password: &'a str,
}
struct AccountInfo<'a>{
name: &'a str,
email: &'a str,
}
type Accounts<'a> = HashMap<Account<'a>, AccountInfo<'a>>;
fn try_logon<'a>(accounts: &Accounts<'a>,
username: &'a str, password: &'a str){
println!("Username: {}", username);
println!("Password: {}", password);
println!("Attempting logon...");
let logon = Account {
username: username,
password: password,
};
match accounts.get(&logon) {
Some(account_info) => {
println!("Successful logon!");
println!("Name: {}", account_info.name);
println!("Email: {}", account_info.email);
},
_ => println!("Login failed!"),
}
}
}
5.5.4.3. 哈希碰撞攻击
map 底层使用数组存储数据, 需要一个高效的 hash 函数均匀的将元素分散存储在 数组中
负载因子: 当前的默认扩容策略 为负载因子达到 0.9 时则进行扩容
Rust标准库实现的 HashMap, 默认的 Hash 函数算法是 SipHashl3o 另外,标准库还实现 了 SipHash24, SipHash算法可以防止 Hash碰撞拒绝服务攻击(Hash Collision DoS),这种 攻击是一种基于各语言 Hash 算法的随机性而精心构造出来的增强 Hash碰撞的手段,被攻击 的服务器 CPU 占用率会轻松地制升到 100%
如何解决哈希碰撞?
- 外部拉链法: 在数组的每个元素位置, 遇到碰撞后, 生长出一个链表, 但是有退化到单链表的风险
- 开放定址法: 在发生冲突时直接去寻找下一个空的地址, 开放定址法的优点在于计算简单、快捷,处理方便:缺点是它会 产生聚集 现象,并且删除元 素也会变得十分复杂(因为并不能真的删除, 否则会破坏寻址的正确性) 寻找下一个空地址的行为,叫作探测 (Probe)。依次 一 个个地 寻找 叫作 续性探测( Linear Probing), rust 采用这种
在线性探测时,如果遇到空桶, 则正常插入; 如果遇到桶己 经被占用 ,那么 就要看占用这个桶的键值对是经历 过几次 探测才被插入该位置 的, 如果该键值对的探测次数比当前待插入的键值对的探测次数少,则它属于“富翁”, 就把当前的键值对插入该位置,再接着找下一个位置来安置被替换的“富翁”键值对。 正是因 为这种“劫 富济贫 ”的思路,这种 算法才被称 为罗 宾汉算法。
5.5.5. BTreeMap 有序哈希表
基于 B 树的有序映射集实现,按 Key 排序
5.5.6. hashset 无序集合
// HashSet<K> BTreeSet<K>其实就是 HashMap<K, V>和 BTr巳eMap<K, V>把 Value 设置 为空元组的特定类型,等价于 HashSet<K, ()>和 BTreeSet<K, ()>
//
//散列集 HashSet
//
//union(并集):获得两个集合中的所有元素(不含重复值)。
// difference(差集):获取属于第一个集合而不属于第二集合的所有元素。
// intersection(交集):获取同时属于两个集合的所有元素。
// symmetric_difference(对称差):获取所有只属于其中一个集合,而不同时属于 两个集合的所有元素。
//
use std::collections::HashSet;
let mut a: HashSet<i32> = vec!(1i32, 2, 3).into_iter().collect();
let mut b: HashSet<i32> = vec!(2i32, 3, 4).into_iter().collect();
a.insert(4); // 如果值已经存在,那么 `HashSet::insert()` 返回 false
a.contains(&4);//是否存在
//并集
let c = a.union(&b).collect::<Vec<&i32>>();
5.5.7. BTreeSet 有序集合
5.5.8. 优先队列 BinaryHeap
使用 peek方法可以 取出堆中的最大值
5.6. 类型转换
5.6.1. 基本的类型转换
// 类型转换
//
//Rust 不提供原生类型之间的隐式类型转换(coercion),但可以使用 as 关键字进行显 式类型转换(casting)
//
println!("------类型转换--------------------------");
let decimal = 65.4321_f32; // 通过字面量直接声明类型
// 错误!不提供隐式转换
let integer: u8 = decimal;
// 可以显式转换
let integer = decimal as u8;
let character = integer as char;
5.6.2. 转换相关的 trait
//
//
// 其他转换相关的 trait
//
//from和into 方法是一对,实现了From trait就会自动反过来实现Into
// - std::convert::From 接口定义 “怎么根据另一种类型生成自己”
// - Into trait 就是把 From trait 倒过来而已; 使用 Into trait 通常要求指明要转换到的类型
//
//- TryFrom and TryInto trait 用于易出错的转换,也正因如此,其返回值是 Result
//
//- ToString trait 要把任何类型转换成 String,只需要实现 to_string 方法。
//然而不要直接这么做,应该实现fmt::Display trait,它会自动提供 ToString,并且还可以用来打印类型
//- 对应的有 FromStr, 只要对目标类型实现了 FromStr trait,就可以用 parse 把字符串转换成目标类型
//
use std::convert::From;
#[derive(Debug)]
struct Number {
value: i32,
}
impl From<i32> for Number {
fn from(item: i32) -> Self {
Number { value: item }
}
}
let num = Number::from(30);
println!("My number is {:?}", num);
let int = 5;
let num: Number = int.into();// num 类型必须指定
println!("My number is {:?}", num);
5.7. 所有权
5.7.1. 为什么需要所有权 RAII机制
所有权是对堆内存上的数据来说的, 所有权为每个数据规定了主人, 避免了数据竞争, 同时也能减少bug.
栈内存中变量的生命周期是短暂的, 随着方法调用的结束而清理, 堆内存的变量虽然可以长久存在, 但是非线程私有, 其内部的数据需要通过栈内存中的指针来使用
指针在堆上开辟内存 空 间,并拥有其所有权,通过存储于stack中的指针来管理堆内存 , 智能指针的 RAII 机制利用stack的特点,在元素被自动清空时自动调用析构函数,来释放智 能指针所管理的堆内存 空间
5.7.2. 基本原则
// 每种编程语言都有自己的一套内存管理的方法。
//有些需要显式的分配和回收内存(如C),
// 有些语言则依赖于垃圾回收器来回收不使用的内存(如Java)。
// 而Rust不属于以上任何一种,它有一套自己的内存管理规则,叫做Ownership。
//
// //
// 1. 在同一个 scope 内,"值"有且仅有一个 owner, 当owner超出作用域后,值会被销毁
// 例如 ,
let a = 11, let b = Person {};
func(a, b);
// 因为函数调用底层实际是 将 a, b 赋值给 函数栈中的临时变量, 造成 a, b 的所有权转移
// 对于 基本类型 a, 实现了 copy trait, 所有权转移的效果是 复制, a 仍然能继续使用
// 对于 符合类型b, 没有 copy trait, 所有权转移后, b 就失效了
//
// 2. 可以有多个不可变引用和唯一的可变引用 (类似读写锁)
// 在不可变借用期间,所有者不能修改资源,并且也不能再进行可变借用
// 在可变借用期间,所有者不能访问资源,并且也不能再出借所有权
//
//
// 3. references 的 lifecycle 不能超过"值"的 lifecycle
// reference 不能比 owner 活的时间还长 (比如通过 closure 捕获一个外部变量, 若不显式指定 move 语义, name 捕获的是 reference, 外部的 owner 可能已经被回收了, closure 内部的 reference 可能还在被使用, 这是错误的)
5.7.3. 字符串赋值的所有权
fn ownership() {
// 对于 basic type, 数据的互动都发生在栈上, 大小已经确定, 复制起来很快, 所以采用的是复制克隆
let x = 5;
let y = x; // 现在栈中将有两个值 5
println!("{}, {}", x, y);// 都有效
//产生一个 String 对象,值为 "hello"。长度可变, 需要在堆中存储
// s1 存储在栈, 结构中包含一个 ptr, 指向堆中的String 字符序列
let s1 = String::from("hello");
let s2 = s1;// 拷贝 s1 本身给 s2, 堆中的数据还是同一份
//
// 此时, s1已经失效了, 表现的像 s1 移动到 s2
//为什么rust规定此时 s1失效? 因为如果程序在这里结束, s1 和 s2 都被释放的话堆区中的 "hello" 被释放两次,会出错
// 为了确保安全,在给 s2 赋值时 s1 已经无效了
println!("s2 = {}", s2);
println!("s1 = {}", s1); // 错误
// 复制克隆堆中的对象
let s1 = String::from("hello");
let s2 = s1.clone();
// 此时, s1 s2 都有效
println!("s1 = {}, s2 = {}", s1, s2);
5.7.4. 函数参数的所有权
//
// 函数 参数的所有权机制
//
//如果将变量当作参数传入函数,那么它和移动的效果是一样的 (函数外部的变量失效)
let s = String::from("nihao");
let a = 11;
fn fn_basic_type(a: i32) {
println!("a = {}", a);
} // 函数结束, a基本类型, 资源无需释放
fn fn_str_type(s: String) {
println!("s = {}", s);
} // 函数结束, s 资源被释放
// s 被作为参数传递到函数内, 形参指向 String对象, 那么前面的 s 失效
//相当于数据被移动了
fn_str_type(s);
// 所以这里 s 无效了
println!(s);//error
// a 是基本类型, 实现了 copy trait, 传递时是 copy,
fn_basic_type(a);
// 所以, 此时 a 仍然有效
println!("a = {}", a);
5.7.5. 函数返回值所有权
//
// 函数返回值的所有权
//
//函数返回值的变量所有权将会被移动出函数并返回到调用函数的地方,
//而不会直接被无效释放。
fn return_str() -> String {
let s = String::from("hello");
return s;
}
fn give_and_return_str(s: String) -> String {
s
}
let s1 = return_str(); // 函数将内部返回值移动到 s1
let s2 = String::from("hello");
let s3 = give_and_return_str(s2); // s2 被移动失效
5.7.6. 复合类型中的所有权
// 所有权机制会带来复杂性
//
#[derive(Debug)]
struct Person {
name: String,
email: String,
}
let mut p = Person {
name: "xiaoyu".to_owned(),
email: "775000738@qq.com".to_owned(),
};
let _name = p.name;// property "name" was been removed out of p
println!("{:?}", p); // 编译出错 "value borrowed here after partial move" , 属性 name 为 string, 没有 copy trait, 被 move 掉后, 值就为 空了
p.name = "xy".to_owned(); // 重新赋值
println!("{:?}", p); // 这时不会报错了
// 模拟动画渲染示例
struct Buffer {
buf: String,
}
struct Render {
current: Buffer,
next: Buffer,
}
impl Render {
fn update_buffer(&mut self, buf: String) {
// 编译错误, next 没有实现 copy trait, 被 move 掉后, 就为 空了,
//一个可选方案是实现 copy trait, 但是这样就没法享受方便的 move 语义了
//
self.current = self.next;
self.next = Buffer {buf,};
// 解决:
//需要动用 std::mem::replace(&dest, src) 函数了, 这个函数把 src 的值 move 到 dest 中,然后把 dest 再返回出来
self.current = std::mem::replace(&mut self.next, Buffer {buf});
}
}
}
5.7.7. 多所有权
需要使用智能指针
fn multi_ownership() {
}
}
5.8. 生命周期参数
5.8.1. 什么是生命周期
let a = "hello";//let绑定了标识符 a和存 储字符串的那块内存,从而 a对那块内存拥有了所有权, a 也可称为一个绑定
let b = a; // a 的所有权被转给b (a 为 &str类型, 无法实现 copy trait); 其实也可以理解为对 a进行解绑,然后重新绑定给 b。
// 绑定具有时效性,也就是指它的生存周期
5.8.2. 为什么存在生命周期注释
因为存在生命周期检查, 生命周期注释是用来方便编译器进行生命周期检查的 , 并不能改变任何引用的生命周期长短
为什么要生命周期检查? 因为存在引用, 因为要保证引用的生命周期不能长于出借方的生命周期(防止垂悬引用), 有引用就会有生命周期检查
为什需要引用呢? 复合类型如果克隆的话, 会有性能问题, 这种情况, 只能传递引用了.
总结一下就是: 函数参数可 以按值传递, 也可以按 引 用传递。当参数按值 传递肘 , 会转移所有权或者执行复制( Copy)语义。当参数按引用传递 时, 所有权不会发生 变化 ,但是需要有生命周期参数 。当 符合生命周期参数省略规 则时, 编译器可 以通过自动准 断补齐函数参数的生命周期参数,否则,需要显式地为参数标明生命周期参数
/// 生命周期注释: 用来标注多个变量间生命周期的关系, 比如生命周期是否一样长
///
/// 目的: 避免垂悬引用
///
/// 生命周期注释并不改变任何引用的生命周期的长短
/// 单个的生命周期注解本身没有多少意义,因为生命周期注解告诉 Rust 多个引用的泛型生命周期参数如何相互联系的
///
/// 大部分情况, 生命周期都是可以自动推断的, 就像类型推断 , 没法推断时, 就需要手动标注生命周期注释了
//
// 语法:
// &’a i32
// &'a mut i32
///
///
fn life_cycle() {
// 看一个有问题的例子:
let a;
{
let x = 1;
a = &x; // 错误, `x` does not live long enough, 出了x 作用域, a 对 x 的借用就失效了
}
println!("{}", a);// 此时 a 变为垂悬引用
&i32 // 常规引用
&'a i32 // 含有生命周期注释的引用
&'a mut i32 // 可变型含有生命周期注释的引用
//
// 只有一个参数并且直接返回的例子
// 因为编译器可以自己推导出来,函数 foo() 的参数和返回值都是一个引用,他们的生命周期是一样的,所以,也就可以编译通过
fn foo (s: &mut String) -> &String {
s.push_str("coolshell");
s
}
let mut s = "hello, ".to_string();
println!("{}", foo(&mut s))
// 这个例子就不行了 , 编译器无法在编译期间知道会返回哪个变量, 也就无法自动推导出生命周期是否符合要求
//
// 这个错误例子只针对返回引用的情况
//
fn longer(s1: &str, s2: &str) -> &str {// error, 返回的引用 可能和参数定义的地方不在同一个作用域, 返回的引用孩砸使用的时候, 参数超出作用域而失效了
if s1.len() > s2.len() {s1}
else {s2}
}
// 正确的写法: 需要手动指定生命周期注释
//
fn longer<'a>(s1: &'a str, s2: &'a str) -> &'a str {//函数定义指定了签名中所有的引用必须有相同的生命周期 'a
// 加上周期注释就是告诉编译器: 函数返回的引用的生命周期 <= 每个传入参数的生命周期, 即返回值在使用过程中, 是安全的, 不会指向空
if s2.len() > s1.len() {
s2
} else {
s1
}
}
let r;
{
let s1 = "rust";
let s2 = "ecmascript";
r = longer(s1, s2);
}
println!("{} is longer", r); // 此时 s1, s2 都销毁了, 为什么 r 仍然有效呢? 因为 s1, s2 都是 &str 类型, 分配在 栈中, 在方法退出前, 都有效
//看 String 的例子:
let string1 = String::from("long string is long");
let result;
{
let string2 = String::from("xyz"); // 这里就有问题了, String 类型 字符序列分配在 heap, 超出 作用域自行销毁了
result = longer(string1.as_str(), string2.as_str());// error, borrowed value does not live long enough
// string2 生命周期比 result 短
}
println!("The longest string is {}", result);
//
//加不加 'a 都是错误, cannot return value referencing local variable `s`
// 因为函数结束, s 会离开作用域, 被清理
// 最好的解决方案是返回一个有所有权的数据类型而不是一个引用,这样函数调用者就需要负责清理这个值了。
//
fn as_str<'a>(s: &'a str) -> &'a str {
let s = String::from("hello");
s.as_str()
}
5.8.3. 函数中的生命周期参数
fn foo<’a>(s: &’a str, t: &’a str) -> &’a str
// 输出(借用方)的生命周期长度必须 短于/等于 输入(出借方)的生命周期长度
// -》返回的引用必须和输入参数有点关系才行
5.8.4. 结构体中生命周期 省略的规则
// 生命周期省略
//
// 省略遵循的规则:
// - 只有一个生命周期参数, 可以省略, 如 fn bar<'a>(x: &'a i32) -> &'a 32 等价 fn bar(x: &i32) -> &i32
// - 每个引用参数都有属于自己的周期参数, 如 fn foo<'a, 'b>(x: &'a i32, y: &'b i32), fn bar<'a>(x: &'a i32)
// - 对于 struct 的方法, 第一个参数都是 &self, 那么 self 的周期被赋予所有输出生命周期参数 , 所以 返回参数可以省略周期参数
//
//
//
// 加上周期注释, 告诉编译器, 结构体的生命周期 <= 成员引用的生命周期, 即成员的周期要保证结构体周期的安全, 成员的周期必须要更大
struct Str<'a> {
content: &'a str // 使用字符串切片引用, 之前都是使用的 String
}
impl<'a> Str<'a> {
//
//这里返回值并没有生命周期注释,但是加上也无妨。这是一个历史问题,早
//期 Rust 不支持生命周期自动判断,所有的生命周期必须严格声明,但主流
//稳定版本的 Rust 已经支持了这个功能
fn get_content(&self) -> &str {
self.content
}
//指定: 结构体方法的“引用参数”的生命周期 >= 结构体的生命周期, 保证结构体周期的安全
// 若没有 ‘a, 会报错
fn replate(&mut self, new: &'a str) {...}
}
let s = Str {
content: "string_slice" // 方便多了
};
println!("s.content = {}", s.get_content());
}
5.8.5. 静态生命周期注释
//静态生命周期
//
//'static 所表示的生命周期从程序运行开始到程序运行结束。(若一个类型被限制为 'static ,则表示该类型不能是任何借用的数据, 必须是 own 的数据, 必须拥有ownership; 因为 'static 说明他的 lifecycle 最长, 若该类型接收的是借用的数据, 那么无法保证 lifecycle 最长)
//
//所有字符串字面量都是 &'static str ,
let s: &'static str = "hello";
// 等价
let s = "hello";
//一个综合例子🌰
use std::fmt::Display;
fn longest_with_an_announcement<'a, T>(x: &'a str, y: &'a str, ann: T) -> &'a str
where T: Display
{
println!("Announcement! {}", ann);
if x.len() > y.len() {
x
} else {
y
}
}
5.8.6. 生命周期约束
// T:’a, 表示T类型中的任何引用都要“活得” 和 ’a 一样长。
// T: Trait + ‘a,表示 T类型必须实现 Trait这个 trait,并且 T类型中任何引用都要“活得”和 ’a 一样长。
5.9. 引用
5.9.1. 引用基本介绍
/// 借用(引用)
/// "&"符号用于从变量借用所有权, 生成一个变量的引用
/// ref 声明某个变量为引用类型, 用来更改赋值行为, 使得普通的变量赋值行为变为给引用赋值 ; 可用于先声明某个引用类型, 后赋值
///
///
///
/// 引用本身也是一个类型并具有一个值,这个值记录的是别的值所在的位置
///
/// 引用不会获得值的所有权, 引用只能租借(Borrow)值的所有权, 所以 变量 a 的值被借用为 b 时,a 本身仍然有效。
///
/// 解引用 使用 * ---- 在等号右边 (会获得原始值的所有权)
/// 取地址 使用 & ---- 在等右边
/// 解构 使用 & --- 在等号左边
///
/// match的模式匹配的匹配项上只能使用 ref,
/// 在函数声明上只能使用&来表示引用类型
///
/// 一个引用的作用域从声明的地方开始一直持续到最后一次使用为止
///
/// 在任意给定时间,要么 只能有一个可变引用,要么 只能有多个不可变引用
//
/// 分为可变, 不可变引用
//
// 一个原始值, 存在可变借用, 就无法存在其他借用了, 无论是可变借用还是不可变借用 (可变借用具有独占性)
// 存在不可变借用, 还能存在其他不可变借用 (相当于内存的读写锁 ,同一时刻,只能 拥有一个写锁,或者多个读锁,不能同时拥有)
///
let a = 20;
let b = &a; // 取地址
if a==*b // true , *号为解引用符号
{
println!("a and *b are equal"); // 将打印这句
}
else
{
println!("they are not equal");
}
//
//
// ref 关键字
//
let ref a=2;
let a = &2; // 等效, 两个值都是&i32类型
let ref b: i32; // 先声明一个引用类型
//b = 1;// 错误, 类型不匹配, expected `&i32`, found integer. expected &i32,consider borrowing here: `&1`
b = &1;// 再赋值
//
// 为参数声明类型的时候, 只能用 &, 不能用 ref, ref 只用于变量类型声明
//
struct B<'l> {
pub a: &'l u32,
pub b: ref u32, //错误, expected type, found keyword `ref`
}
let ref a = &1;
let b = B{ a: a };
fn test(a: ref i32) { } // 错误
let v = 2;
let mut v_mut = 2;
match v {
// ref 会声明 val 是 &i32 类型, 通过 val 接收 v
ref val => println!("val 是引用, val = {}", val),// 打印, *val 也可, 打印时可以省略 *
}
match v_mut {
ref mut val => {
// 需要 val 声明为 mut
*val = 3;
println!("val 是可变引用, val = {}", val);
},
}
// 解引用
let r=&1;// r 是引用类型 &i32
let &a=r;// a 是普通类型, i32
let c=*r; // c 同 a, 是 i32 (解引用)
//
// match 中使用解引用
let r = &1;
match r {
&val => println!("通过解引用获取值: {}", val),
}
match r {
*val => println!("使用 * 解引用: {}", val),// 错误, * 不能用来做声明
}
// 需要先解引用, 再内部使用
match *r {
val => println!("匹配前先解引用: {}", val),
}
std::mem:size_of<&[u32; 5]>() //函数可以返回类型的字节数
// &[u32;5]类型为普通指针 (因为数组的元素类型, 元素个数确定了, 无需额外的容量来存储数据的长度),占8个字节:
// &mut[u32]类型为胖指针 (宽度是双宽度的, 数组的元素个数不确定, 除了要保存指向起始位置的地址外, 还要保存数据的长度 ),占16 个字节。 可见, 整整多出了一倍的占用空间,这也是称其为胖指针的原因
}
5.9.2. 不可变引用
println!("------------------引用/借用---------------------------");
let s1 = String::from("hello");
let s2 = &s1; // 获取引用
println!("s1 is {}, s2 is {}", s1, s2);
// 函数调用
fn calculate_length(s: &String) -> usize {
s.len()
}
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{}' is {}.", s1, len);// s1 还有效
let s1 = String::from("hello");
let s2 = &s1;
// 错误, 执行这句, s1 会移动而失效
// 造成 s2 对 s1 的租借也失效
let s3 = s1;
println!("{}", s2);//error
let s1 = String::from("hello");
let mut s2 = &s1;
let s3 = s1;
s2 = &s3; // // 重新从 s3 租借所有权, 要求 s2 是 mut 的
println!("s2 = {}", s2);
//
// 引用的所有权是租借的, 不允许修改值
//
let s1 = String::from("run");
let s2 = &s1;
println!("{}", s2);
s2.push_str("oob"); // 错误,禁止修改租借的值
5.9.3. 可变引用
fn borrow() {
//
//可变引用
//
// 可修改值的租借
let mut s1 = String::from("run");
// s1 是可变的
let s2 = &mut s1;
// s2 是可变的引用
s2.push_str("oob");
println!("可变引用, s2 = {}", s2);//runoob
println!("s1 = {}", s1);//runoob
//
//可变引用不允许多重引用
//
//一个值被可变引用时不允许再次被任何引用。
// 主要出于对并发状态下发生数据访问碰撞的考虑,在编译阶段就避免了这种事情的发生
let mut s = String::from("hello");
let r1 = &mut s;
// 错误, 因为 两个可变引用指向了 s;
let r2 = &mut s;
// 类似的多重引用问题
//
let mut s = String::from("hello");
let r1 = &s; // 没问题
let r3 = &mut s; // 大问题
println!("{}", r1);
5.9.4. 垂悬引用问题(Dangling References)
//
//垂悬引用(Dangling References)---- 如何解决 -> 生命周期注释
//
//
// 垂悬引用(Dangling References): 没有实际指向一个真正能访问的数据的指针
//
//在 Rust 语言里不允许出现
fn dangle() -> &String {
let s = String::from("hello");
//函数的结束,其局部变量的值本身没有被当作返回值,被释放了。但它的引用却被返回
&s
}
// 再比如:
//
let r;
{
let x = 3;
r = &x; //`x` does not live long enough, r 所引用的值已经在使用之前被释放
}
println!("r = {}", r);
//
// 再比如:
fn longer(s1: &str, s2: &str) -> &str {
if s2.len() > s1.len() {
s2
} else {
s1
}
}
// //上个函数错误, 无法编译, 原因是返回值引用可能会返回过期的引用, 例如这样使用:
let r;
{
let s1 = "rust";
let s2 = "ecmascript";
r = longer(s1, s2);
}
println!("{} is longer", r); // r 被使用的时候源值 s1 和 s2 都已经失效了, 需要使用生命周期注释, 为返回值声明一个注释, 贴到 参数上
5.10. 裸指针
// 原生 指针是指形如* const T 和*mut T 这样的类型 。
// 可以通过 as操作符随意转换为原生指针,例如 &T as *constT 和 &mut T as *mutT。
// 场景:
// - 在需要的时候跳过 Rust 安全检查
// - 与 C 语言“打交道"
// 内置函数
// • std::ptr::null 函数和 is_null 方法
// • offset方法
// • read/write方法
// • replace/swap 方法
// 解引用
//
fn main() {
let mut s = "hello".to_string();
// 转换
let r1 = &s as *const String;
let r2 = &mut s as *mut String;
assert_eq!(r1, r2);
let address = 0x7fff1d72307d;// 随便指定的地址
let r3 = address as *const String;
unsafe {
println!("r1 is: {}", *r1);
println!("r2 is: {}", *r2);
// error
// Segmentation fault
assert_eq!(*r1, *r3)
}
}
// 创建
fn main() {
// 创建空指针
let p: *const u8 = std::ptr::null();
// 判断是否为空指针
assert!(p.is_null());
let s: &str = "hello";
// 获得不可变原生指针 (指向具体数据/数据内部的元素)
// 指针 ptr 的类型为*const u8, 这 是因为字符串是以字节为单位存储的
let ptr: *const u8 = s.as_ptr();
assert!(!ptr.is_null());
//对比 通过 as_ptr()获取指针:
// - 通过 as_ptr 得到的指针是指向存放数据堆/栈 内存的指针,而引用则是对字符串或数组本身的引用(比前者单纯的指针包含更多数据)。
let mut x = "";
let y = &mut x as *mut &str;
unsafe {
assert_eq!(y.read(), "hello");
}
let mut s = [1, 2, 3];
// 获得可变原生指针
let ptr: *mut u32 = s.as_mut_ptr();
assert!(!ptr.is_null());
}
// offset() 可以指定相对于指针地址的偏移字节数,
//
//
fn main() {
let s: &str = "Rust";
let ptr: *const u8 = s.as_ptr();
// offset方法不能保证传入的偏移量合法,故为unsafe
unsafe {
println!("{:?}", *ptr.offset(1) as char); // u
println!("{:?}", *ptr.offset(3) as char); // t
println!("{:?}", *ptr.offset(255) as char); // ÿ 有UB风险
}
}
// read/write 可以读取或写入指针相应 内存中的 内容
//
fn main() {
let x = "hello".to_string();
let y: *const u8 = x.as_ptr();
unsafe {
assert_eq!(y.read() as char, 'h');
}
let x = [0, 1, 2, 3];
// 这里的原生指针类 型是带长度的,
// 如果将类型改为* const [u32;3] ,则通过 read 方法只能读取到前三个元素
let y = x[0..].as_ptr() as *const [u32; 4];
unsafe {
assert_eq!(y.read(), [0,1,2,3]);
}
let x = vec![0, 1, 2, 3];
let y = &x as *const Vec<i32>;
unsafe {
assert_eq!(y.read(), [0,1,2,3]);
}
let mut x = "";
let y = &mut x as *mut &str;
let z = "hello";
unsafe {
y.write(z);
assert_eq!(y.read(), "hello");
}
}
// replace/swap 替换指定位置 的内存 数据
//
fn main() {
let mut v: Vec<i32> = vec![1, 2];
let v_ptr : *mut i32 = v.as_mut_ptr();
unsafe{
let old_v = v_ptr.replace(5);
assert_eq!(1, old_v);
assert_eq!([5, 2], &v[..]);
}
let mut v: Vec<i32> = vec![1, 2];
let v_ptr = &mut v as *mut Vec<i32>;
unsafe{
let old_v = v_ptr.replace(vec![3,4,5]);
assert_eq!([1, 2], &old_v[..]);
assert_eq!([3, 4, 5], &v[..]);
}
let mut array = [0, 1, 2, 3];
let x = array[0..].as_mut_ptr() as *mut [u32; 2];
let y = array[1..].as_mut_ptr() as *mut [u32; 2];
unsafe {
assert_eq!([0, 1], x.read());
assert_eq!([1, 2], y.read());
x.swap(y);
assert_eq!([1, 0, 1, 3], array);
}
}
5.11. 智能指针
5.11.1. 智能指针介绍 工作机制
智能指针就是一个结构体,其行为类似于引用, 指向一块内存的地址, 此外还有存储的有附带的元数据
智能指针区别于常规结构体的特性在于,它实现了 Deref (所以有了指针语义, 而且使用时, 可以自动解引用) 和 Drop (所以能够自动管理内存释放) ; 比如: String 和 Vec 类型 也是一种智能指针, 它们也都实现了 Deref和Drop (这就是智能指针智能的所在)
智能指针拥有资源的所有权,而普通引用 只 是对所有权 的借用 。
- 线程安全的: Arc, RwLock, Mutex
- 线程不安全的: Box , Cell, RefCell, Rc
let x =Box::new(”hello”);
let y = x;
// error, 因为智能指针拥有原始值的所有权, x已经被转移了
// 对于box<T>, 若包含的 T是移动语义, 则box 也是, 若T是复制语义, 则box 也是复制语义
println1(”(:?}”, x);
5.11.2. RAII机制 实现内存回收
RAII: 智能指针在堆内存上开辟空间存储数据, 自身存储在栈上, 在函数调用结束时, 指针变量被清理, 指针执行自身的drop方法, 来释放智 能指针所管理的堆内存 空间
RAII , 智能指针, 均起源于现代 C++
5.11.3. 自定义智能指针 自动解引用 Deref 和 Drop
手动显式解引用: *x <=> *(x.deref()), deref() 是编译器帮忙加的 (deref() 返回内部数据的引用)
"."调用 or 在函数参数位置上, 会对x 自动解引用, 等价于 x.deref()
// 自定义智能指针
//
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
//实现 Deref trait 允许我们重载 解引用运算符
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
let x = 5;
let y = MyBox::new(x);
println!("y = {}", *y);
// 隐式解引用 (解引用多态)
fn hello(name: &str) {
println!("Hello, {}!", name);
}
let m = MyBox::new(String::from("Rust"));
hello(&m);
//在 MyBox<T> 上实现了 Deref trait,Rust 可以通过 deref 调用将 &MyBox<String> 变为 &String。
//标准库中提供了 String 上的 Deref 实现,其会返回字符串 slice,这可以在 Deref 的 API 文档中看到。
//Rust 再次调用 deref 将 &String 变为 &str,这就符合 hello 函数的定义了。
5.11.4. Box 无痛使用堆内存
5.11.4.1. Box基本使用
类似 cpp 的 unique_ptr;
通过 Box,用于在堆上分配值
//
// 为什么使用
// Rust 中的值默认被分配到stack内存, stack 内存需要知道值的具体大小, 对于 递归类型 和 trait object, 编译时并不知道大小, 而 Box<T> 的大小是已知的。 可以通过 Box <T>将值装箱, 在堆内存中分配
//
///核心作用就是可以定义动态大小的类型, 实际大小要到运行期才能确定, 如 用在 递归中 and 用在包装 trait 中
//
/// 当箱子实例离开作用域时,它的析构函数会被调用,内部的对象会被 销毁,堆上分配的内存也会被释放
//
// Box<T>指针对所管理的堆内存有唯一拥有权, 所以并不共享
///
/// 使用 * 运算符进行解引用;这会移除掉一层装箱
///
fn box_demo() {
println!("-------------box_demo--------------");
let b = Box::new(5);//使用 box 在堆上储存一个 i32 值
println!("b = {}", b);//5
println!("*b = {}", *b);//5
// 尝试构造链表
enum List {
Cons(i32, List),// error, 无限递归, 编译器检测出了无限大小
Nil,
}
// 正确: (这种方法存在限制, 构造出的 链表无法存在多个引用, 使用一次就失效了, 没法给第二个使用者使用了, 解决: Rc)
#[derive(Debug)]
enum List {
Cons(i32, Box<List>),
Nil,
}
use List::Cons;
use List::Nil;
let l = Cons(
1,
Box::new(Cons(
2,
Box::new(Cons(
3,
Box::new(Nil),
))
))
);
println!("{:?}", l);//Cons(1, Cons(2, Cons(3, Nil)))
5.11.4.2. 包装动态大小类型 DST
// 动态大小类型
// 编译期间无法知道大小, 只有到运行时才知道
//
// 动态大小类型的值必须通过指针访问 , 如 Box<str>, Rc<str>
//
//
// 如:
// - str 在编译期无法知道大小, &str 的大小可以在编译期知道 (&str 存储了 str 的地址 和长度)
// - trait , 任何 trait 都是动态大小类型, 应该这么使用: Box<XXXTrait>
//
// Sized trait
// 实现了这个 trait 的类型, 在编译期即可确定大小
fn xxx_fn<T>(t: T) {} // T 为编译期知道大小的类型
// 等价:
fn xxx_fn<T: Sized>(t: T) {}
// 放宽限制
fn xxx_fn<T: ?Sized>(t:T) {}// T 可能是 sized 的, 也可能不是 sized 的
}
5.11.5. Rc 和 Weak 共享堆内存
5.11.5.1. Rc 强引用
类似 cpp 的 shared_ptr
引用计数指针, 其数据可以有多个所有者, 内部包含的数据是不可变的,
只能用于单线程中, 因为内部操作不是原子性的, rust 也为 其实现了 !send trait , 表示无法在线程间移动; 可以使用多线程版本: Arc
/// Rc<T> 的类型。其名称为 引用计数(reference counting)
//
// Rc<T> 主要用于同一堆上所分配的数据区域需要有多个只读访问的情况, 比起使用 Box<T> 然后创建多个不可变引用的方法更优雅也更直观一些
//
/// 允许 "不可变数据" 有多个所有者, 数据本身无法修改 (将多个所有权共享给多个变量)
//
// 内部维护着一个引用计数器,每clone一次(共享一次), 计数器加1, 返回不可变引用, 当它们都离开作用域肘, 计 数器会被清零,对应的堆内存也会被自动释放。
//
// 常用方法:
//
//
//
//
//
///
let x =Rc::new(45)
let yl = x .clone() ; //增加强引用计数, 并非 克隆, 只是增加计数, 然后返回一个引用 (即共享所有权)
let y2 = x.clone(); //增加强引用计数
priηtln!(”{:?}”, Rc::strong_count(&x));//3
letw= Rc::downgrade(&x); //增加弱引用计数
println!(” {:?) ”, Rc : :weak_count(&x));
let y3 = &*x; //不增加计数
5.11.5.2. 构造链表
//
// 通过 box 构造链表存在问题: 链表只能被使用一次, 演示:
enum List {
Cons(i32, Box<List>),
Nil,
}
use List::{Cons, Nil};
let a = Cons(5,
Box::new(Cons(10,
Box::new(Nil))));
let b = Cons(3, Box::new(a)); //a 被移动到了 b 内部
let c = Cons(4, Box::new(a));// error 错误, value used here after move
// 使用 Rc 解决
enum List {
Cons(i32, Rc<List>),
Nil,
}
use List::{Cons, Nil};
use std::rc::Rc;
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
//每次调用 Rc::clone,Rc<List> 中数据的引用计数都会增加,Rc::strong_count(&a) 获取 a 的被引用个数
// 直到有零个引用之前其数据都不会被清理
//
//也可以调用 a.clone() 而不是 Rc::clone(&a), 两者意思是一样的, 只会增加引用计数,不会作深度复制
//
// 这里, b, c 共享 a 的所有权, a 中的数据不可修改
let b = Cons(3, Rc::clone(&a));
let c = Cons(4, Rc::clone(&a));
// #### 对内部值进行修改
///
///如果你要修改 Rc 里的值,Rust 会给你两个方法,一个是 get_mut(),一个是 make_mut() ,这两个方法都有副作用或是限制
/// - get_mut() 需要做一个“唯一引用”的检查,也就是没有任何的共享才能修改
///- make_mut() 则是会把当前的引用给clone出来,再也不共享了, 是一份全新的
// 更好的修改方法:
/// RefCell<T> 能够在对象被认为是不可变的情况下修改内部字段; (并非编译器检查, 二是运行期进行检查, 不是很好)
/// Cell<T>,它类似 RefCell<T> 但有一点除外:它并非提供内部值的引用,而是把值拷贝进和拷贝出 Cell<T>。
///
///
//
//修改引用的变量 - get_mut 会返回一个Option对象
//但是需要注意,仅当(只有一个强引用 && 没有弱引用)为真才能修改
if let Some(val) = Rc::get_mut(&mut strong) {
*val = 555;
}
// 或者:
//此处可以修改,但是是以 clone 的方式,也就是让strong这个指针独立出来了。
*Rc::make_mut(&mut strong) = 555;
5.11.5.3. Weak 弱引用
类似 cpp 的 weak_ptr
// 弱引用
/// 弱引用: Weak<T>
// Weak 共享的指针没有所有权, 称为弱引用
/// - 通过 Rc::downgrade 传递 Rc 实例的 reference, 得到 Weak 类型的指针, 同时将 weak_count +1, 不是 strong_count +1
/// - 即使 weak_count 不为零, 也可能使得 Rc 实例被清理, 只要 strong_count == 0 就行了 (解决循环链表造成的内存泄漏)
/// - 可以通过 Rc::upgrade 返回 Option<Rc<T>> 升级成强引用
///
/// 这么麻烦,我们为什么还要 Weak ? 这是因为强引用的 Rc 会有循环引用的问题……
// 基本使用
use std::rc::Rc;
use std::rc::Weak;
let weak: Weak<i32>;
let strong: Rc<i32>;
{
let five = Rc::new(5); //局部变量
strong = five.clone(); //进行强引用
weak = Rc::downgrade(&five); //对局部变量进行弱引用
}
//此时,five已析构,所以 Rc::strong_count(&strong)=1, Rc::weak_count(&strong)=1
//如果调用 drop(strong),那个整个内存就释放了
//drop(strong);
//如果要访问弱引用的值,需要把弱引用 upgrade 成强引用,才能安全的使用
//这个升级可能会不成功,因为内存可能已经被别人清空了
match weak_five.upgrade() {
Some(r) => println!("{}", r),
None => println!("None"),
}
// 解决循环引用的内存泄漏问题
use std::{
cell::RefCell,
rc::{Rc, Weak},
};
fn main() {
struct Node {
head: Option<Weak<RefCell<Node>>>,
next: Option<Rc<RefCell<Node>>>,
}
impl Drop for Node {
fn drop(&mut self) {
println!("dropping")
}
}
let one = Rc::new(RefCell::new(Node {
head: None,
next: None,
}));
let two = Rc::new(RefCell::new(Node {
head: None,
next: None,
}));
let three = Rc::new(RefCell::new(Node {
head: None,
next: None,
}));
one.borrow_mut().next = Some(two.clone());
two.borrow_mut().next = Some(three.clone());
three.borrow_mut().head = Some(Rc::downgrade(&one));// 弱引用, 即使计数没有归零, 仍然可回收内存
}
5.11.6. RefCell 和 Cell 提供内部可变性
内部可变性: 将可变的数据包装在不可变的结构中, 而无需显式声明 mut
需要注意的是 Cell 和 RefCell 不是线程安全的。在多线程下,需要使用Mutex进行互斥。
5.11.6.1. Cell
// Cell<T>
//
// 规避 borrow check: Cell<T> 其实和 Box<T> 很像,但后者同时不允许存在多个对其的可变引用,如果我们真的很想做这样的操作,在需要的时候随时改变其内部的数据,而不去考虑 Rust 中的不可变引用约束,就可以使用 Cell<T>。Cell<T> 允许多个共享引用对其内部值进行更改,实现了「内部可变性」
//
// 提供了一种内部可变性, 如, 某个 struct 是不可变的, 但是 内部某个字段需要可变
#[derive(Debug)]
struct P {
x: i32,
y: Cell<i32>,// 这里定义的是 Cell的不可变类型, 但是 内部的数确实可以修改的, 合法的避开的借用检查
}
let p = P { x: 0, y: Cell::new(11)};
println!("{:?}", p);
p.y.set(1); // set() 对内部数据的类型没有要求
println!("{}", p.y.get());// 内部的数据必须是 copy trait 才能使用 get(), 这里实际是获取拷贝,
// 若是非 copy类型, 提供 get_mut() 获取内部数据的可变引用
println!("{:?}", p);
5.11.6.2. RefCell
/// RefCell<T>
/// 它类似 Cell<T>, 但有一点除外:提供内部值的引用, 而不是拷贝了, 因此对于内部数据的类型没有 copy trait 要求 (Cell 的内部数据有 copy trait 要求)
//
// 既然不能在读写数据时简单的 Copy 出来进去了,该咋保证内存安全呢?
//
// borrow chec 放到了运行时
// 虽然没有分配空间, 但它是有运行时开销的,因为它自己维护着一个运行时借用检查器, 比如获取多个可变引用, 会Panic
//
// 主要两个方法:
// borrow_mut() 获取可变引用 (RefMut<T>)
// borrow(), 获取不可变引用 (Mut<T>)
//
// refcell 更常用, 省内存, cell 的 get() 是获取拷贝, 浪费内存
//
let v = RefCell::new(vec![1]);
println!("{:?}", v.borrow());//1
v.borrow_mut().push(1);
println!("{:?}", v.borrow());//1, 1
let x = RefCell::new(vec![1, 2, 3, 4]);
println!("{:?}", *x.borrow()); //[1, 2, 3, 4]
{
let mut my_ref = x.borrow_mut();
my_ref.push(1);
}
// 若上面的可变借用不另开一个 作用域, 这里报错: 可变借用后, 不允许再次不可变借用了
// 另开一个作用域的效果: my_ref 这个可变借用到这里的时候已经被释放了
println!("{:?}", *x.borrow()); //[1, 2, 3, 4, 1]
// RefCell<T> 的一个常见用法是与 Rc<T> 结合构造链表, rc 允许多重引用, 抱在外层, refcel 获取可变引用
//
//他们提供了 set()/get() 以及 borrow()/borrow_mut() 的方法
//
#[derive(Debug)]
enum List1 {
Cons(Rc<RefCell<i32>>, Rc<List1>),
Nil,
}
use List1::{Cons, Nil};
let value = Rc::new(RefCell::new(5));
let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil)));
let b = Cons(Rc::new(RefCell::new(6)), Rc::clone(&a));
let c = Cons(Rc::new(RefCell::new(10)), Rc::clone(&a));
*value.borrow_mut() += 10;
println!("a after = {:?}", a);
println!("b after = {:?}", b);
println!("c after = {:?}", c);
// 实例:
// 定义一个 trait, 定义发送方法 send, 这里 self 是不可变的
// 后续会通过 这个不可变 self 得到可变的成员变量
trait MsgSender {
fn send(&self, msg: &str); // 这个 trait 已经固定, &self 不允许改成 &mut self
}
// 监控器
struct LimitTracker<'a, S: MsgSender> {
sender: &'a S,
max: usize, // 最大限量阈值
value: usize, // 已经使用了多少
}
impl<'a, T> LimitTracker<'a, T>
where
T: MsgSender,
{
fn new(sender: &'a T, max: usize) -> Self {
LimitTracker {
sender,
max,
value: 0,
}
}
fn set_value(&mut self, value: usize) {
self.value = value;
let percent = self.value as f64 / self.max as f64;
if percent >= 1.0 {
self.sender.send(">= 1.0");
} else if percent >= 0.8 {
self.sender.send(">= 0.8");
}
}
}
use std::cell::RefCell;
//消息发送模拟器
struct MsgSenderMock {
// 为什么要包装?
//后面需要通过 不可变的 &self 拿到可变的 msg_send (不可变 &self 是在 trait 中定义的, send方法获取的是 self不可变引用)
//如果不包装一下, 则这里无法修改 msg_send 来记录发送的消息
msg_send: RefCell<Vec<String>>,// 记录发送的信息, 发送的消息会存储到这里
}
impl MsgSenderMock {
fn new() -> Self {
MsgSenderMock {
msg_send: RefCell::new(vec![]),
}
}
}
impl MsgSender for MsgSenderMock {
fn send(&self, msg: &str) {
// 改为 refcell后, 通过 borrow_mut 得到可变引用, 类型 Ref, 类似普通引用
self.msg_send.borrow_mut().push(msg.to_string());
}
}
// 测试
let mock_sender = MsgSenderMock::new();
let mut tracker = LimitTracker::new(&mock_sender, 10);
tracker.set_value(8);
println!("{}", mock_sender.msg_send.borrow()[0]); // 获取不可变引用
5.11.7. Rc Box RefCell Cell 几种指针的区别对比 组合使用
/// 区别:
/// - owner 个数: Rc<T> 允许数据有多个所有者;Box<T> 和 RefCell<T> 只能允许有单一所有者。
//
/// - borrow checker 时期: Box<T> 在编译时执行借用检查;Rc<T>也在编译时执行借用检查;RefCell<T> 允许在运行时执行借用检查
//
// - 运行时开销: Cell<T>无运行 时开销,并且永远不会在运行 时引发 panic 错误。 refcell 要在运行时执行借用检查,所以有运行时开销
//
// - 提供内部可变性
// - Cell<T>使用 set/get 方法直接操作包裹的值 (底层是将内部值拷贝出, 修改后在拷贝进去, 适合于实现Copy的类型即复制语义类型)
// - RefCell<T>通过 borrow/borrow_mut 返回 包装过的引用 Ref<T>和 RefMut<T>来操作包裹的值 (适合没有实现Copy的类型, 即移动语义类型。)
//
//
//
// 如果遇到要实现一个同时存在多个不同所有者,但每个所有者又可以随时修改其内容,且这个内容类型 T 没有实现 Copy 的情况该怎么办
let shared_vec: Rc<RefCell<_>> = Rc::new(RefCell::new(Vec::new()));
// Output: []
println!("{:?}", shared_vec.borrow());
{
let b = Rc::clone(&shared_vec);
b.borrow_mut().push(1);
b.borrow_mut().push(2);
}
shared_vec.borrow_mut().push(3);
// Output: [1, 2, 3]
println!("{:?}", shared_vec.borrow());
5.11.8. Pin 和 Unpin
/// 使用 Pin<P> 则代表将数据的内存位置牢牢地“钉”在原地,不让它移动 。(作用的类型是指针)
// 是为了解决自我引用的数据结构( 典型如: 内部包含指针 p 和数据 data, p 指向 data)在内存中做地址移动后, p 的值还是原来的值, 但是 data 有了新的地址, 因此整个数据结构就不能使用了, 如在做 swap 操作时容易出现循环引用 (类比 "刻舟求剑"的故事)
// (
// 自引用结构有啥用处啊?
// 主要是为了支持Rust的异步编程
// )
// Unpin 则正好和 Pin 的解药, 代表被“钉”住的数据,可以安全地移动。大多数类型都自动实现了 Unpin。
// 若 P 是 !Unpin 类型, Pin<P> 无法 deref_mut, 也就是无法拿到 P 的可变引用
// Unpin 是 auto trait, 会自动实现
// impl Future 是 !Unpin 类型, 因为 Future 是典型的 自引用结构
// tokio 下的 AsyncRead AsyncWrite
// futures 下的 Stream 和 Sink
5.11.9. Cow 写时复制
写时复制( Copy on Write)技术是一种程序中的优化策略, 翻译成人话就是 拖延到需要对数据进行写操作时才复制一份拷贝, 比如 Linux 中父进程创建于进程时 , 并不是立刻让子进程复制一份进程空间,而是先让子进程共享父进 程的进程空间 , 只有等到子进程真正需要写入的时候才复制进程空间。
// 是一个枚举体的智能指针
// Borrowed, 用于包裹引用。表示是对数据的借用
// Owned, 用于包裹所有者。表示是对数据的拥有
//
// 以不可变的方式访问借用内容,以及在需要可变借用或所有权 的时候再克隆一份数据
//旨在减少复制操作,提高性能, 一般用于读多写少的场景
//
// - Cow<T>实现了 Deref, 这意味着可以直接调用其包含数据的不可变 方法。
// - to_mut 方法来获取可变借用.
// 若 T 是 借用, 该方法会产生克隆,但仅克隆一次 , 如果多次调用,则只会使用第一次的克隆对象
// 如果 T 本身拥有所有权,则此时调用 to_mut不会发生克隆. 所有权转移
// into_owned方法来获取一个拥有所有权的对象
// 若 T 是借用, 发生克隆,井创建新的所有权对 象
// 如果 T 是所有权对象, 则会将所有权转移到新的克隆对象。
use std::borrow::Cow;
// 求元素绝对值
fn abs_all(input: &mut Cow<[i32]>) {
for i in 0..input.len() {
let v = input[i];
if v < 0 {
// 获取可变引用
//to_mut 方法会在第一次调用时克隆一个新的对象,在后续的 for 循环中 继续用新的克隆对象
input.to_mut()[i] = -v;
}
}
}
// 求和
fn abs_sum(ns: &[i32]) -> i32 {
let mut lst = Cow::from(ns);
abs_all(&mut lst);
lst.iter().fold(0, |acc, &n| acc + n)
}
fn main() {
let s1 = [1,2,3];
let mut i1 = Cow::from(&s1[..]);
// i1 中的元素都为正, 不会进入if逻辑, 不涉及到可变需求,所以不会克隆
abs_all(&mut i1);
println!("IN: {:?}", s1);//1,2,3
println!("OUT: {:?}", i1);//1,2,3
let s2 = [1,2,3, -45, 5];
let mut i2 = Cow::from(&s2[..]);
// 这里有可变需求,且穿进cow 的数据是个引用, 没有所有权, 所以会克隆, i2 实际是克隆出的新对象
abs_all(&mut i2);
println!("IN: {:?}", s2);//[1, 2, 3, -45, 5]
println!("OUT: {:?}", i2);//[1, 2, 3, 45, 5]
// 这里不会克隆,因为数据本身拥有所有权
let mut v1 = Cow::from(vec![1,2,-3,4]);//v1是本身就是可变的
abs_all(&mut v1);
println!("IN/OUT: {:?}", v1);//[1, 2, 3, 4]
}
// 另一个用处是统一实现规范
use std::borrow::Cow;
use std::thread;
#[derive(Debug)]
struct Token<'a> {
raw: Cow<'a, str>,//该用&str类型还是 String类型呢?为了寻求统一,这里使用了 Cow<T>
}
impl<'a> Token<'a> {
pub fn new<S>(raw: S) -> Token<'a>
where
S: Into<Cow<'a, str>>,
{
Token { raw: raw.into() }
}
}
fn main() {
let token = Token::new("abc123");
let token = Token::new("api.example.io".to_string());
// 还可以跨线程安全传递
thread::spawn(move || {
println!("token: {:?}", token);
}).join().unwrap();
// 使用动态字符串切片,则会因为生命周期的问题而无法跨线程安全传递
//error
let raw = String::from("abc");
let s = &raw[..];
let token = Token::new(s);
thread::spawn(move || {
println!("token: {:?}", token);
}).join().unwrap();
}
5.12. 函数
5.12.1. 函数基本语法
/// 如果不指定返回值类型, 默认 返回类型为 () 空元组
// 同名函数在存在于多个作用域(比如 main 外, main 内, main 内的新作用域 分别有三个同名函数), 会发生屏蔽
fn sum(aa: i8, bb: i8) -> i8 {
// 返回值明确指定类型
// 若带 return, 就是语句, 需要分号
// return aa +bb;
// 不带 return, 就是表达式, 没有分号
aa + bb
}
let sum = sum(3, 9);
println!("sum = {}", sum);
// 函数参数支持模式匹配
fn a(mut b: [i32; 2]) { // 参数为数组可变类型, 不是引用类型 (mut 无法放在冒号后面)
}
5.12.2. 函数体表达式
let x = 1;
// 函数体表达式
let b = {
let x = 2;
// 块末尾是表达式, 不是语句, 没有分号, 没有 return
x + 1
// return x + 1;
};
println!("x = {}", x); //1
println!("b = {}", b); //3
5.12.3. 函数作为参数
//
// 函数作为参数传递
//
fn inc1(num: i32) -> i32 { num + 1}
fn print_num(num: i32, func: fn(i32) ->i32) {
println!("{}", func(num));
}
print_num(1, inc1);
// mut 参数
// 这里形式参数类型并非引用, 所以传入实际参数时, 会转移所有权, 实际参数是不是 mut 都可以
fn modify (mut v: Vec<u32> ) - > Vec<u32>
// 这里形参为引用, 所以实际参数必须为 & mut
fn modify(v: &mut [u32]) ;
// 函数参数支持模式匹配
// (函数中的参数等价于一个隐式的 let绑定,而 let绑定本身是一个模式匹配的行为)
#[derive(Debug)]
struct S { i: i32 }
//表示 参数为不可变引用, 相对的, ref mut 表示参数为可变引用
fn f(ref _s: S) {
println!("{:p}", _s); //0x7ffdd1364b80
}
fn main() {
let s = S { i: 42 };
f(s);
// error, 所有权转移
println!("{:?}", s);
}
// 利用了模式匹配来解构元组
fn swap((x, y) : (&str, i32)) {}
5.12.4. Result 返回值
// 即便是没有显式返回值的函数,其实 也相当于返回了一个单元值()。如果需要返回多个值,亦可使用元组类型
/// 函数返回值 Result<T, E> 见 error_handling
///
///
5.12.5. 编译期函数执行 cfe
// 编译时函数执行, 简称 cfe
//函数会在编译期被执行, 计算出常量结果
const fn const_fn() -> u8 {2};
let arr = [0u8, const_fn()];
5.12.6. 发散函数
感叹号 惊叹号
/// 发散函数: 返回值类型为 "!" (never type), 标识函数永远不会返回值, 比如 函数包含死循环, 或者 panic
/// 发散函数可以作为任何类型. 应用:可以在正常有返回值函数中 panic, 在if 判断中 panic (因为 panic 返回类型为 never type)
/// https://www.zhihu.com/question/54540714/answer/146231560
///
5.12.7. 泛型函数
//调用时, 编译器来进行自动推断
// 无法自动推断, 则需要显式指定, 如为接收的变量指定类型, 或者方法调用的时候, 使用 turbofish操作符
let a: i32 = square(37 , 41) ;
let a= square::<u32>(37, 41)
5.12.8. 高阶函数
5.12.8.1. 函数指针
// 函数指针
//
//
// 函数可以作为参数进行传递
// 实现这一切的基础在于 Rust支持类似 CIC++语言中的函数指针
fn math(op: fn(i32, i32) -> i32, a: i32, b: i32) -> i32
//
fn hello(){
println!("hello function pointer");
}
fn main(){
// 必须显式指定函数指针类型 fn()
let fn_ptr: fn() = hello;
println!("{:p}", fn_ptr); // 0x562bacfb9f80
// 若没指定函数指针类型, 就不是指针, other_fn 的类型实际上是 fn() {hello},这其实是函数 hello 本身的类型,而非函数指针类型
let other_fn = hello;
// error
println!("{:p}", other_fn); // not function pointer
hello();
other_fn();
fn_ptr();
(fn_ptr)();
}
// 对于函数指针类型,可以使用 type 关键字为其定义别名
type MathOp = fn (i32 , i32) - > i32
fn math(op: MathOp, a: i32, b: i32) -> i32
fn math(op: &str) -> MathOp
5.12.8.2. 禁止函数捕获外部环境中变量
// error, // 因为函数不能捕捉动态环境中的变量i, 变量 绑定 i 会随着帧的释放而释放,需要闭包才可以捕获
fn counter(i: i32) -> fn(i32) -> i32 {
fn inc(n: i32) -> i32 {
n + i // error[E0434]: can't capture dynamic environment in a fn item
}
inc
}
fn main() {
let f = counter(2);
assert_eq!(3, f(1));
}
// 正确,
fn counter() -> fn(i32) -> i32 {
fn inc(n: i32) -> i32 {
n + 1
}
inc
}
fn main() {
let f = counter();
assert_eq!(2, f(1));
}
// 若果一定要捕获环境变量, 需要闭包
// 2015 edition:
fn counter(i: i32) -> Box<Fn(i32) -> i32> {//放到了 Box<T>中, 因为闭包的大 小在编译期是未知的
Box::new(move |n: i32| n + i )
}
// or 2018:
// 以大写字母 F 开头的 Fn 并不是函数指针类型 Fn(i32)->i32, 它是一个trait
fn counter(i: i32) -> impl Fn(i32) -> i32 {//动态大小类型 impl Trait, 这样就不需要使用 Box<T>了
move |n: i32|{ n + i }
}
5.13. 闭包
5.13.1. 闭包基本使用
///闭包 (匿名函数): 是一个持有外部环境变量的函数。 外部环境是指闭包定义时所在的词法作用域
///
/// 延迟执行 。
// 捕获环境变量 。闭包会获取其定义时所在作用域中的自由变 量 ,以供之后调用时使用
///
// 两个定义一模一样的闭包 也并不一定属于同 一种类型, 无法将它们保存到一个数组中。因为数组只能保 存相同类型的元素
///
fn closure_demo() {
println!("------------------------ closure demo");
let inc = |num: i32| -> i32 { ////返回值类型推导: 无论后面是否被调用, 返回值都可省略, 但是无法两次推导不同的参数/返回值类型
num + 1
};
// num 的参数类型可以省略, 返回值类型可以省略, 花括号可以省略;
//这是因为后面 print_num 函数中已经有类型信息了, 单独定义闭包, 没有后面的调用信息, 则参数类型不能省
let inc0 = |num| num+1
fn inc1(num: i32) -> i32 { num + 1}
// 函数作为参数传递
fn print_num(num: i32, func: fn(i32) ->i32) {
println!("{}", func(num));
}
print_num(1, inc1);
print_num(1, inc);
print_num(1, inc0)
5.13.2. rust 实现闭包的原理
// 在 Rust 中,闭包是一种语法糖, 是在基本语法功能之上又提供的一层方便开发者编程的语法
//
// 最初闭包是通过 装箱( Boxed) 闭包 实现的, 性能差, LLVM 难以对其进行内联和优化。
// 如: 闭包 || {a+b} 的实现可以通过函数指针 和捕获变量指针组合来实现。指针放stack上,捕获变量放到堆上
// 非装箱 CUnboxed) 闭包 (现在的实现方式): 支持闭包按值和按引用绑定环境变量 ; 支持三种不同的闭包访问, 对应 self、&self和&mut self三种方法
// 将函数调用抽象为三种, 新增三个 trait 表示
//
// 这样, 方法调用 a(b, c, d)变为一下三种执行方式:
//
// Fn::call(&a, (b, c, d)) - 调用 参数为 &self, 这意味着它会对方法接收者进行不可变借用 ,也就是说,这种方法调用可以被调用多次。
// FnMut::callmut(&muta, (b, c, d)) - 调用参数为& mut self,这意味着它会对方法接收者进行可变借用
// FnOnce::call once(a, (b, c, d)) - 调用参数为 self,这意味着它会转移方法接收者的所有权。换句话说,就是这 种方法调用只能被调用 一次
//
// 现在实现闭包就简单了, 直接定义一个 struct 表示 闭包, 内部使用一个字段表示捕获的自由变量, 在调用的时候使用这个变量即可
// 实际上, 闭包表达式会由编译器自动翻译为结构体实例,并为其实现 Fn、FnMut、FnOnce三个 trait 中的 一个
// 手动实现如下:
#![feature(unboxed_closures, fn_traits)]
struct Closure {
env_var: u32,
}
impl FnOnce<()> for Closure {
type Output = u32;
// 将函数参数中的元 组类型做动态扩展,以便支持可变长参数。
// 因为在 Fn、 FnMut、 FnOnce 这三个 trait 里的方 法要接收闭包的参数,而编译器本身并不可能知道开发者给闭包设定的参数个数,所以这里 只能传元组,然后由 rust-callABI在底层做动态扩展
// 需要 unboxed closures特性支持
extern "rust-call" fn call_once(self, args: ()) -> u32 {
println!("call it FnOnce()");
self.env_var + 2
}
}
impl FnMut<()> for Closure {
extern "rust-call" fn call_mut(&mut self, args: ()) -> u32 {
println!("call it FnMut()");
self.env_var + 2
}
}
impl Fn<()> for Closure {
extern "rust-call" fn call(&self, args: ()) -> u32 {
println!("call it Fn()");
self.env_var + 2
}
}
let env_var = 1;
let mut c = Closure { env_var: env_var };
// 结构体实例可以像函数那样被调用, 因为 定义方法时候, 使用了 extern 关键字,表示使用指定的 ABI (Application Binary Interface, 程 序二进制接口)
c();
c.call(());
c.call_mut(());
c.call_once(());
5.13.3. 捕获环境变量 and 三种闭包类型
/// 闭包中可以捕获外部环境中的变量
//捕获环境变量
// 有三种方式, 根据捕获变量方式不同, 将闭包定义为三种 trait:
//
// Fn,表示闭包以不可变借用的方式来捕获环境中的自由变 量 ,同时也表示 该闭 包没有 改变环境的能力 , 并且可以多次调用。闭包接收者是不可变引用, 对应 &self。
// 等号右侧闭包表达式 没加 move, 内部无写操作
// 未捕获任何环境变量的闭包会自动实现 Fn
// 捕获的自由变量若为复制语义类型, 则闭包实现了 Fn (不需要对外部变量进行写操作)
// 使用 move 关键字则自动实现 Fn
// FnMut,表示闭包以可变借用的方式来捕获环境中的自由变 量 ,同时意味 着该 闭包有 改变环境的能力 ,也可以 多次 调用 。 闭包接收者是可变引用, 对应&mut self。
// 没加 move, 内部有写操作
// 修改环境变量以自动实现 FnMut
// FnOnce, 表示闭包通过转移所有权来捕获环境中的自由变量,同时意味着该闭包没 有改变环境的能力,只能调用一次,因为该闭包会消耗自身。闭包接收者是值, 并非引用, 对应 self。
// 加了 move
// 由于所有所有闭包都可以至少调用一次, 所以涉及到捕获环境变量 的所有闭包都实现了 FnOnce
//
//
// 三种 trait 包含关系: fn 属于(继承于) fnmut 属于(继承于) fnonce;
// ,如果要实现 Fn, 就必须实现 FnMut和 FnOnce;如果要实现 FnMut, 就必须实现 FnOnce; 如果只需要实现 FnOnce, 就不需要实现 FnMut 和 Fn
//
//
//
// 闭包捕获其环境变量的方式:
//
// 对于复制语义类型 ,若 表达式加了 move , 以 copy 的形式进行捕获
// 若未加 move, 以 引用/可变引用 的形式进行捕获
//
// 对于移动语义类型 ,转移所有权来进行捕获 (无论加没加 move)
// 移动语义类型自动实现了 FnOnce
//
// 对于可变绑定,并且在闭包中包含对其进行修改的操 作,则以可 变引用 (&mut T) 来进行捕获 。
//
//
//
let mut i = 1;
// 修改了 自由变量, 没加 move, 闭包为 FnMut, 需要声明为 可变
let mut func = || {
i+=1;
};
func();
println!("{}", i);//2
let mut i = 1;
let mut plus_one = move || {// move 可选, 涉及到多线程并发, 一定要加 move, i 所有权移动到闭包, 对于基本类型, 相当于复制了一份, 在闭包内的操作不影响外部的 i
i += 1; // 但是 , 若有返回值, 就变为复制引用了
};
plus_one();
println!("i = {}", i); //1,
//
// 对于复杂类型的 捕获
//
let v = vec![1,2,3];
let eq = move |x| x==v; // v的所有权移动到了闭包内部, 外部的 v 失效了
println!("eq? {}", eq(vec![1,2,3]));//true
println!("v = {:?}", v);// 错误, borrow of moved value: `v`
// 更多示例对比
let mut i = 11;
// 没有 move, 闭包内部是 引用,
let mut fu1 = || i += 1;
fu1();
println!("{}", i) //12
//-----------Move的情况----------- (对于基本类型, 实现了 copy trait, 是 copy, 对于 符合类型, 若没有实现 copy trait, 则所有权转移)
// 存在 move, 闭包内是复制
let mut fu1 = move || i += 1; // 局部变量被丢弃
fu1();
println!("{}", i);//11
// 存在返回值的情况
let mut fu = || {
i += 1;
i
};
fu();
println!("{}", i)//12
//-----------Move的情况-----------
let mut fu = move || {
i += 1;
i
};
fu();
println!("{}", i)//11
//对于没有实现 Copy 的 复合类型,
// 在闭包中可以调用其方法,是“借用”,
// 存在返回值, 返回值了就发生所有权转移, 因为 返回值有可能在别的地方使用, 为了安全, 所有权转移了
//
//
let s = String::from("coolshell");
let take_str = || s; // 移动
println!("{}", s); //ERROR
println!("{}", take_str()); // OK
let mut s1 = String::from("hello");
let mut change_s1 = || s1.push('!');// 没有返回值, 不会移走, 只会可变借用
println!("{}", s1);// error, 单独出现没错, 但是和下面函数调用一起出现出错了, 可变借用后, 没法进行不可变借用了
change_s1();
println!("{}", s1);// hello!
struct Person {
name: String,
age: u8,
}
let p = Person{name: "xiaoyu".to_string(), age: 11};
let age = |p: Person| p.age; // 存在返回值, 所有权移动
println!("{}", age(p));
let name = |p: Person| p.name;
println!("{}", name(p));// name(p)编译错误, p 丢失所有权
// 改为 引用版本
//
// 对于 基本类型 的属性, 存在 copy trait, 返回的是 copy
let age = |p: &Person| p.age;
// 现在可以重复使用了
println!("{}", age(&p));
println!("{}", age(&p));
// 错误, 因为name 为 string 类型, 没有 copy trait
// 函数结束, p.name 被释放, 出错, 若存在 copy trait, 会返回 复制, 没有 copy trait, 只能通过返回引用解决
let name = |p: &People| p.name;
// 解决: 生命周期, 延缓 p.name 被释放的时间
let name: for <'a> fn(&'a Person) -> &'a String = |p: &Person| & p.name;// 闭包返回值必须为引用, 不能把 name move 走
//or ; 参数类型省略了
let name: for<'a> fn(&'a People) -> &'a String = |p| &p.name;
5.13.4. 闭包作为返回值 or 参数
5.13.4.1. 逃逸闭包 非逃逸闭包
// Box<Fn()>是一个 trait对象,
// trait对象是动态分发的,在运行时通过查找虚表( vtable〕来确定调用哪个闭包
fn boxed_closure(c: &mut Vec<Box<Fn()>>){
let s = "second";
c.push(Box::new(|| println!("first")));
// 需要将 s copy 一份, 在方法外使用
c.push(Box::new(move || println!("{}", s)));//逃逸闭包 (escapeclosure): 在函数栈帧结束后才使用的闭包, 如果是跟随函数一起调用的闭包, 则 是非逃逸闭包 (non-escape closure)。
c.push(Box::new(|| println!("third")));
}
fn main(){
let mut c: Vec<Box<Fn()>> = vec![];
boxed_closure(&mut c);
for f in c {
f(); // first / second / third
}
}
5.13.4.2. 闭包作为参数
// 实现 vec.any 条件匹配
// 通过泛型, 实现静态分发
use std::ops::Fn;
trait Any {
fn any<F>(&self, f: F) -> bool where
Self: Sized,//当Any被作为 trait 对象使用时,该方法不能被动态调用, 只能静态分发,这属于一种优化策略
F: Fn(u32) -> bool;
}
impl Any for Vec<u32> {
fn any<F>(&self, f: F) -> bool where
Self: Sized,
F: Fn(u32) -> bool
{
for &x in self {
if f(x) {
return true;
}
}
false
}
}
fn main(){
let v = vec![1,2,3];
let b = v.any(|x| x == 3);
println!("{:?}", b);
}
// 通过将闭包作为 trait 对象的方式, 实现动态分发
// 代码更加简练, 动态分发比静态分发的性能 低 一些, 但完全可以接受
trait Any {
fn any(&self, f: &(Fn(u32) -> bool)) -> bool;// &(Fn(u32) -> bool) 即为 trait object
}
impl Any for Vec<u32> {
fn any(&self, f: &(Fn(u32) -> bool)) -> bool {
for &x in self.iter() {
if f(x) {
return true;
}
}
false
}
}
fn main(){
let v = vec![1,2,3];
let b = v.any(&|x| x == 3);
println!("{:?}", b);
}
5.13.4.3. 闭包作为返回值
// 作为返回值, 必须使用 trait对象
fn square() -> Box<Fn(i32) -> i32> {
Box::new(|i| i*i )
}
// error
// 对于编译期无法确定大小的值,不能移动其所有权
// 如果要调用闭包 Box<Fn0nce(i32)->i32>, 就必须先把 Fn0nce(i32)->i32 从 Box<T>中移出 来。而此时 Box<T>中的 T无法在编译期确定大小,不能移动所有权,所以就报错
fn square() -> Box<FnOnce(i32) -> i32> {
Box::new( |i| {i*i })
}
// 正确
// 使用 impl trait 的方式
fn square() -> impl FnOnce(i32) -> i32 {
|i| {i*i }
}
//返回的闭包还必须使用 move 关键字
// 它表明闭包内所有的捕获都是通过值进行的(是一份拷贝, 是安全独立的)。
// 因为若果没有 move, 闭包是按引用捕获变量,函数结束, 闭包将引用返回, 但是引用指向的数据将被释放, 在闭包中留下无效的引用
//
fn create_fn() -> impl Fn() {
let text = "Fn".to_owned();
move || println!("This is a: {}", text)
}
fn create_fnmut() -> impl FnMut() {
let text = "FnMut".to_owned();
move || println!("This is a: {}", text)
}
let fn_plain = create_fn();
let mut fn_mut = create_fnmut();
fn_plain();
fn_mut();
5.13.4.4. 闭包参数中的生命周期
trait DoSomething<T> {
fn do_sth(&self, value: T);
}
// 为&usize类型实现了该 trait
impl<'a, T: Debug> DoSomething<T> for &'a usize {
fn do_sth(&self, value: T) {
println!("{:?}", value);
}
}
// 泛型 trait 作为 trait object时需要标注生命周期参数
// error
// 这里生命周期参数让编译器误解: 把 foo 的生命周期和内部 s 的生命周期关联起来, 即在 foo()调用的 生命周期内, s 必须始终有效
//然而 b 内部的 &usize引用 本来应该和 foo 函数没有任何关系
fn foo<'a>(b: Box<DoSomething<&'a usize>>) {
let s: usize = 10;
// s 在 foo 函数调用结束后就会被析构,从而&s就会变 成悬垂指针
b.do_sth(&s) // error[E0597]: `s` does not live long enough
}
// 正确
// 高阶生命周期 (Higher-Ranked Lifetime)语法: for<'f> , 表示此生命周期参数只针对其后面所跟 着 的“对象"
// 这里在 box 内部声明一个周期注释, 标注 &usize, 和 外层的bar 函数无关
fn bar(b: Box<for<'f> DoSomething<&'f usize>>) {
let s: usize = 10;
b.do_sth(&s);
}
fn main(){
let x = Box::new(&2usize);
foo(x); // 相当于 let _a = foo(x);
bar(x);
}
// 模拟闭包的行为
struct Pick<F> {
data: (u32, u32),// 存储闭包参数
func: F, // 存储逻辑行为
}
impl<F> Pick<F>
// trait限定中使用了 引用类型, 编译器自动为其补齐了生命周期参数
where F: Fn(&(u32, u32)) -> &u32
// 显式指定周期参数:
where F: for<'f> Fn(&'f (u32, u32)) -> &'f u32, //
{
// 生命周期参数可省略
fn call(&self) -> &u32 {
(self.func)(&self.data)
}
// 若要添加周期参数, 这种是错误的:
fn call<'a>(&’a self)一〉&’a u32, //不能让 call方法自身的生命周期和 self.func方法的生命周期相关联, 因为闭包 的捕获引用是从外部环境获取的,和 call 方法没有关系
}
fn max(data: &(u32, u32)) -> &u32 {
if data.0 > data.1{
&data.0
}else{
&data.1
}
}
fn main() {
let elm = Pick { data: (3, 1), func: max };
println!("{}", elm.call());
}
5.13.5. 迭代器
5.13.5.1. 什么是迭代器
闭包最常见的应用场景是, 在遍历集合容器中的元素的同时,按闭包内 指定的逻辑进行操作, 即迭代器
/// 迭代器
///
/// 迭代器是惰性的, 调用方法使用迭代器前, 不会有任何效果
///
/// 每个迭代器都实现 Iterator trait
///
/// trait Iterator {
/// // 这里为什么不使用 泛型呢? 若用泛型语法, 会造成这样的结果: 使用者可以通过泛型, 为一个 struct 实现多种 Iterator trait
/// // 调用时, 编译器无法知道使用哪个 trait 实现
/// type Item;// 关联元素类型
/// // 需要实现的方法 (要包含两个要点: 1. 到达某个条件返回 none; 2. 返回 cur; 3. 计算下一步的值, 赋给 cur)
/// fn next(&mut self) -> Option<Self::Item>
/// }
///
/// for 结构会使用 .into_iterator() 方法将一些集合类型 转换为迭代器
//
//
// 外部迭代器 (External Iterator): 在容器外部, 可以控制整个迭代过程 (如手动调用 next() 获取下一个元素)
// 内部迭代器 (internal Iterator):通过迭代器自身来控制迭代下一个元素,外部无法干预, 一旦开始, 必须全部迭代完毕才能结束
//
// 外部迭代器
fn main() {
let v = vec![1, 2, 3, 4, 5];
// for循环是一个典型的外部迭代器
// 其实是一个语法糖, 底层实现是 into_iter方法声明了一个可变迭代器 iterator
for i in v {
println!("{}", i);
}
}
// 等价于
fn main() {
let v = vec![1, 2, 3, 4, 5];
{ // 等价于for循环的scope
let mut _iterator = v.into_iter();
loop {
match _iterator.next() {
Some(i) => {
println!("{}", i);
}
None => break,
}
}
}
}
struct Stepper {
cur: i32,
step: i32,
max: i32,
}
impl Iterator for Stepper {
type Item = i32;
fn next(&mut self) -> Option<Self::Item> {
if self.cur > self.max {
return None;
}
let resp = self.cur;
self.cur += self.step;
Some(resp)
}
}
let stepper = Stepper {cur: 0, step: 1, max: 9};
stepper.into_iter().for_each(|it| println!("{}", it));
// 自定义内部迭代器
trait InIterator<T: Copy> {
fn each<F: Fn(T) -> T>(&mut self, f: F);
}
impl<T: Copy> InIterator<T> for Vec<T> {
fn each<F: Fn(T) -> T>(&mut self, f: F) {
let mut i = 0;
while i < self.len() {
self[i] = f(self[i]);
i += 1;
}
}
}
fn main(){
let mut v = vec![1,2,3];
v.each(|i| i * 3);
assert_eq!([3, 6, 9], &v[..3]);
}
5.13.5.2. Iterator trait
///
fn iter_demo() {
//
// 获取迭代器时, 根据对源容器的处理, 可以分为几类迭代器:
//
// - Intolter,转移所有权,对应 self。
// - Iter, 获得不可变借用 , 对应&self。
// - IterMut,获得可变借用,对应& mut self。
//
// Iter和 IterMut迭代器的典型应用就是 slice
// 特殊的: Drain 迭代器, String类型和 HashMap 特有, 可以迭代删除指定范围内的值
// 相应的就有多个获取迭代器的方法:
//
// iter() 迭代出引用, 迭代出的类型为 &T
// iter_mut() 迭代出可变引用, 类型为 &mut T
// into_iter() 迭代出值, 不是引用, 原始数据源的元素所有权变更 (推荐)
//
//size_hint() (usize, Option<usize>),此元组表示迭代器剩余长度的边界信息, 元素 1: 下限, 元素 2: 上限, 默认返回 (0, None)
// 用来和容器合作时, 精确的拓展容器容量, 从而避免不必要的容量检查,提高性能
// 对于数组, 上下限是相同的, 代表迭代器当前指针到末尾指针的距离
//
let mut v = vec![1,2,3];
for ele in v.iter() { //等同于
println!("{}", ele);
}
// 迭代出的类型为 &i32
let mut it = v.iter();
for _ in 0..3 {//`for` 遍历 `Iterator` 直到返回 `None`,每个 `Some` 值都被解包(unwrap),然后绑定给一个变量, 这里是 "_"
println!("{}", it.next().unwrap());// 需要 it 可变, 解引用可省略
}
// 迭代出可变引用
//
let mut it_mut = v.iter_mut();// 需要 v 为 可变
let ele_first = it_mut.next().unwrap();
*ele_first = 100; // 需要写操作, 先解引用
println!("v = {:?}", v); // [100,2,3]
// 迭代器的上下限, 表示
//
let a : [i32; 3]= [1, 2, 3];
let mut iter = a.iter();
assert_eq!((3, Some(3)), iter.size_hint());
iter.next();//的剩余长度就会减少, 直到减为 0为止
assert_eq!((2, Some(2)), iter.size_hint());
// 使用迭代器追加字符串
let mut message = "Hello".to_string();
message . extend (&[' ', 'R', 'u', 's', 't']) ; // 这个方法里面就用到了 size_hint 用于 String 扩容
assert_eq ! (” Hello Rust” ,& message );
// Intolterator trait
let arr = [1, 2, 3];
// 并没有为[T]类型实现 IntoIterator,需要调用 iter() 生成迭代器
for i in arr.iter() {
println!("{}", *i);
}
// 为&’a [T]和&’a mut [T]类型实现 了 Intoiterator
for i in &arr {
println!("{}", *i);
}
//
// 求和
let total: i32 = v.iter().sum();
println!("total = {}", total);
// `take(n)` 方法提取 `Iterator` 的前 `n` 项。
//
// `skip(n)` 方法移除前 `n` 项,从而缩短了 `Iterator`
//
5.13.5.3. 迭代器适配器 收集器 函数式风格
//
// 迭代器的适配器, 适配器都会返回新的集合
//
// • Map,通过对原始注代器中的每个元素调用指定 闭包来产生一个新的迭代器。
// • Chain,通过连接两个迭代器来创建一个新的迭代器。
// • Cloned,通过拷贝原始迭代器中全部元素来创建新的迭代器。
// • Cycle,创建一个永远循环迭代的迭代器,当完毕后 ,再返回第一个元素开始法代。
// • Enumerate,创建一个包含计数的迭代器,它会返回 一个元组(i,val), 其中 i 是 usize 类型 ,为迭代的 当前索 引, val 是迭代器返回 的值 。
// • Filter,创建一个基于谓词判断式( predicate,产生布尔值的表达式)过滤元素的迭代器 。
// • FlatMap,创建一个类似 Map 的结构的法代器,但是其中不会含有任何嵌套。
// • FilterMap,相当于 Filter和 Map两个法代器依次使用后的效果。
// • Fuse,创建一个可 以快速结束遍历 的迭代器。在遍历迭代器时,只 要返回过一次 None,那么之后所有的遍历结果都为 None。该迭代器适配器可以用于优化。
// • Rev,创 建一 个可以反向遍历的迭代器
//
//
// map,
// Map是一个泛型结构体,它只有两个成员字段,一个是iter, 一个f, 分别存 储的是迭代器和传入的闭包
// 实现了 Iterator trait
let a = [1, 2, 3];
let mut iter =a.into_iter() .map(|x| 2 * x);
let arr1 = [1, 2, 3, 4, 5];
let c1 = arr1.iter().map(|x| 2 * x).collect::<Vec<i32>>();
assert_eq!(&c1[..], [2, 4, 6, 8, 10]);
let arr2 = ["1", "2", "3", "h"];
let c2 = arr2.iter().filter_map(|x| x.parse().ok()).collect::<Vec<i32>>();
assert_eq!(&c2[..], [1,2,3]);
let arr3 = ['a', 'b', 'c'];
for (idx, val) in arr3.iter().enumerate() {
println!("idx: {:?}, val: {}", idx, val.to_uppercase());
}
let v = vec![1,2,3];
let scaled : Vec<i32> = v.iter().map(|&x| x * 10).collect(); // 返回新的 vec, 原始 vec 不受影响, x 不加&亦可
println!("scaled = {:?}", scaled);
let scaled1: Vec<_> = v.iter_mut().map(|&mut x| x* 10).collect(); //等效, 返回新的 vec, 不改变原始 v
println!("scaled1 = {:?}", scaled1);
println!("v = {:?}",v);//不变
let plused: Vec<_> = scaled.into_iter().map(|x| x +1).collect();// 获取scaled 所有权, 直接在原始值上修改
println!("plused = {:?}", plused);
// filter
let filtered: Vec<_> = v.into_iter().filter(|&x| x > 3).collect();// 直接在原始 vec 上修改, v 所有权失效 // 存疑, 为什么需要 &x
println!("filtered = {:?}", filtered); // [100]
println!("v = {:?}", v); // 错误, into_iter() 使得 v 失去值得所有权
// 逆序
let mut iter= a.iter().rev()
iter.next();//从反向开始迭代
// or
// 通过 普通迭代器的 next_back() 方法反向迭代
// next() 和 next_back() 有各自独立的指针, 互不影响, 但是当指针相遇时, 就迭代不出值了, 返回 none
// 收集器
//
// any 谓词, 判断
// 闭包参数为 引用
let v = vec![1,2,3];
let contain = v.iter().any(|&x| x == 2);
println!("contains 2? : {}", contain);
let contain = v.into_iter().any(|x| x == 3);
println!("contains 3? : {}", contain);
let a = [1, 2, 3];
assert_eq!(a.iter().any(|&x| x != 2), true);// 存在不为 2 的元素
let arr = [1, 2, 3];
let result1 = arr.iter().any(|&x| x != 2);
let result2 = arr.iter().any(|x| *x != 2);
// error:
// the trait bound `&{integer}: std::cmp::PartialEq<{integer}>` is not satisfied
let result2 = arr.iter().any(|x| x != 2);
assert_eq!(result1, true);
assert_eq!(result2, true);
// fold
// 闭包参数为引用
let arr = vec![1, 2, 3];
let sum1 = arr.iter().fold(0, |acc, x| acc + x);
let sum2 = arr.iter().fold(0, |acc, x| acc + *x);
let sum3 = arr.iter().fold(0, |acc, &x| acc + x);
let sum4 = arr.into_iter().fold(0, |acc, x| acc + x);
assert_eq!(sum1, 6);
assert_eq!(sum2, 6);
assert_eq!(sum3, 6);
assert_eq!(sum4, 6);
// find 查找
let v = vec![1,2,3];
let find2 = v.iter().find(|&&x| x == 2).unwrap();
println!("find2 = {}", find2);//2
let find3 = v.into_iter().find(|&x| x == 3).unwrap();
println!("find2 = {}, find3 = {}", find2, find3);// 出错
println!("find3 = {}", find3);
// 函数式风格
//
let upper = 3;
let sum: u32 =(0..).map(|n| n * n) // 所有自然数取平方
.take_while(|&n| n < upper) // 取小于上限的
.filter(|&n| is_odd(n)) // 取奇数
.fold(0, |sum, i| sum + i); // 最后加起来
println!("sum = {}", sum);
// 处理迭代中的错误
//
//
let strings = vec!["tofu", "93", "18"];
let possible_numbers: Vec<_> = strings
.into_iter()
.map(|s| s.parse::<i32>())
.filter_map(Result::ok) // 过滤出成功的result
.collect();
println!("Results: {:?}", possible_numbers);
//
// 另外的处理方式:
//Result 实现了 FromIter, Vec<Result<T, E>>可以转为 Result<Vec<T>, E>, 一旦找到一个 Result::Err ,遍历就被终止
let strings = vec!["tofu", "93", "18"];
let numbers: Result<Vec<_>, _> = strings
.into_iter()
.map(|s| s.parse::<i32>())
.collect();
println!("Results: {:?}", numbers);
//
//分组收集
//
let strings = vec!["tofu", "93", "18"];
let (numbers, errors): (Vec<_>, Vec<_>) = strings
.into_iter()
.map(|s| s.parse::<i32>())
.partition(Result::is_ok);
let numbers: Vec<_> = numbers.into_iter().map(Result::unwrap).collect();
let errors: Vec<_> = errors.into_iter().map(Result::unwrap_err).collect();
println!("Numbers: {:?}", numbers);
println!("Errors: {:?}", errors);
}
5.13.5.4. 自定义迭代器
//
// 自定义 iterator
//
struct Counter {
count: u32,
max: u32,
}
impl Counter {
fn new(max: u32) -> Self {// new 方法不能放到下面的 iterator 实现中
Counter {
count: 0,
max
}
}
}
impl Iterator for Counter {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
self.count += 1;
if self.count <= self.max {
Some(self.count)
} else {
None
}
}
}
let mut counter = Counter::new(5);
loop {
if let Some(count) = counter.next() {
println!("count = {}", count);
} else {
break;
}
}
5.13.5.5. 自定义适配器 收集器
// 第三方包Itertools 亦可实现自定义适配器
use std::iter::FromIterator;
#[derive(Debug)]
struct MyVec(Vec<i32>);
impl MyVec {
fn new() -> MyVec {
MyVec(Vec::new())
}
fn add(&mut self, elem: i32) {
self.0.push(elem);
}
}
// 实现FromIterator就可以拥有Collect的能力
impl FromIterator<i32> for MyVec {
fn from_iter<I: IntoIterator<Item = i32>>(iter: I) -> Self {
let mut c = MyVec::new();
for i in iter {
c.add(i);
}
c
}
}
fn main() {
let iter = (0..5).into_iter();
// 直接调用 MyVec::from_iter方法和使用 collect方法的效果是一样的。
let c = MyVec::from_iter(iter);
assert_eq!(c.0, vec![0, 1, 2, 3, 4]);
let iter = (0..5).into_iter();
let c: MyVec = iter.collect();
assert_eq!(c.0, vec![0, 1, 2, 3, 4]);
let iter = (0..5).into_iter();
let c = iter.collect::<MyVec>();
assert_eq!(c.0, vec![0, 1, 2, 3, 4]);
}
// 自定义适配器
// 按指定步数迭代
#[derive(Clone, Debug)]
#[must_use = "iterator adaptors are lazy and do nothing unless consumed"]
pub struct Step<I> {
iter: I,
skip: usize,
}
impl<I> Iterator for Step<I>
where I: Iterator,
{
type Item = I::Item;
fn next(&mut self) -> Option<I::Item> {
let elt = self.iter.next();
if self.skip > 0 {
self.iter.nth(self.skip - 1);
}
elt
}
}
// 产生 Step适配器
pub fn step<I>(iter: I, step: usize) -> Step<I>
where I: Iterator,
{
assert!(step != 0);
Step {
iter: iter,
skip: step - 1,
}
}
// 定义了一个继承自 Iterator 的子 trait
pub trait IterExt: Iterator {
fn step(self, n: usize) -> Step<Self>
where Self: Sized,
{
step(self, n)
}
}
impl<T: ?Sized> IterExt for T where T: Iterator {}
fn main() {
let arr = [1,2,3,4,5,6];
let sum = arr.iter().step(2).fold(0, |acc, x| acc + x);
assert_eq!(9, sum); // [1, 3, 5]
}
5.14. 条件循环
fn condition_loop() {
let a = 1;
let b;
if a > 0 {
b = 1
} else if a < 0 {
b = -1;
} else {
b = 0;
}
println!("b = {}", b);
// if 用在 let 句子中, 返回值类型相同
let c = if a > 0 { true } else { false };
println!("c = {}", c);
// while 循环
// 死循环不要使用 while true, 因为若在 循环体中 return xx; 编译器会认为无效, 编译器只会认为 while true 会返回空即 "()"
let mut d = 3;
while d > 0 {
println!("d = {}", d);
d -= 1;
}
// for 循环
let a = [3, 4, 5];
let mut i = 0;
for ele in a.iter() {
println!("a[{}] = {}", i, ele);
i += 1;
}
for i in 0..3 {// 不包括尾巴, 0..3 是一个 Range 类型, 是一个 iterator
println!("a[{}] = {}", i, a[i]);
}
//loop 循环 死循环
let s = ['R', 'U', 'N', 'O', 'O', 'B'];
let mut i = 0;
loop {
let ch = s[i];
if ch == 'O' {
break;
}
i += 1;
}
println!("O index = {}", i);
// 带返回值的 loop 循环, 用break
let mut i = 0;
let location = loop {
if s[i] == 'O' {
break i;
}
i += 1;
};
println!("O index = {}", location);
}
5.15. 泛型
5.15.1. 单态化
单态化是编译器 进行静态分发 的一种策略, 编译器要将一个泛型函数生 成多个具体类型对应的函数
好处是性能好 , 没有运行 时开销;缺点是容易造成编译后生成的二进制文件膨胀 (如 果变得太 大,可以根 据具体的情况重构代码来解决问题)
5.15.2. 多重约束 加号
trait Bound
包含 trait 限定的泛型属于静态分发,在编译期通过单态化分别生成具体类型的实例,所以调用 trait 限定中的方法也都是运行时零成本的,因为不需要在运行时再进行方法查找 。
/// 泛型
///
///
fn generic() {
fn largest<T: PartialOrd + Copy>(list: &[T]) -> T { // 多重约束使用 + 号 (且的关系)
let mut largest = list[0];
for &ele in list.iter() {
if largest < ele {
largest = ele;
}
}
largest
}
use std::ops::Add;
fn sum<T: Add<T, Output=T>>(a: T, b: T) -> T{
a + b
}
// 结构体中的泛型
//
#[derive(Debug)]
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
//有条件的实现方法
//
//
struct A<T> {}
// 这段代码声明了 A<T> 类型必须在 T 已经实现 B 和 C 特性的前提下才能有效实现此 impl 块
impl<T: B + C> A<T> {
fn d(&self) {}
}
// 使用 where 重构 trait 约束
fn foo<T, K, R>(a: T, b: K, c: R) where T: A, K: B+C, R: D {. .}
5.15.3. 默认泛型参数 and 关联类型
// 默认泛型参数, 如 std中的 Add trait:
// (为什么要使用关联类型的方式而不在泛型中指定两个参数呢?
// 使用单泛型参数更灵活, 可传可不传, 使得代码更精简)
//
// sometype 表示符号右边的类型
trait Add<SomeType=Self> {// Self 表示为泛型参数指定默认值 Self (Self是每个trait都带有的隐式类型参数, 代表实现当前 trait 的具体类型); 若实现 add 方法没有指定具体泛型, 则默认为 Self
type Output; // 关联类型
fn add(self, xx: SomeType) -> Self::Output ;
}
// string 也实现了 Add trait
let s = "hello".to_string();
let ns = s + "world";
5.15.4. 空约束
// 空约束
struct Cardinal;
struct BlueJay;
struct Turkey;
trait Red {}
trait Blue {}
impl Red for Cardinal {}
impl Blue for BlueJay {}
// 这些函数只对实现了相应的 trait 的类型有效。
fn red<T: Red>(_: &T) -> &'static str { "red" }
fn blue<T: Blue>(_: &T) -> &'static str { "blue" }
let cardinal = Cardinal;
let blue_jay = BlueJay;
let _turkey = Turkey;
// 由于约束,`red()` 不能作用于 blue_jay (蓝松鸟),反过来也一样。
println!("A cardinal is {}", red(&cardinal));
println!("A blue jay is {}", blue(&blue_jay));
println!("A turkey is {}", red(&_turkey));// 错误
5.15.5. turbofish 操作符 and 返回值自动推导
// turbofish操作符 类型推导
//
// 当 Rust 无法从上下文中自动推导出类型的时候, 可以手动指定类型
let x = "1";
println!(”{:?}”, x.parse() .unwrap()) //error, parse() 是个泛型方法
// 手动指定类型 rust 会自动类型推导
let intx:i32= x.parse().unwrap();
// 或者, 通过 turbofish 操作符
// 语法: ::<T>
assert_eq!( x.parse::<i32>().unwrap(), 1)
}
5.16. trait
5.16.1. trait 概念
5.16.1.1. trait 基本使用
///特性(trait)概念接近于 Java 中的接口(Interface)
///
fn trait_demo() {
trait Descriptive {
fn describe(&self) -> String;
// 默认 trait, 类似 java 接口默认实现
fn fn1(&self) -> String {
String::from("default impl trait")
}
}
struct Person {
name: String,
age: u8
}
// user.show() 等价于 User: :show(&user)这样的 函数调用
impl Descriptive for Person {
fn describe(&self) -> String {
format!("{} {}", self.name, self.age)
}
}
let p = Person {
name: String::from("xiaoyu"),
age: 11
};
println!("{}", p.describe());
println!("{}", p.fn1());
5.16.1.2. 孤儿规则 通过fundamental规避
orphan rule: 要为 struct b 实现某个 trait a, 则 a, b 至少有一个必须在当前 crate 中定义 (不能a, b 都是在别处定义的比如都是在 std 中定义的)
目的: 防止对别人 crate 中的类型行为进行破坏性改写
// 如 要为 u32 类型实现 add, 使得可以加上 u64 类型数字
// 直接实现 标准库中的 Add 不行, 因为 u32 和 Add 都在其他 crate 中
// 需要自己定义 在当前 crate : ˚Add trait
// 当然,除了在本地定义 Addtrait这个方法,还可以在本地创建一个新的类型,然后为此 新类型实现Add
// 局限性
// 对于一些本地类型, 如果将其放到一些容器中,比如Rc<T>或Option<T>, 那么这些本地类型就会变成远程类型 (因为这些容器类型都是在标准库中定义的 , 而非本地。)
// rust 使用 #[fundamental]的属性标识,来为特定的trait 规避孤儿限制
// Box<T>,还有 Fn、 FnMut、 FnOnce、 Sized 等都上了#[fundamental]属性
5.16.1.3. 特化 Specialization
// 问题: 重叠规则:不能为重叠的类型实现同一个trait
impl<T> AnyTrait for T
impl<T> AnyTrait for T where T: Copy // Copy 和上面的 T 重叠了
impl<T> AnyTrait for String
// 解决: 特化 (类似 java 中的方法重写/覆盖)
#![feature(specialization)]
struct Diver<T> {
inner: T,
}
trait Swimmer {
// 带有默认实现的 方法
fn swim(&self) {
println!("swimming")
}
}
// 先为 Diver<T>实现该 trait
impl<T> Swimmer for Diver<T> {}
// 为Diver<&’static str>实现了 该 trait (也就是 特殊类型, 特殊处理)
impl Swimmer for Diver<&'static str> {
fn swim(&self) {
println!("drowning, help!")
}
}
let x = Diver::<&'static str> { inner: "Bob" };
x.swim();
let y = Diver::<String> { inner: String::from("Alice") };
y.swim();
5.16.1.4. trait 作为参数 需要 impl 前缀
//
// 特性做参数
//
fn print(p: impl Descriptive) {
println!("{}", p.describe())
}
//
// 写法2: (风格类似泛型的语法糖)
fn output<T: Descriptive>(object: T) {
println!("{}", object.describe());
}
fn output_two<T: Descriptive>(arg1: T, arg2: T) {
println!("{}", arg1.describe());
println!("{}", arg2.describe());
}
//
//
//特性作类型表示时如果涉及多个特性,可以用 + 符号
fn notify(item: impl Summary + Display)
fn notify<T: Summary + Display>(item: T)
//
//复杂的实现关系可以使用 where 关键字简化
//如:
fn some_function<T: Display + Clone, U: Clone + Debug>(t: T, u: U)
//可以简化成:
fn some_function<T, U>(t: T, u: U) -> i32
where T: Display + Clone,
U: Clone + Debug
//
// 取最大值
//
trait Comparable {
fn compare(&self, object: &Self) -> i8;
}
fn max<T: Comparable>(array: &[T]) -> &T {
let mut max_index = 0;
let mut i = 1;
while i < array.len() {
if array[i].compare(&array[max_index]) > 0 {
max_index = i;
}
i += 1;
}
&array[max_index]
}
impl Comparable for f64 {
fn compare(&self, object: &f64) -> i8 {
if &self > &object { 1 }
else if &self == &object { 0 }
else { -1 }
}
}
let arr = [1.0, 3.0, 5.0, 4.0, 2.0];
println!("maximum of arr is {}", max(&arr));
5.16.1.5. trait 作为 返回值 返回动态类型
//特性做返回值
//
//
fn person() -> impl Descriptive {
Person {
name: String::from("Cali"),
age: 24
}
}
// 在同一个函数中所有可能的返回值类型必须完全一样
//如果希望返回不同的struct, 使用 Box<dyn Animal> 作为返回值 ----- 多态
//
// 错误, 因为 A, B 虽然都实现了 Descriptive, 但是 A B 是不同的类型
fn some_function(bool bl) -> impl Descriptive {
if bl {
return A {};
} else {
return B {};
}
}
//
// 那么如何返回不同的 struct?
//使用 Box<dyn xxx>, box 是一种数据结构, 效果类似引用,
//
fn random_animal(random_number: f64) -> Box<dyn Animal> {// 返回类型内存大小确定了, 编译可以通过
if random_number < 0.5 {
Box::new(Sheep {})
} else {
Box::new(Cow {})
}
}
5.16.1.6. trait 继承
//
//
trait Person1 {
fn name(&self) -> String;
}
// Implementing Student requires you to also impl Person.
trait Student: Person1 {
fn university(&self) -> String;
}
trait Programmer {
fn fav_language(&self) -> String;
}
trait CompSciStudent: Programmer + Student {
fn git_username(&self) -> String;
}
fn comp_sci_student_greeting(student: &dyn CompSciStudent) -> String {
format!(
"My name is {} and I attend {}. My Git username is {}",
student.name(),
student.university(),
student.git_username()
)
}
//
//
// 菱形继承问题: 某个 struct 实现两个 trait, 需要实现两个同名方法
//
// 完全限定语法
<Descriptive as Person>::xxx_fn() //类似于强制转换
//
// 看例子
trait UsernameWidget {
fn get(&self) -> String;
}
trait AgeWidget {
fn get(&self) -> u8;
}
struct Form {
username: String,
age: u8,
}
impl UsernameWidget for Form {
fn get(&self) -> String {
self.username.clone()
}
}
impl AgeWidget for Form {
fn get(&self) -> u8 {
self.age
}
}
let form = Form{
username: "rustacean".to_owned(),
age: 28,
};
// error, "multiple `get` found". Because, after all, there are multiple methods named `get`.
println!("{}", form.get());
//ok
let username = <Form as UsernameWidget>::get(&form);
assert_eq!("rustacean".to_owned(), username);
let age = <Form as AgeWidget>::get(&form);
assert_eq!(28, age);
}
5.16.1.7. 静态分发 动态分发
impl Trait代表静 态分发 , dyn Trait 代表动态分发 。
trait Fly {
fn can_fly(&self) -> bool;
}
struct Duck;
struct Pig;
impl Fly for Duck {
fn can_fly(&self) -> bool {
true
}
}
impl Fly for Pig {
fn can_fly(&self) -> bool {
false
}
}
// 使用泛型, 定义静态分发的函数
// 编译阶段, 泛型已经被展开 为具体类型的代码, 没有抽象开销
// or 可以使用 impl trait 改写
fn fly_static<T: Fly>(t: &T) -> bool {
t.can_fly()
}
// 使用 dyn 定义动态分发的函数
// 运行期决定到底是什么类型, 有额外开销
fn fly_dyn(t: &dyn Fly) -> bool { // 抽象类型是 trait object, 是有要求的
t.can_fly()
}
let pig = Pig;
let duck = Duck;
println!("{}", fly_static::<Pig>(&pig));
println!("{}", fly_dyn(&duck));
5.16.1.8. 使用抽象类型
5.16.1.8.1. trait对象
// AbstractType ExistentialType
// 相对于具体类型而言,抽象类型无法直接实例化, 但是它的每个实例都 是具体类型的实例
// 编译器可能无法确定其确切的功能和所占的空间大 小 。 所以 Rust 目前有两种方法来处理抽象类型: trait 对象和 impl Trait
// 方式 1: trait 对象
#[derive(Debug)]
struct Foo;
trait Bar {
fn baz(&self);
}
impl Bar for Foo {
fn baz(&self) { println!("{:?}", self) }
}
fn static_dispatch<T>(t: &T) where T:Bar {
t.baz();
}
// 动态分发, 有性能开销
fn dynamic_dispatch(t: &Bar) { // 这里参数是一个 trait object, 无法确定大小, 必须使用 引用 & or box
t.baz();
}
let foo = Foo;
static_dispatch(&foo);
dynamic_dispatch(&foo);
// 为什么 将 trait对象称为动态 分发?
//
// std 中 为 trait object 定义了一个 struct
// 包含连个指针:
// 1. data ptr
// 指向 类型数据
// 2. vtable ptr
// 指向 virtual table (cpp 中的概念), 就是一个结构体, 包含 析构函数, 大小, 方法...
//
// 在编译期 , 编译器只知道 TraitObject 包含指 针 的信息 , 并且指针的大 小 也是确定的 ,并 不知道 要 调用哪个 方法
//在运行期 , 当有 trait_object.method()方法被调 用时, TraitObject 会 根据虚表指针从虚表中查出正确的指针,然后再进行动态调用
5.16.1.8.2. trait对象安全问题 Sized trait
对象安全的本质就是为 了让 trait 对象可以安全地调用相应的方法
// 并不是每个 trait都可以作为 trait对象被使用
//每个 trait, Self默认有一个隐式的 trait 限定 ?Sized, 形如<Self: ?Sized> , ?Sized trait 包括了所有的动态大小类型和所有可确定大小 的类型。
// Rust 中大部分类型都默认是可确定大小的类型,也就是<T: Sized>,这也是泛型代 码可以正常编译的原因
//
// 当 trait对象在运行期进行动态分发,也必须确定大小,否则无法为其正确分配内存空 间 。所 以必须同时满足以下两条规则的 trait 才可以作为 trait 对象使用
// trait对象 能够编译通过的要求是, trait 必须是对象安全的, 满足:
// 1. trait 的 Self类型参数不能被限定为 Sized, 必须是 默认的 ?Sized (因为 trait objec 在编译期无法确定具体类型, 大小未知)
// 2. trait 中所有的方 法都必须是对象安全的, 满足三点之一
// - 方法受 Self: Sized 约束
// - trait 中 不能包含关联常 量( Associated Constant, 其定义方法和关联类型差不多, 只不过需要使用 const关键字)
// - 方法满足没有额外 Self类型参数的非泛型成员方法(分解开来就是三点)
// - 必须不包含任何泛型参数 (因为如果包含泛型 ,trait 对 象在 虚表Vtable中查找方法时将不确定该调用哪个方法)
// - 第一个参数必须为 Self 类型或可以解引用为 Self 的类型 (比如 self、 &self、&mutself和 self: Box<Selt>)
// - Self不能出现在除第一个参数之外的地方, 包括返回值中 (因为如果出现 Self,那就意味着 Self和 self、 &self或&mutself的类型能够相匹配。 但是对于 trait对象来说, 根本无法做到保证类型匹配)
//
// 这个trait 就无法作为 trait object在动态分发中使用, 不是对象安全的
trait Foo: Sized {...}//表示要为某类型实现 Foo,必须先实现 Sized, Foo 中 的隐式 Self被设定为是 Sized 的
// 标准的对象安全的 trait
trait Bar {
fn bax(self, x: u32);
fn bay (&self) ;
fn baz (&mut self) ;
}
// 典型的对象不安全的 trait
//
// 对象不安全的 trait
trait Foo {
fn bad<T>(&self, x: T);
fn new() -> Self;
}
//对象安全的 trait , 将不安全 的方法拆 分 出 去
trait Foo {
fn bad<T>(&self, x: T);
}
trait Bar:Foo {
fn new() -> Self;
}
//对象安全的trait,使用where子句
// 只不过在 traitFoo作为 trait对象且有?Sized限定时, 不允许调用该 new方法
trait Foo {
fn bad<T>(&self, x: T);
fn new() -> Self where Self: Sized;
}
5.16.1.8.3. impl trait
可 以静态分发的抽象类型 impl Trait, 可以用来替代泛型约束, 可以使用加号 (impl Fly+Debug)
目前 impl Trait 只可以在输入的参敬和返回值这两个位置使用
// ’static 是一种生命周期参数 , 它限定了 impl Fly+Debug 抽象类 型不可能是引用类型
fn dyn_can_fly( s : impl Fly+Debug+ ’static) -> Box<dyn Fly> {}
5.16.1.9. trait的类型转换
隐式类型转换 (Implicit Type Conversion)和显式类型转 换 (ExplicitType Conversion)
// 隐式类型转换基本上只有 自动解 引用
// 引用使用&操作符, 而解引用使用*操作符。可以通过实现Deref trait来自定
// as 操作符 最常用的场景就是转换 Rust 中的基本数据类型
let a: i64 = 11 as i64
// 短(大小)类型转换为长(大小)类型的时候是没有问题的, 但 是如果反过来,则会被 截断处理
// 当从有符号类型 向无符号类型转换 的时候, 最好使用标准库中提供的专门的方法,而不要直接使用 as操作符
// 类型和子类型相互转换
// 生命周期标记可看作子类型。 比如&’static str类型是&’a str类型的子类 型;
//’a 和 'static 都是生命周期标记,其中’a 是泛型标记, 是 &str的通用形式, 而’static则是特指静态生命周期的&str字符串
5.16.2. 可自动推导的trait
// 推导 派生 trait
// 下面以下是可以自动推导的 trait
/*
Eq, PartialEq, Ord, PartialOrd (比较类的 trait)
Clone, 用来从 &T 创建副本 T。当处理资源时,默认的行为是在赋值或函数调用的同时将它们转移。但是我们有时候也需要 把资源复制一份。
- 包括 clone, colon_from 方法
- 如果一个类型是 Copy的, 它的clone方法仅需要返回*self即可
- 使用需要显式调用 clone(), 若希望rust 碰到 等号赋值了就自动隐式调用 clone() , 需要给结构体加上 derive(Clone, Copy),
Copy,使类型具有 “复制语义”(copy semantics)而非 “移动语义”(move semantics)。
copy trait 无法单独使用, 必须在 Clone trait 存在的情况下才能使用
Hash,从 &T 计算哈希值(hash)。
Debug,使用 {:?} formatter 来格式化一个值
Serialize Deserialize
*/
#[derive(Debug, Clone, Copy)]
struct Nil;
// `Centimeters`,可以比较的元组结构体
#[derive(PartialEq, PartialOrd)]
struct Centimeters(f64);
// `Inches`,可以打印的元组结构体
#[derive(Debug)]
struct Inches(i32);
impl Inches {
fn to_centimeters(&self) -> Centimeters {
let &Inches(inches) = self;
Centimeters(inches as f64 * 2.54)
}
}
let foot = Inches(12);
println!("One foot equals {:?}", foot);
let meter = Centimeters(100.0);
let cmp =
if foot.to_centimeters() < meter {
"smaller"
} else {
"bigger"
};
println!("One foot is {} than one meter.", cmp);
// `Seconds`,不带附加属性的元组结构体
struct Seconds(i32);
let _one_second = Seconds(1);
// 报错:`Seconds` 不能打印;它没有实现 `Debug` trait
println!("One second looks like: {:?}", _one_second);
// 报错:`Seconds`不能比较;它没有实现 `PartialEq` trait
let _this_is_true = (_one_second == _one_second);
5.16.3. 运算符重载相关的trait
操作符重载
//
//
// 很多运算符可以通过 trait 来重载
//这些运算符可以根据它们的 输入参数来完成不同的任务。这之所以可行,
//是因为运算符就是方法调用的语法糖。例 如,a + b 中的 + 运算符会调用 add 方法(也就是 a.add(b))。这个 add 方 法是 Add trait 的一部分
//
// Add trait 重载 + 运算符
//
/// Deref trait 重载解引用符号, 就是 "*" 号
//
//在 std::ops 下有全部重载的 trait
// 在std::cmp 下则是比较操作的操作符
//
//
// 例子: 对象排序
//
// 有四个Trait : Ord、PartialOrd 、Eq 和 PartialEq 。
//
use std::cmp::{Ord, PartialOrd, PartialEq, Ordering};
#[derive(Debug)]
struct Employee {
name : String,
salary : i32,
}
impl Ord for Employee {
fn cmp(&self, rhs: &Self) -> Ordering {
self.salary.cmp(&rhs.salary)
}
}
impl PartialOrd for Employee {
fn partial_cmp(&self, rhs: &Self) -> Option<Ordering> {
Some(self.cmp(rhs))
}
}
impl Eq for Employee {
}
impl PartialEq for Employee {
fn eq(&self, rhs: &Self) -> bool {
self.salary == rhs.salary
}
}
//使用
let mut v = vec![
Employee {name : String::from("Bob"), salary: 2048},
Employee {name : String::from("Alice"), salary: 3208},
Employee {name : String::from("Tom"), salary: 2359},
Employee {name : String::from("Jack"), salary: 4865},
Employee {name : String::from("Marray"), salary: 3743},
Employee {name : String::from("Hao"), salary: 2964},
Employee {name : String::from("Chen"), salary: 4197},
];
//用for-loop找出薪水最多的人
let mut e = &v[0];
for i in 0..v.len() {
if *e < v[i] {
e = &v[i];
}
}
println!("max = {:?}", e);
//使用标准的方法
println!("min = {:?}", v.iter().min().unwrap());
println!("max = {:?}", v.iter().max().unwrap());
//使用标准的排序方法
v.sort();
println!("{:?}", v);
5.16.4. From 和 Into
// 定义于 std::convert 模块中的两个 trait。 它们定义了 from 和 into 两个方 法,这两个方法互为反操作
let s = String: :from(”hello”);
struct Person {
name, String,
}
impl Person {
//允许传入的参数是&str类型或 String 类型 ,方便进行开发 (&str和 String类型都实现了 Into, 当参数是&str类型时,会通过 into转换为 String)
fn new<T: Into<String>>(name: T) -> Self {
Person {name: name.into()}
}
}
// 如果类型 U实现了 From<T>,则 T类型实例调用 into方 法就可以转换为类型 U (rust 自动帮我们实现了 Into)
// impl<T, U> Into<U> for T where U: From<T> {}
// 所以 , 一般情况下 , 只需要实现 From 即可 , 除非 From 不容易实现,才需要考虑实 现 Into
let a = "hello";
let b:String = a.into();//String 类型实现了 From<&str>,所以可以使用 into 方法将 &str 转换为 String
// TryFrom 和 TryInto 两种 trait,是 From 和 Into 的错误处理版本
5.16.5. DerefMut 和 Deref
用于自定义解除引用运算符(*)的行为
let a = 11;
let b = Box::new(a);
print!("Value of *b is {}",*b); //11, box 可以像普通引用一样解引用
// 构造自己的 box
#[derive(Debug)]
struct MyBox<T>(T);
impl<T> MyBox<T> {
pub fn new(v: T) -> Self {
return MyBox(v);
}
}
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &Self::Target {
&self.0
}
}
let b = MyBox::new(32);
println!("{:?}", b);
println!("b inner = {}", *b); //32
println!("b inner2 = {}", *b.deref());// 32, deref() 返回内部数据的引用
//自动解包 , deref 的强制效果
fn prin(v: &i32) {
println!("{}", v);
}
prin(&b) // 自动将 &MyBox 包装解除, 成为 &i32
// 如果一个类型 T 实现了 Deref<Target=U>, 则该类型 T 的引用 (或智能指针)在应用的时候会被 自动转换为类型 U
// String类型实现了 Deref
let a = "hello".to_string();
let b = " world".to_string();
let c = a+&b;//&b,它应该是一个&Sting类型,而 String类型实现的 add方法的右值参数必须是&str类型, 但现在它是可 以正常运行的。原因就是 String 类型实 现了 Deref<Target=str>
println!(”{:?)’”, c); // "hello world"
// 标准库中常用的其他类型都实现了 Deref, 比如 Vec<T>
fn foo(s : &[i32]){}
let v= vec![1,2,3)
foo(&v);//所以&Vec<T> 会被自动转换为 &[T]类型,
// Box<T>、 Rc<T>、 Arc<T>
let x = Rc::new("hello");
println1 (”{:?}”, x.chars());
// 当某类型和其解引用目标类型中包含了相同的方法时,编译器不知道该用哪一个了,此时就需要手动解引用
// clone方法在Rc和&str类型中都被实现了,所以调用时会直接调用 Rc 的 clone 方法,如果想调用 Rc 里面 &str 类型的 clone 方法,则需要使用“解 引用”操作 符 手动解引用
let x= Rc::new(”hello”),
let y=x.clone(); //Rc<&str>的 clone 方法
let z = (*x) .clone() ; // &str 的 clone 方法
// match 引用时也需要手动解引用
//
let x = "hello". to_string ();
match &x {//手动解引用把& String 类型转换成& str
// match x.deref(),
//match x.as_ref()
//match x.borrow()
//match &*x 使用“解引用 ”操作符,将 String转换为 str,然后再用“引用”操作符转为& str
//match&x[..],这是因为String类型的index操作可以返回&由类型
"hello" => {println! ("xxx")}
}
// DerefMut和 Deref类似, 只不过它是返回可变引用的。 Deref中包含关联类型 Target, 它表示解引用之后的目标类型
5.16.6. AsRef AsMut
可以将值分别转换为不可变引用和 可变引用
AsRef和标准库的另外一个 Borrow trait功能有些类似,但是 AsRef比较轻量级, 它只是简单地将值转换为引用,而 Borrow trait 可以用来将某个复合类型抽象为拥有借用语义 的类型
5.16.7. Borrow trait
5.16.8. Drop 资源释放
//
//
// 释放资源 Drop trait
/*
Drop trait 只有一个方法:drop,当对象离开作用域时系统会进行资源释放, 同时会自动调用该 方法, 用于释放类似于文件或网络连接的资源。, 这个方法不允许手动调用, 编译器会自动调用, 用于释放类似于文件或网络连接的资源, 或者释放 box 所指向的堆空间
也可以 drop(a) 手动调用释放, 使用 std::mem::drop(xxx)
Box,Vec,String,File,以及 Process 是一些实现了 Drop trait 来释放 资源的类型。
*/
// 析构顺序
//
// - 本地变量遵循先声明的变量后析构的规则 (这也缘于桔结构先进后 出的特性)
// - 元组整体来说也属于本地变量, 所以析构顺序和局部变量的析构顺序一致
// 但内部元素是按元素的出现顺序依次进行析构的
// - 结构体和枚举体 内部元素按照定义时的次序析构 (类似元组的析构)
// - 闭包捕获变 量 的析构顺序和闭包内该变量的排列顺序 一致, 与捕获变 量声 明的顺序是没有关系的
//
struct PrintDrop(&'static str);
impl Drop for PrintDrop {
fn drop(&mut self) {
println!("Dropping {}", self.0)
}
}
// 顺序: y, x
let x = PrintDrop("x");
let y = PrintDrop("y");
// 顺序: x, y, z, a,b,c
let tup1 = (PrintDrop("a"), PrintDrop("b"), PrintDrop("c"));
let tup2 = (PrintDrop("x"), PrintDrop("y"), PrintDrop("z"));
// 顺序: y,x, a,b,c
let tup1 = (PrintDrop("a"), PrintDrop("b"), PrintDrop("c"));
let tup2 = (PrintDrop("x"), PrintDrop("y"), panic!());//线程的崩愤触发了 tup2 的提前析构, 这 种提前析构的顺序正好和局部变量的析构顺序一致: 先声明的元素后析构。
// 屏蔽 规避 drop 检查(跳过 内存自动释放)
//
//
struct A;
struct B;
struct Foo {
a: A,
b: B
}
impl Foo {
fn take(self) -> (A, B) {
// error[E0509]: cannot move out of type `Foo`, which implements the `Drop` trait
// 因为 drop 方法中可能还需要用到这两个字段, 所以不能将他们的所有权移动到外部
(self.a, self.b)
}
// 正确:
// 重新实现take
fn take(mut self) -> (A, B) {
// 通过std::mem::uninitialized()进行伪初始化
// 用于跳过Rust的内存初始化检查
// 如果此时对a或b进行读写,则有UB(引发未定义行为)风险,一般只用于 FFI和 C语言交五
let a = std::mem::replace(
&mut self.a, unsafe { std::mem::uninitialized() }
);
let b = std::mem::replace(
&mut self.b, unsafe { std::mem::uninitialized() }
);
// 通过forget避免调用结构体实例的drop
// 这样, 析构函数就不会被自动调用, 需要我们在某个地方手动释放内存
std::mem::forget(self);
(a, b)
}
}
// 若不实现 Drop 则上面代码不会报错
impl Drop for Foo {
fn drop(&mut self) {
// do something
}
}
// 另外的手动释放内存的方式
// ManuallyDrop<T>是一个联合体,Rust不会为联合体自动实现Drop。 因为联合体是所有字段共用内存,不能随便被析构,否则会引起未定义行为
// (std::mem::forget<T>函数的实现就是用了ManuallyDrop::new方法)
//
use std::mem::ManuallyDrop;
struct Peach;
struct Banana;
struct Melon;
struct FruitBox {
peach: ManuallyDrop<Peach>,
melon: Melon,
banana: ManuallyDrop<Banana>,
}
impl Drop for FruitBox {
fn drop(&mut self) {
unsafe {
ManuallyDrop::drop(&mut self.peach);// 手动释放
ManuallyDrop::drop(&mut self.banana);
}
}
}
5.16.9. 标签 trait
即 内部没有任何内容的 trait, 只是作为一个标签, 起到标识作用
5.16.9.1. Send 和 Sync
一般编译器帮我们自动实现了
// 可以安全地跨线程传递和访 问 的类型用 Send 和 Sync 标记,否则用! Send 和!Sync 标记 , 这样编译器在编译时就能检出数据竞争的隐患, 而不需要等到运行时再排查
// 实现了 Send 的类型 ,可以安全地在线程间传递所有权, 即可以跨线程移动
// 实现了 Sync 的类型 ,可以跨线程安全地传递不可变引用 , 即可以跨线程共享。
//
// 之所以可以正常地move变量,也是因为数组x中的元素均为原生数据类型, 默认都实现了 Send 和 Sync 标签 trait,所以它们跨线程传递和访问都很安全
let mut x=vec![1, 2, 3, 4] ;
thread::spawn(move || x.push(1));
// error
//Rc 没有实 现 Send 和 Sync,所以不能在线程之间传递变 量 x
// 因为 Rc是用于引用计数的智能指针, 如果把 Rc类型的变量 x传递到另一个线程中,会 导致不同线程的 Rc 变量引用同一块数据, Rc 内 部实现并没有做任何线程同步的处理
let x = Rc::new(vec! [1, 2, 3, 4]);//
thread::spawn( move || x[1]);
// 对于自定义的数据类型,如果其成员类型全部实现 Send 和 Sync,此类型才会被自 动实现 Send 和 Sync
5.16.9.2. Copy trait
区分值语义和引用语义
// Copy trait,用来标识 可 以按位 复制其值 的类型
// Copy 告诉编译器这个类型默认采用 copy 语义,而不是 move 语义; 在执行变量绑定、函数参数传递、函数返回等场景下, 执行的是内存拷贝操作
// 引用类型无法实现 copy trait, 虽然引用语义类型不能实现 Copy, 但可以实现 Clone 的 clone 方法, 以 实现深复制
// Copy trait继承自 Clone trait, 要实现 Copy trait 的类型,必须实现 Clone trait 中定义的方法
// Rust 提供了更方便的 derive 属性供我们完成这项重复的工作
#[derive (Copy , Clone)]
struct xxx {}
// 某个类型标注为 Copy后, 就不能随便实现 Clone 的 clone 方法了, 调用 t.clone() 时, 执行的操作必须等同于“简单内存拷贝”;
// 所以 一般使用 #[derive(Copy, Clone)] 这种方式,这种情况下它们俩最好一起出现,避免手工实现 Clone 导致错误
// Rust 为很多基本数据类型实现了 Copy trait,比如常用的数字类型、字符( Char)、布尔 类型、单元值、不可变引用等
// 检测哪些类型实现 了 Copy trait:
fn test copy<T: Copy>(t : T) { //如果实现了Copy trait的类型, 则可以正常编译: 如果没有实现,则会报错。
println(”hhh”);
}
// 并非所有类型都可以 实现 Copy trait。
// 对于自定义类型来说,必须让所有的成员都实现 了 Copy trait, 这个类型才有资格 实现 Copy trait。
// 如果是数组类型 , 且其内部元素都是 Copy 类型, 则数组本身就是 Copy 类型;
// 如果是元组类型,且其内部元素都是 Copy 类型, 则该元 组会自动实现Copy
5.16.9.3. Sized trait 和 动态类型DST
// sized trait 用来标识编译期可确定大小的类型
//
// Unsize trait, 目前该 trait 为实验特性,用于标识动态大小类型 (DST)
// Dynamical sized type -> DST
// 运行期才知道大小的类型
// 如 str (不是 &str 哦), 编译器不可知大小
// &str 这个类型的值包含两个部分, str 的地址, str 的长度, 所以 &str 的大小类型可以确定 即 2*usize
// 如 trait object, 都是动态类型
// 如[T], 未知类型的数组
// 如 包含 DST 的 struct/tuple
// 所以为了能够编译通过, 必须将动态类型放到指针背后, 指针时 "fat pointe"
//
// compiler默认为 类型加上了 Sized trait, 如:
fn xxx<T: Sized>(t: T); // 指定 t 为可知大小类型, Sized 可省略, 编译器默认添加了
// ?Sized 包含 Sized 和 unsized
fn xxx<T: ?Sized> (t: T);// t 为 编译期间不可知大小的类型 or 为 可知大小类型, 告诉 编译器, 到底是那种类型不确定
// 但是动态大小类型不能随意使用,还需要遵循如下三条限制规则:
//
// 1. 只可以通过胖指针来操作 Unsize类型,比如&[T]或&Trait
// 2. 变量、参数和枚举变量不能使用动态大小类型
// 3. 结构体中只有最后一个字段可以使用动态大小类型,其他字段不可以使用
5.16.10. Default trait
// 为 struct 提供默认值
struct ColoredString {
input: String,
fgcolor: String,
bgcolor: String,
}
impl Default for ColoredString {
fn default() -> Self {
ColoredString {
input: String::default(),// 这样使用即可
fgcolor: String::new(),
bgcolor: String::new(),
}
}
}
5.16.11. Extend trait
// 通过 iterator中的元素, 扩充集合
// 包含方法:
// fn extend<T: IntoIterator<Item = A>>(&mut self, iter: T);
let mut s = "Hello".to_owned();
s.extend(&[' ', 'R', 'u', 's', 't']);
println!("{}", s);//Hello Rust
// String 刚好实现了这个 trait
5.16.12. Any trait
// use std::any::Any;
5.16.13. 和比较排序相关的trait
// PartialEq、 Eq、 PartialOrd 和 Ord
// - PartialEq代表部分等价关系,其中定义了 eq和 ne (不等, 有默认实现)两个方法
// - Eq 代表等价关系,该 trait 继承自 PartialEq, 但是其中没有定义任何方法 。 它实际上 相当于标记实现了 Eq 的类型拥有等价关系
// - PartialOrd对应于偏序,其中定义了 partial_cmp (必须实现)、 lt、 le(小于等于)、 gt和 ge五个方法
// - Ord对应于全序,其中定义了 cmp、 max和 min三个方法
//
// 枚举体为 Ordering, 用于表示 比较结果,其中定义了 小于、等于和大于三种状态。
let mut v = [-5i32, 4, 1, -3, 2];
// 默认升序
v.sort();
assert!(v == [-5, -3, 1, 2, 4]);
// 而 sort_by 是按 a 和 b 的比较结果是否等于 Less 的规则进行排序 的, 若等于 less, 则 a 小于 b,为升序排列
v.sort_by(|a, b| a.cmp(b));
assert!(v == [-5, -3, 1, 2, 4]);
v.sort_by(|a, b| b.cmp(a));
assert!(v == [4, 2, 1, -3, -5]);
v.sort_by_key(|k| k.abs());
assert!(v == [1, 2, -3, 4, -5]);
let result = 1.0.partial_cmp(&2.0);//浮点数,只能用偏序比较
assert_eq!(result, Some(Ordering::Less));
let result = 1.cmp(&1);
assert_eq!(result, Ordering::Equal);
let result = "abc".partial_cmp(&"Abc");
assert_eq!(result, Some(Ordering::Greater));
let mut v: [f32; 5] = [5.0, 4.1, 1.2, 3.4, 2.5];
v.sort_by(|a, b| a.partial_cmp(b).unwrap());
assert!(v == [1.2, 2.5, 3.4, 4.1, 5.0]);
v.sort_by(|a, b| b.partial_cmp(a).unwrap());
assert!(v == [5.0, 4.1, 3.4, 2.5, 1.2]);
5.17. 元组
// 元组,
//类型可以不同
const tup: (i32, f64, u8, &'static str) = (500, 6.4, 1, "holla");
// tup.0 等于 500
// tup.1 等于 6.4
// tup.2 等于 1
// 结构元组
let (x, y, z, w) = tup;
// y 等于 6.4
// 当元组中只有一个值的时候,需要加逗号,即(0,)
// 空元组 / 单元类型
()
// 零大小类型(Zero Sized Type, ZST), 不占空间
//
// 使用场景:
// 1. 在开发时, 查看数据类型;
let a: () = vec![();10];// error, 提示 expected (), foundstruct 、std: :vec·:Vee, 这样就知道了右值 vec![(); 10]是向量类型
// 2. 在需要循环指定次数的位置, 用来提高性能 (因为 Vee 内部迭代器中 会针对 ZST 类型做一些优化)
let v: Vee<()>= vec![(); 10];
for i in v {
// xxx
}
// 3. 官方标准库 中的 HashSet<T> 和 BTreeSet<T>
// 其实只是把 HashMap<K, T>换成了 HashMap<K, ()>, 然后就可 以共用 HashMap<K, T>之前的代码,而不需要再重新实现一遍 HashSet<T>了。
5.18. 结构体
5.18.1. 结构体基本使用
/// 结构体
/// 结构体(Struct)与元组(Tuple)都可以将若干个类型不一定相同的数据捆绑在一起形成整体
/// 但是结构体可以给每个数据起个名字
/// 这样访问它成员的时候就不用记住下标了
///
/// 和 c 不同, Rust 里 struct 语句仅用来定义,不能声明实例,结尾不需要 ; 符号
/// 和 go 不同, rust 的 struct 无法嵌套, 只能分成多个 struct 来定义
///
/// 结构体必须掌握字段值所有权,因为结构体失效的时候会释放所有字段, 所以字符串字段使用 String 不用 &str (因为 &str 是借用的所有权)
///
/// 没有身体的结构体为单元结构体(Unit Struct), 如 struct UnitStruct;
///
///
fn struct_demo() {
// 定义
#[derive(Debug)] // 在定义 struct 时导入调试库, 才能 print
struct Site {
domain: String,
name: String,
nation: String,
found: u32,
}
// 实例化, 若是空 struct, let inner_a = InnerA {};
let domain = String::from("xiaoyureed.github.io");
let st = Site {
domain, // 有字段名称和现存变量名称一样的,可以简化书写, 类似 JavaScript
name: String::from("xiaoyu"),
nation: String::from("China"),
found: 2013,
};
// 部分更新
// 因为没有实现了 Copy trait, 所有 st 所有权会转移
let st1 = Site {
domain: String::from("new domain"),
..st
};
// 输出结构体
// 需要定义 struct 时导入调试库 #[derive(Debug)]
println!("st = {:?}", st1);
// 格式化输出 {:#?}
println!("st = {:#?}", st1);
// 只有 成员都为 复制语义, struct 才能自动 Copy derive
#[derive(Debug,Copy,Clone)]
struct Book<'a> {
name: &'a str,
isbn: i32,
version: i32,
}
fn main(){
let book = Book {
name: "Rust编程之道" , isbn: 20181212, version: 1
};
let book2 = Book { version: 2, ..book};
println!("{:?}",book);// book 由于 实现 了 Copy trait, 所有权没有转移
println!("{:?}",book2);
}
5.18.2. 元组结构体 and 单元结构体
// 元组结构体
// 简化的结构体, 没有字段名称, 只有字段类型
// 是为了处理那些需要定义类型(经常使用)又不想太复杂的简单数据
struct Color(u8, u8, u8);
struct Point(f64, f64);
let black = Color(0, 0, 0);
let origin = Point(0.0, 0.0);
// 使用和元组一样, 通过下标访问字段
println!("black = ({}, {}, {})", black.0, black.1, black.2);
println!("origin = ({}, {})", origin.0, origin.1);
// 直接打印结构体 错误
// 要打印, 两种方法:
// 1. 定义 struct 时继承 #[derive(Debug)], 然后 使用 {:?} or {:#?} 打印
// 2. 为 struct 实现 fmt::Display 接口, 然后使用 {} 即可
// println!("tuple struct - {}", black);
// 单元结构体 即 空的结构体, 零大小类型(Zero Sized Type, ZST), 不占空间
//
// 在Debug编译模式下, 多个 空结构体 实例是不同 的对象
// 在在Release编译模式下, 会被优化为同一个 对象 (内存地址相同)
//
// 标准库中表示全范围()的 RangeFull, 就是一个单元结构体
5.18.3. 结构体方法
//
// 结构体方法
//
impl Site {
// &self 关键字 总是第一个参数, 类似 Python
fn to_string(&self) -> String {
// self 表示 struct 实例
format!("to string -> {:?}", self)
}
}
println!("st.to_string() = {}", st.to_string());
//
// 结构体关联函数
//类似 Java 中的静态方法, 调用不依赖 struct 实例
//
//没有 &self 参数
impl Site {
fn create() -> Site { // Site 可用 Self 替代
Site {
domain: String::from("new domain create()"),
name: String::from("xiaoyu"),
nation: String::from("nation"),
found: 2020,
}
}
}
let create_site = Site::create();
println!("create_site = {:?}", create_site);
5.18.4. new type 模式 和 类型别名 Self别名
当一个元组结构体只有一个字段的时候,称之为 New Type 模式
// 使用场景:
// - 明确语义: 为同类型的数据分别定义新的类型进行区分, 如 为 i32 类型分别定义 Hour, Second 类型 (这是为了能保证在编译时,编译期间即可发现错误。), 包装了一层
// - 使复制语义的 类型具有移动语义; 比如 f64 本来是复制语义 ,而包装为 Miles(f64)之 后,因为结构体本身不能被自动实现 Copy,所以 Miles(f64)就成了移动语义。
// - 隐藏实际类型, 限制功能; 使用 Newtype模式包装的类型并不能被外界访问,除非提 供相应方法。
// - 给标准库中的结构实现标库中的 trait, 如给 Vector 实现 Display trait.
// 由于孤儿规则, 这明显不行, 可以通过给 Vector 包装一层来达到目的
struct Wrapper(Vec<String>);
impl std::fmt::Display for Wrapper {
fn .....
}
//new type 惯用法
//
//
struct Years(i64);
struct Days(i64);
impl Years {
pub fn to_days(&self) -> Days {
Days(self.0 * 365)
}
}
impl Days {
/// 舍去不满一年的部分
pub fn to_years(&self) -> Years {
Years(self.0 / 365)
}
}
fn old_enough(age: &Years) -> bool {
age.0 >= 18
}
let age = Years(5);
let age_days = age.to_days();
println!("Old enough {}", old_enough(&age));// 只能传年单位的数字
println!("Old enough {}", old_enough(&age_days.to_years()));
println!("Old enough {}", old_enough(&age_days)); //出错, 编译期间即可发现 // 不能传天单位的数字
// 类型别名
// 也可以使用 type关键字为一个类型创建别名,如代码第 2行为 i32类型创建了一个别名 Int, 但是其本质还是 i32 类型,它所拥有的行为和 i32 是一样 的 。相 比之下, New Type 模式 属于 自定义类型,更加灵活
//别名的主要用途是避免写出冗长的模板化代码(boilerplate code)。如 IoResult<T> 是 Result<T, IoError> 类型的别名。
enum VeryVerboseEnumOfThingsToDoWithNumbers {
Add,
Subtract,
}
// Creates a type alias
type Operations = VeryVerboseEnumOfThingsToDoWithNumbers;
let x = Operations::Add; // 能这么用
impl VeryVerboseEnumOfThingsToDoWithNumbers {
fn run(&self, x: i32, y: i32) -> i32 {
match self {
// Self 别名
Self::Add => x + y,
Self::Subtract => x - y,
}
}
}
// `NanoSecond` 是 `u64` 的新名字。
type NanoSecond = u64;
type Inch = u64;
// 通过这个属性屏蔽警告。
#[allow(non_camel_case_types)]
type u64_t = u64;
// `NanoSecond` = `Inch` = `u64_t` = `u64`.
let nanoseconds: NanoSecond = 5 as u64_t;
let inches: Inch = 2 as u64_t;
}
5.18.5. 案例 彩色命令行输出
main.rs
mod color;
use color::Colorized;
fn main() {
let s= "hello".red().on_yellow();
println!("{}", s);
}
color.rs
use std::fmt::Display;
pub struct ColorString {
input: String, // 内容
fg: String, // 前景
bg: String, // 背景
}
// 实现默认值, 对 color string 进行初始填充
impl Default for ColorString {
fn default() -> Self {
ColorString {
input: String::default(),
fg: String::default(),
bg: String::default(),
}
}
}
pub trait Colorized {
// 关联常量, 和联类型类似, 由实现该 trait 的类型来指定常量的值
// 这里指定了默认值
const FG_RED: &'static str = "31";
const BG_YELLOW: &'static str = "43";
fn red(self) -> ColorString;
fn on_yellow(self) -> ColorString;
}
impl Colorized for ColorString {
fn red(self) -> ColorString {
ColorString {
fg: String::from(Self::FG_RED),
..self
}
}
fn on_yellow(self) -> ColorString {
ColorString {
bg: String::from(Self::BG_YELLOW),
..self
}
}
const FG_RED: &'static str = "31";
const BG_YELLOW: &'static str = "43";
}
impl<'a> Colorized for &'a str {
fn red(self) -> ColorString {
ColorString {
input: String::from(self),
fg: String::from(Self::FG_RED),
..ColorString::default()
}
}
fn on_yellow(self) -> ColorString {
ColorString {
input: String::from(self),
bg: String::from(Self::BG_YELLOW),
..ColorString::default()
}
}
const FG_RED: &'static str = "31";
const BG_YELLOW: &'static str = "43";
}
impl ColorString{
// 组装 ansi 码
// \xlB[43;31m,
fn compute_style(&self) -> String {
let mut res = String::from("\x1B[");// ansi 码起始
let mut has_wrote = false;
if !self.bg.is_empty() {
res.push_str(&self.bg);
has_wrote = true;
}
if !self.fg.is_empty() {
if has_wrote {
res.push(';');
}
res.push_str(&self.fg);
}
res.push('m');// ansi 码结束
res
}
}
impl Display for ColorString {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
f.write_str(&self.compute_style())?;
write!(f, "{}", self.input)?;
write!(f, "\x1B[0m")?;
Ok(())
}
}
5.19. 枚举
5.19.1. 枚举基本使用
/// 枚举类
///
/// 枚举元素可以各不相同
///
fn enum_demo() {
println!("-------------enum demo-----------------------");
enum Resp<T, E> {
Obj(T),
Err(E),
}
fn divide(a: i32, b: i32) -> Resp<i32, String> {
if b == 0 {
return Resp::Err("分母不能为零".to_owned());
}
Resp::Obj(a / b)
}
let a = divide(4, 2);
let b = divide(4, 0);
match a {
Resp::Obj(n) => println!("n: {}", n),
_ => {}
}
match b {
Resp::Err(msg) => println!("msg: {}", &msg),
_ => {}
}
#[derive(Debug)]
enum Book {
Papery,
Book1(i32),
Book2(String),
Book3 {field1: String, field2: String},
}
let book = Book::Papery;
println!(" enum book = {:?}", book);
// 实例化带属性的枚举类
let boot1 = Book::Book1(11);
// 错误, 没这个语法
println!("book1.0 = {}", boot1.0);
// 正确
println!("book1 = {:?}", boot1);
// 访问枚举类的属性, 必须借助 match
let book3 = Book::Book3{
field1: String::from("hello"),
field2: String::from("world"),
};
match book3 {
Book::Papery => println!("book"),
// 对于 元组, 由于没有字段名称, 需要临时指定一个形参
Book::Book1(i) => println!("book1.i = {}", i),
Book::Book2(s) => println!("book2.s = {}", s),
Book::Book3{field1, field2} => {
println!("book3.field1 = {}, book3.field2 = {}", field1, field2);
},
_ => println!("no match"),
}
5.19.2. Option
// Option 枚举类
//是 Rust 标准库中的枚举类,这个类用于填补 Rust 不支持 null 引用的空白
//
// enum Option<T> {
// Some(T),
// None,
// }
//
// 使用场景:
// - 初始化值
// - 作为函数的返回值, 表示空, or 出现的简单错误
// - 作为函数可选参数
// - 作为结构体的可选字段
// - 作为结构体中可借出/载入的字段
// - 代表空指针
// 解开可以通过 match 模式匹配,
// or:
// 通过 unwrap 系列方法
// - expect("error message") 解开 Some, 若 None, 则 panic!("error message")
// - unwrap() 解开 Some, 若碰到 None, 则 panic
// - unwrap_or(T) 解开 Some, 若碰到 None, 则 返回指定的默认值
// - unwrap_or_else(FnOnce()->T) 解开 Some, 碰到 None, 则执行一段闭包
let opt = Option::Some("Hello"); // opt 允许为空
match opt {
Option::Some(something) => {
println!("{}", something);
},
Option::None => {
println!("opt is nothing");
}
}
// 直接定义一个 &str 类型的空值
//Option 是 Rust 编译器默认引入的,在使用时可以省略 Option:: 直接写 None 或者 Some()。
let opt: Option<&str> = None;
match opt {
Some(something) => {
println!("{}", something);
},
None => {
println!("opt is nothing");
}
}
//
// 流式处理
// 组合算子 combinator: 简化 match 处理
//
// map()
// map_or() 可以为 None 指定默认值
// map_or_else()
//
// 接受一个函数f, 返回一个option, 这个函数f:
// - 参数为option包含的元素, 返回值为处理后的元素
//
//
// 要求处理的option中元素可以是不同类型
//
//
#[derive(Debug)] enum Food { Apple, Potato, Banana}
#[derive(Debug)] struct Peeled(Food);//削皮的食物
#[derive(Debug)] struct Chopped(Food);//切块的食物
#[derive(Debug)] struct Cooked(Food);// 烹煮的食物
fn process(food: Option<Food>) -> Option<Cooked> {
food.map(|foo| Peeled(foo))// 闭包参数是Food 类型, 这里是解开了 Option, 返回 Option<Peeled> 类型
.map(|Peeled(foo)| Chopped(foo)) // 参数是 Peeled 类型, 这里解开了Option, Peeled
.map(|Chopped(foo)| Cooked(foo))
}
match process(Some(Food::Apple)) {
Some(cooked) => println!("cooked: {:?}", cooked),
_ => println!("error"),
}
//
// and_then()
//
//接受一个函数f作为参数, 返回option, 函数f满足:
//- 参数为 option 包含的元素, 返回为option
//
// 要求处理的option中元素是相同类型, 比如都属于某个枚举类
//
//
fn to_potato(food: Food) -> Option<Food> {
Some(Food::Potato)
}
fn to_banana(food: Food) -> Option<Food> {
Some(Food::Banana)
}
match to_potato(Food::Apple).and_then(to_banana) {
Some(banana) => println!("banana: {:?}", banana),
_ => println!("error"),
}
5.19.3. c 风格的枚举
//
// 拥有隐式辨别值(implicit discriminator,从 0 开始)的 enum
enum Number {
Zero,
One,
Two,
}
// c 风格枚举
// 拥有显式辨别值(explicit discriminator)的 enum
enum Color {
Red = 0xff0000,
Green = 0x00ff00,
Blue = 0x0000ff,
}
// `enum` 可以转成整形。
println!("zero is {}", Number::Zero as i32);//0
println!("one is {}", Number::One as i32);//1
println!("roses are #{:06x}", Color::Red as i32);//ff0000
println!("violets are #{:06x}", Color::Blue as i32);//0000ff
5.19.4. 案例 彩色命令行输出优化
use std::convert::From;
use std::str::FromStr;
use std::string::String;
use std::fmt;
#[derive(Clone, Copy, Debug, PartialEq, Eq)]
enum Color {
Red,
Yellow,
Blue,
}
impl Color {
pub fn to_fg_str(&self) -> &str {
match *self {
Color::Red => "31",
Color::Yellow => "33",
Color::Blue => "34",
}
}
pub fn to_bg_str(&self) -> &str {
match *self {
Color::Red => "41",
Color::Yellow => "43",
Color::Blue => "44",
}
}
}
impl<'a> From<&'a str> for Color {
fn from(src: &str) -> Self {
// parse 方法,要求目标类型必须实现 FromStr
src.parse().unwrap_or(Color::Red)
}
}
impl From<String> for Color {
fn from(src: String) -> Self {
src.parse().unwrap_or(Color::Red)
}
}
impl FromStr for Color {
type Err = ();
// from s仕 方法包含了 错误处理相关的代码
fn from_str(src: &str) -> Result<Self, Self::Err> {
let src = src.to_lowercase();
match src.as_ref() {
"red" => Ok(Color::Red),
"yellow" => Ok(Color::Yellow),
"blue" => Ok(Color::Blue),
_ => Err(()),
}
}
}
#[derive(Clone, Debug, PartialEq, Eq)]
struct ColoredString {
input: String,
fgcolor: Option<Color>,
bgcolor: Option<Color>,
}
impl ColoredString {
fn compute_style(&self) -> String {
let mut res = String::from("\x1B[");
let mut has_wrote = false;
if let Some(ref bgcolor) = self.bgcolor {
if has_wrote {
res.push(';');
}
res.push_str(bgcolor.to_bg_str());
has_wrote = true;
}
if let Some(ref fgcolor) = self.fgcolor {
if has_wrote {
res.push(';');
}
res.push_str(fgcolor.to_fg_str());
}
res.push('m');
res
}
}
impl Default for ColoredString {
fn default() -> Self {
ColoredString {
input: String::default(),
fgcolor: None,
bgcolor: None,
}
}
}
// impl<'a> From<&'a str> for ColoredString {
// fn from(s: &'a str) -> Self {
// ColoredString { input: String::from(s), ..ColoredString::default() }
// }
// }
trait Colorize {
fn red(self) -> ColoredString;
fn yellow(self) -> ColoredString;
fn blue(self) -> ColoredString;
// Color实现了 From,所以对于 String和&’a str类型的字符串均可通 过 into 方法转换为 Color
fn color<S: Into<Color>>(self, color: S) -> ColoredString;
fn on_red(self) -> ColoredString;
fn on_yellow(self) -> ColoredString;
fn on_blue(self) -> ColoredString;
fn on_color<S: Into<Color>>(self, color: S) -> ColoredString;
}
impl Colorize for ColoredString {
fn red(self) -> ColoredString {self.color(Color::Red)}
fn yellow(self) -> ColoredString {self.color(Color::Yellow)}
fn blue(self) -> ColoredString {self.color(Color::Blue)}
fn color<S: Into<Color>>(self, color: S) -> ColoredString {
ColoredString { fgcolor: Some(color.into()), ..self }
}
fn on_red(self) -> ColoredString {self.on_color(Color::Red)}
fn on_yellow(self) -> ColoredString {self.on_color(Color::Yellow)}
fn on_blue(self) -> ColoredString {self.on_color(Color::Blue)}
fn on_color<S: Into<Color>>(self, color: S) -> ColoredString {
ColoredString { bgcolor: Some(color.into()), ..self }
}
}
impl<'a> Colorize for &'a str {
fn red(self) -> ColoredString {self.color(Color::Red)}
fn yellow(self) -> ColoredString {self.color(Color::Yellow)}
fn blue(self) -> ColoredString {self.color(Color::Blue)}
fn color<S: Into<Color>>(self, color: S) -> ColoredString {
ColoredString {
fgcolor: Some(color.into()),
input: String::from(self),
..ColoredString::default()
}
}
fn on_red(self) -> ColoredString {self.on_color(Color::Red)}
fn on_yellow(self) -> ColoredString {self.on_color(Color::Yellow)}
fn on_blue(self) -> ColoredString {self.on_color(Color::Blue)}
fn on_color<S: Into<Color>>(self, color: S) -> ColoredString {
ColoredString {
bgcolor: Some(color.into()),
input: String::from(self),
..ColoredString::default()
}
}
}
impl fmt::Display for ColoredString {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
let mut input = &self.input.clone();
try!(f.write_str(&self.compute_style()));
try!(f.write_str(input));
try!(f.write_str("\x1B[0m"));
Ok(())
}
}
fn main() {
let red = "red".red();
println!("{}", red);
let yellow = "yellow".yellow().on_blue();
println!("{}", yellow);
let blue = "blue".blue();
println!("{}", blue);
let red = "red".color("red");
println!("{}", red);
let yellow = "yellow".on_color("yellow");
println!("{}", yellow);
}
5.19.5. 实例 创建链表
//
//
// enum 的一个常见用法就是创建链表(linked-list)
//
//
//
use List::*;
enum List {
// Cons:元组结构体,包含链表的一个元素和一个指向下一节点的指针
Cons(u32, Box<List>),
// Nil:末结点,表明链表结束
Nil,
}
// 可以为 enum 定义方法
impl List {
// 创建一个空的 List 实例
fn new() -> List {
Nil
}
// 处理一个 List,在其头部插入新元素,并返回该 List
// self 不加 &
fn prepend(self, elem: u32) -> List {
// `Cons` 同样为 List 类型
Cons(elem, Box::new(self))
}
// 返回 List 的长度
fn len(&self) -> u32 {
// `self` 为 `&List` 类型,`*self` 为 `List` 类型,匹配一个具体的 `T`
// 类型要好过匹配引用 `&T`。
match *self {
// 不能得到 tail 的所有权,因为 `self` 是借用的;所以要使用引用
// 因此使用一个对 tail 的引用
Cons(_, ref tail) => 1 + tail.len(),
// (递归的)基准情形(base case):一个长度为 0 的空列表
Nil => 0
}
}
// 返回列表的字符串表示(该字符串是堆分配的)
fn stringify(&self) -> String {
match *self {
Cons(head, ref tail) => {
// `format!` 和 `print!` 类似,但返回的是一个堆分配的字符串,
format!("{}, {}", head, tail.stringify())
},
Nil => {
format!("Nil")
},
}
}
// // 创建一个空链表
// let mut list = List::new();
// // 追加一些元素
// list = list.prepend(1);
// list = list.prepend(2);
// list = list.prepend(3);
// // 显示链表的最后状态
// println!("linked list has length: {}", list.len());
// println!("{}", list.stringify());
}
5.20. match 模式匹配
5.20.1. 模式匹配简单使用
/// match 模式匹配
/// 类似 Java 中的 switch
///
/// 必须穷尽所有分支 (使用 _ 忽略某个情况), 每个分支返回同个类型
///
fn match_demo() {
println!("------------------------ match demo ------------------------");
// 可以对枚举类, 对整数、浮点数、字符和字符串切片引用(&str)类型的数据进行分支选择,
// match 返回的变量
let a = match "hello".len() {
5 => "len = 5",
0 => "len = 0",
_ => "unkonwn len",
};
println!("{}", a);
// 作为函数返回值
//
// 实现一个缓存, 保存第一次处理后的值
//
struct Cache<T> where T: Fn(i32) -> i32 { // 函数类型作为泛型, Fn 是一个 trait
calc: T,
value: Option<i32>,
}
impl<T: Fn(i32) -> i32> Cache<T>{
fn new(caculator: T) -> Self {
Cache {
caculator: caculator,
value: None,
}
}
fn value(&mut self, arg: i32) -> i32 {
// 外层 match 没有 return, 没有 分号
match self.value {
Some(v) => v, // 返回值只是返回给 match 表达式, 不是直接返回给了外层的函数, 若想直接返回给函数, 需要 return 关键字
None => {
println!("第一次, arg = {}", arg);
let v = (self.caculator)(arg);// 必须有括号
self.value = Some(v);// self 必须可变
v
}
}
}
}
let mut ca = Cache::new(|x| x+1);// 这里可以省略参数类型是因为类型信息定义在前面的泛型中了
println!("arg = 1, v = {}", ca.value(1));
println!("arg = 1, v = {}", ca.value(1));
// 和 if 合用的匹配
match value.log2() {
x if x.is_normal() => Some(x),
_ => None
}
5.20.2. if lef while let 语法糖
// if let 语法糖
//适用于只区分两种情况的 match 语句
// 语法:
// if let 匹配值 = 源变量 {
// 语句块
// }
//
//
enum Book {
Papery(u32),
Electronic(String)
}
let book = Book::Electronic(String::from("url"));
if let Book::Papery(index) = book {
println!("Papery {}", index);
} else {
println!("Not papery book");
}
// 类似的还有 while let 语法糖
while let Some(v) = xx_vec.pop() {
println!("{}", v);
}
}
5.21. 错误处理
https://www.v2ex.com/t/843118#reply6
5.21.1. 断言
// assert 系列宏在调试( Debug)和发布( Release)模式下均可用, 并且不能被禁用。 debug_assert系列宏只在调试模式下起作用
// 尽量使用 debug_assert 系列宏较小性能开销
// 底层实际也是使用 panic! 宏引发线程恐慌
// • assert!, 用于断言布尔表达式在运行时一定返回 true。
// • assert_eq!, 用于断 言两个表达式是否相等(使用 PartialEq)。
// • assert_ne!, 用于断言两个表达式是否不相等(使用 PartialEq)。
// • debug_assert!, 等价于 asse此!,只能用于调试模式。
// • debug assert_eq!, 等价于 asse此一eq!,只能用于调试模式。
// • debug_assert_ne!, 等价于 assert ne!,只能用于调试模式 。
// 均会引发线程恐慌, 同时输出错误信息
assert! (x,"x wasn’t true");
debug_assert!(a + b == 30,"a={), b = {}", a, b);
5.21.2. panic 和 Abort
// panic 为线程恐慌, 会造成应用程 序以非零退出码退出进程, 也就是发生崩溃
// Abort 为线程终止, 将进程 正常中止
//
/// RUST_BACKTRACE=1 cargo run 这种方式运行带有回溯, 碰到 panic!("xxx") 会显示 backtrace
///
/// 如果想使一个可恢复错误按不可恢复错误处理(类比java 中 将 exceptin 转为 runtime exception),Result 类提供了两个办法:unwrap() 和 expect(message: &str)
//
///
/// https://rust-cli.github.io/book/tutorial/errors.html
///
fn error_handling() {
// 使用 panic!() 宏: 对于不可恢复错误使用 panic! 宏来处理
//
let f = File::open("hello.txt");
match f {
Ok(file) => {
println!("File opened successfully.");
},
Err(err) => {
println!("Failed to open the file.");
panic!("{:?}", err);
}
}
//
// if let 语法糖
let f = File::open("hello.txt");
if let Ok(file) = f {
println!("File opened successfully.");
} else {
println!("Failed to open the file.");
panic!("error"); // panic 会中断程序, 若不希望中断程序, 不要 panic
}
// 简化写法: 直接解包装, 可恢复异常也会 panic
//
//不会为函数产生返回值, 而是直接 panic
//
let f1 = File::open("hello.txt").unwrap(); //原理: 在 Result 为 Err 时调用 panic! 宏
let f2 = File::open("hello.txt").expect("Failed to open.");//expect 能够向 panic! 宏发送一段指定的错误信息
// 自己控制是否 panic
unwrap_or_else(|e| { panic!("failed to execute process: {}", e)})
//
5.21.3. Result 和 问号操作符
/// 可恢复错误, 用 Result<T, E> 类来处理,,类比 java 中 的 exception
/// //在 Rust 标准库中可能产生异常的函数的返回值都是 Result 类型的
/// enum Result<T, E> {
/// Ok(T),
/// Err(E),
/// }
// 异常传递, 函数返回值
//
fn func(i: i32) -> Result<i32, bool> {
if i >= 0 { Ok(i) }
else { Err(false) }
}
fn g(i: i32) -> Result<i32, bool> {
let t = func(i);
return match t { // 或者省略 return 和分号
Ok(i) => Ok(i), // 原样传给 match, match作为最终结构传给函数返回值
Err(b) => Err(b)
};
}
// 更好的写法:
//? 符的实际作用是将 Result 类非异常的值直接取出,如果有异常就将异常 Result 返回出去。所以,? 符仅用于返回值类型为 Result<T, E> 的函数
//?号 是 “要么 unwrap 要么 return Err(From::from(err))”。
//
// 会为函数产生返回值
//
fn g1(i: i32) -> Result<i32, bool> {
let t = func(i)?;
Ok(t) // 因为确定 t 不是 Err, t 在这里已经是 i32 类型
}
let r = g1(10000);
if let Ok(v) = r {println!("ok, r = {}", v)}
else { println!("Err")}
// 获取 error 类型, 处理异常
fn read_text_from_file(path: &str) -> Result<String, io::Error> {
let mut f = File::open(path)?;
let mut s = String::new();
f.read_to_string(&mut s)?;
Ok(s)
}
let str_file = read_text_from_file("hello.txt");
match str_file {
Ok(s) => println!("{}", s),
Err(e) => {
match e.kind() {
io::ErrorKind::NotFound => {
println!("No such file");
},
_ => {
println!("Cannot read the file");
}
}
}
}
// Result 的 map, and_then
//
// 类似 option, result也有自己的链式处理方法
//
use std::num::ParseIntError;
fn multiply(first_number_str: &str, second_number_str: &str) -> Result<i32, ParseIntError> {
// parse() 返回的是 result 类型
first_number_str.parse::<i32>().and_then(|first_number| {
second_number_str.parse::<i32>().map(|second_number| first_number * second_number)
})
}
// 更推荐的写法
//
// 推荐给 太长的类型起个别名
type AliasedResult<T> = Result<T, ParseIntError>;
fn multiply1(first_number_str: &str, second_number_str: &str) -> AliasedResult<i32> {
let first_number = first_number_str.parse::<i32>()?;
let second_number = second_number_str.parse::<i32>()?;
Ok(first_number * second_number)
}
//
5.21.4. 错误装箱 自定义异常
//
//
//
//装箱可以保存原始错误信息, 坏处就是,被包装的错误类型只能在运行时了解,而不能被静态地 判别。
//
//对任何实现了 Error trait 的类型,标准库的 Box 通过 From 为它们提供了 到 Box<Error> 的转换, 只要调用 XxxError.into() 即装箱
//
use std::error;
use std::fmt;
// 为 `Box<error::Error>` 取别名。
type Result<T> = std::result::Result<T, Box<error::Error>>;
// 自定义异常 /////////////////////////////
// 还必须同时实现 Debug 和 Display
#[derive(Debug, Clone)]
struct EmptyVec;
impl fmt::Display for EmptyVec {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "invalid first item to double")
}
}
impl error::Error for EmptyVec {
fn description(&self) -> &str {
"invalid first item to double"
}
fn cause(&self) -> Option<&error::Error> {
// 泛型错误。没有记录其内部原因。
None
}
}
// 将第一个数字乘以2
fn double_first(vec: Vec<&str>) -> Result<i32> {
vec.first()
.ok_or_else(|| EmptyVec.into()) // 装箱
.and_then(|s| {
s.parse::<i32>()
.map_err(|e| e.into()) // 装箱
.map(|i| 2 * i)
})
}
// 更好的写法: 使用 ? 号
// ?号 是 “要么 unwrap 要么 return Err(From::from(err))”。From::from 是 不同类型间的转换工具,
fn double_first(vec: Vec<&str>) -> Result<i32> {
let first = vec.first().ok_or(EmptyVec)?;
let parsed = first.parse::<i32>()?;
Ok(2 * parsed)
}
}
5.21.5. 捕获异常
// 恐慌安全: 发生 panic后, 代码终止执行, 后续的资源回收相关的代码不会执行, 可能引发问题, 防止这样的问题就是保证恐慌安全
// rust 通过 raii机制, 保证了基本的恐慌安全, 即使在 safe rust 中发生 panic, 也能保证资源回收
// 但是若 panic 发生在 unsafe rust 里面, 就无法保证恐慌安全了
// catch_unwind 方法来让开发者捕获恐慌,恢复当前线程。
//
// 接收的是一个正常的闭包,在该闭包中 并未发生恐慌,所 以正常执行
let result = panic::catch_unwind(|| { println!("hello!"); });
assert!(result.is_ok());
// 捕获此恐慌,并恢复当前线程
let result = panic::catch_unwind(|| { panic!("oh no!"); });// 输 出 结果 中打印 了恐慌信息,但是并没有影 响 到后续代码 的执行
assert!(result.is_err());
println!("{}", sum(1, 2));
// 使用 set_hook 自定义panic 消息消息
// set_hook 是全局性设置, 并不是只针对单个代码模块的, 可以和 take_hook 配合使用
//
panic::set_hook(Box::new(|panic_info| {
if let Some(location) = panic_info.location() {
println!("panic occurred '{}' at {}",
location.file(), location.line()
);
} else {
println!("can't get location information...");
}
}));
let result = panic::catch_unwind(|| { panic!("oh no!"); });
assert!(result.is_err());
5.21.6. 错误处理进化过程
//
// 直接解除包装
//
// 读取文件内容, 一步到位
let content = std::fs::read_to_string(&args.path).unwrap();
// panic
let content = match std::fs::read_to_string(&args.path) {
Ok(content) => content,
Err(err) => panic!(">>> Error occurred: {}", err),
};
// 返回 error
// 需要 main 返回 Result<(), Box<dyn std::error::Error>>
let content = match std::fs::read_to_string(&args.path) {
Ok(content) => content,
Err(error) => {return Err(error.into())},
};
// 使用问号
main() -> Result<(), Box<dyn std::error::Error>> {
let content = std::fs::read_to_string(&args.path)?;
}
// 添加错误上下文, 自定义异常
main -> Result<(),SomeErr> {
let content = std::fs::read_to_string(&args.path)
.map_err(|err| SomeErr(format!("Error of reading {}: {}", &args.path, err)))?;
}
// 使用第三方库
use failure::ResultExt;
use exitfailure::ExitFailure;
let ref path: PathBuf = args.path;
let content = std::fs::read_to_string(path)
.with_context(|_| format!("could not read file {}", path.to_str().unwrap()))?;
5.21.7. 第三方库处理异常
anyhow + thiserror
https://github.com/rust-cli/human-panic
5.22. io
5.22.1. 命令行参数
fn io_demo() {
//
let args = std::env::args();
println!("args: {:?}", args);//Args { inner: ["target/debug/hello", "main.rs"] }
for item in args {
println!("arg: {}", item);
}
//arg: target/debug/hello
//arg: main.rs
args.next().unwrap();
let arg0 = args.next().unwrap();// 命令本身, 拿到参数要两个 args.next()
// 或者一步到位
let pattern = std::env::args().nth(1).expect("no pattern given");
// 或者通过 vector 收集
let args: Vec<String> = env::args().collect();
//
//
//命令行输入文本
//
let secret_number = rand::thread_rng().gen_range(1, 101);
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {}", guess);
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
5.22.2. 文件 io
//
// ////////////////////////// 文件 io //////////////
//
use std::fs;
use std::io::prelude::*; //涉及到 write 需要 万能导入 prelude
// 创建写入文件
//
//静态方法,以 可写 模式打开文件。
//如果文件存在则清空旧内容
//如果文件不存在则新建 类似 echo "xxxx" > path
let mut file = fs::File::create("./cc.md").expect("create file error");
file.write_all("hello ".as_bytes()).expect("write error");
file.write_all(" world".as_bytes()).expect("write error");
file.write_all("\n你好".as_bytes()).expect("write error");
// 读取文件
//
// 一次性读取
//
//
// 静态方法
let text = std::fs::read_to_string("./Cargo.toml").unwrap(); // 相对路径是相对于根目录
println!("{}", text);
//
// or
let mut file = fs::File::open("./cc.md").expect("open error");// 只读模式打开, 相当于 cat <path>
let mut str_buf = String::new();
// 实例方法
file.read_to_string(&mut str_buf).expect("read error");
println!("{}", str_buf);
// 修改
// append() 用于将文件的打开模式设置为 追加模式
//
//此外还有 .read(true).write(true)
// 比如 OpenOptions::new().create(true).write(true).open(path) 可创建, 可写模式打开 , 相当于 touch xxx , 有则不动, 无则创建
//
let mut file = fs::OpenOptions::new().append(true).open("./cc.md").unwrap();
file.write_all("\nappend something...".as_bytes()).unwrap();
let updated_content = fs::read_to_string("./cc.md").unwrap();
println!("{}", updated_content);
// 读写二进制文件
// 文件流读取, 多次读取
//
// or
// 二进制 使用 std::fs::read("") 读取 u8 类型集合
//
// 复制文件的 demo:
//
let mut buffer = [0u8; 5];
let mut file = fs::File::open("cc.md").unwrap();
println!("文件打开成功:{:?}",file);//File { fd: 3, path: ".../data.txt", read: true, write: false }
file.read(&mut buffer).unwrap();
println!("{:?}", buffer);
file.read(&mut buffer).unwrap();
println!("{:?}", buffer);
// 删除
fs::remove_file("cc.md").unwrap();
// 其他文件系统操作
//
//
// 创建 目录, 返回 io::Result<()>
fs::create_dir("a")
//
// 递归创建,目录
fs::create_dir_all("a/c/d")
// 创建符号链接
//
unix::fs::symlink("../b.txt", "a/c/b.txt")
//读取目录下的所有的内容,返回 `io::Result<Vec<Path>>`
//
match fs::read_dir("a") {
Err(why) => println!("! {:?}", why.kind()),
Ok(paths) => for path in paths {
println!("> {:?}", path.unwrap().path());
},
}
// 移除一个空目录,返回 `io::Result<()>`
fs::remove_dir("a/c/d")
println!("-----------------meta -------------------");
// metadata 元数据
//
// 遍历目录
let meta = fs::metadata("./src");
/*
Ok(Metadata {
file_type: FileType(FileType {
mode: 16895
}),
is_dir: true,
is_file: false,
permissions: Permissions(FilePermissions {
mode: 16895
}),
modified: Ok(SystemTime {
tv_sec: 1597127845,
tv_nsec: 217049100
}),
accessed: Ok(SystemTime {
tv_sec: 1597132516,
tv_nsec: 30962100
}),
created: Err(Custom {
kind: Other,
error: "creation time is not available for the filesystem"
})
})
*/
println!("meta = {:?}", meta);
println!("src is dir? {}", meta.unwrap().is_dir());//true
}
fn copy_file() {
let mut command_line: std::env::Args = std::env::args();
command_line.next().unwrap();
// 跳过程序名
// 原文件
let source = command_line.next().unwrap();
// 新文件
let destination = command_line.next().unwrap();
let mut file_in = std::fs::File::open(source).unwrap();
let mut file_out = std::fs::File::create(destination).unwrap();
let mut buffer = [0u8; 4096];
use std::io::Write;
loop {
let nbytes = file_in.read(&mut buffer).unwrap();
file_out.write(&buffer[..nbytes]).unwrap();
if nbytes < buffer.len() { break; }// 如果某次读取没有将 buf 读满, 则写完后退出循环
}
}
5.23. 面向对象 oop
5.23.1. 可见性
// rust 下所有元素都是默认私有的, 无法在外部使用, 通过 pub 声明为 公开, 才能在外部使用
//
// - pub, 可以对外 暴露 公共接口,隐藏内部实现细节 (可用于任何对象)
// - pub(crate),对整个 crate 可见 。
// - pub(in Path),其中 Path是模块路径(以 crate 开头), 表示只能在 Path 指定的模块中访问
// - pub(self), 等价于 pub(in self),表示只限当前模块可见/使用
// - pub(super), 等价于 pub(in super),表示在当前模块和父模块中可见
//
//
// 结构体中的字段, 需要单独使用 pub 关键字来 改变其 可见性
// 2015
pub mod outer_mod {
pub(self) fn outer_mod_fn() {}
pub mod inner_mod {
// use outer_mod::outer_mod_fn;
// 对外层模块 `outer_mod` 可见
pub(in outer_mod) fn outer_mod_visible_fn() {}
// 对整个crate可见
pub(crate) fn crate_visible_fn() {}
// `outer_mod` 内部可见
pub(super) fn super_mod_visible_fn() {
// 访问同一模块的函数
inner_mod_visible_fn();
// 访问父模块的函数需要使用“::”前缀
::outer_mod::outer_mod_fn();
}
// 仅在`inner_mod`可见
pub(self) fn inner_mod_visible_fn() {}
}
pub fn foo() {
inner_mod::outer_mod_visible_fn();
inner_mod::crate_visible_fn();
inner_mod::super_mod_visible_fn();
// 不能使用inner_mod 的私有函数
// inner_mod::inner_mod_visible_fn();
}
}
fn bar() {
// 该函数对整个crate可见
outer_mod::inner_mod::crate_visible_fn();
// 该函数只对outer_mod可见
// outer_mod::inner_mod::super_mod_visible_fn();
// 该函数只对outer_mod可见
// outer_mod::inner_mod::outer_mod_visible_fn();
// 通过foo函数调用内部细节
outer_mod::foo();
}
fn main() { bar() }
// 2018
pub mod outer_mod {
pub(self) fn outer_mod_fn() {}
pub mod inner_mod {
// 在Rust 2018 edtion 模块系统必须使用use导入
use crate::outer_mod::outer_mod_fn;
// 对外层模块 `outer_mod` 可见
pub(in crate::outer_mod) fn outer_mod_visible_fn() {}
// 对整个crate可见
pub(crate) fn crate_visible_fn() {}
// `outer_mod` 内部可见
pub(super) fn super_mod_visible_fn() {
// 访问同一模块的函数
inner_mod_visible_fn();
// 使用use导入了outer_mod
outer_mod_fn();
}
// 仅在`inner_mod`可见
pub(self) fn inner_mod_visible_fn() {}
}
pub fn foo() {
inner_mod::outer_mod_visible_fn();
inner_mod::crate_visible_fn();
inner_mod::super_mod_visible_fn();
// 不能使用inner_mod 的私有函数
// inner_mod::inner_mod_visible_fn();
}
}
fn bar() {
// 该函数对整个crate可见
outer_mod::inner_mod::crate_visible_fn();
// 该函数只对outer_mod可见
// outer_mod::inner_mod::super_mod_visible_fn();
// 该函数只对outer_mod可见
// outer_mod::inner_mod::outer_mod_visible_fn();
// 通过foo函数调用内部细节
outer_mod::foo();
}
fn main() { bar() }
5.23.2. 多态
fn oop_demo() {
// 多态
//
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,// Box<dyn Draw> 为任何实现了 Draw trait 的类型的替身
}
// 另外多态例子
//
struct Rectangle {
width : u32,
height : u32,
}
struct Circle {
x : u32,
y : u32,
radius : u32,
}
trait IShape {
fn area(&self) -> f32;
fn to_string(&self) -> String;
}
impl IShape for Rectangle {
fn area(&self) -> f32 { (self.height * self.width) as f32 }
fn to_string(&self) ->String {
format!("Rectangle -> width={} height={} area={}",
self.width, self.height, self.area())
}
}
use std::f64::consts::PI;
impl IShape for Circle {
fn area(&self) -> f32 { (self.radius * self.radius) as f32 * PI as f32}
fn to_string(&self) -> String {
format!("Circle -> x={}, y={}, area={}",
self.x, self.y, self.area())
}
}
// 使用
use std::vec::Vec;
let rect = Box::new( Rectangle { width: 4, height: 6});
let circle = Box::new( Circle { x: 0, y:0, radius: 5});
let mut v : Vec<Box> = Vec::new();
v.push(rect);
v.push(circle);
for i in v.iter() {
println!("area={}", i.area() );
println!("{}", i.to_string() );
}
5.23.3. 向下转型
//向下转型
//
//
//先得让 IShape 继承于 Any ,并增加一个 as_any() 的转型接口
use std::any::Any;
trait IShape : Any + 'static {
fn as_any(&self) -> &dyn Any;
…… …… ……
}
//然后,在具体类中实现这个接口
impl IShape for Rectangle {
fn as_any(&self) -> &dyn Any { self }
…… …… ……
}
impl IShape for Circle {
fn as_any(&self) -> &dyn Any { self }
…… …… ……
}
let mut v : Vec<Box<dyn IShape>> = Vec::new();
v.push(rect);
v.push(circle);
for i in v.iter() {
if let Some(s) = i.as_any().downcast_ref::<Rectangle>() {
println!("downcast - Rectangle w={}, h={}", s.width, s.height);
}else if let Some(s) = i.as_any().downcast_ref::<Circle>() {
println!("downcast - Circle x={}, y={}, r={}", s.x, s.y, s.radius);
}else{
println!("invaild type");
}
}
}
5.23.4. 各种self区分使用
&self 常用, 表示当前对象的引用, 不可变, 无法修改
&mut self 常用, 表示当前对象的引用, 可变
self 不常用, 表示当前对象本身, 操作完成后, 当前对象无法再使用,会被丢弃回收 (场景: 析构函数)
mut self 不常用 ..... 操作完成被丢弃
5.23.5. 设计模式
5.23.5.1. 建造者模式
// std::process::Command 就使用了 建造者模式
struct Circle {
x: f64,
y: f64,
radius: f64,
}
struct CircleBuilder {
x: f64,
y: f64,
radius: f64,
}
impl Circle {
fn area(&self) -> f64 {
std::f64::consts::PI * (self.radius * self.radius)
}
fn new() -> CircleBuilder {
CircleBuilder {
x: 0.0, y: 0.0, radius: 1.0,
}
}
}
impl CircleBuilder {
fn x(&mut self, coordinate: f64) -> &mut CircleBuilder {
self.x = coordinate;
self
}
fn y(&mut self, coordinate: f64) -> &mut CircleBuilder {
self.y = coordinate;
self
}
fn radius(&mut self, radius: f64) -> &mut CircleBuilder {
self.radius = radius;
self
}
fn build(&self) -> Circle {
Circle {
x: self.x, y: self.y, radius: self.radius,
}
}
}
5.23.5.2. 访问者模式
// 用于将数据结构和作用于结构上的操作解祸。
// 访问者模式一般包含两个层 次:
// - 定义需要操作的元素。
// - 定义相关的操作. 一般将操作封装到一个 trait 中, 针对不同的元素, 有不同的方法实现
// Serde的架构是访问者模式
use std::any::Any;
trait HouseElement {
fn accept(&self, visitor: &HouseElementVisitor);
fn as_any(&self) -> &Any;
}
trait HouseElementVisitor {
fn visit(&self, element: &HouseElement);
}
struct House {
components: Vec<Box<HouseElement>>,
}
impl House {
fn new() -> Self {
House {
components: vec![Box::new(Livingroom::new())],
}
}
}
impl HouseElement for House {
fn accept(&self, visitor: &HouseElementVisitor) {
for component in self.components.iter() {
component.accept(visitor);
}
visitor.visit(self);
}
fn as_any(&self) -> &Any { self }
}
struct Livingroom;
impl Livingroom {
fn new() -> Self { Livingroom }
}
impl HouseElement for Livingroom {
fn accept(&self, visitor: &HouseElementVisitor) {
visitor.visit(self);
}
fn as_any(&self) -> &Any { self }
}
struct HouseElementListVisitor;
impl HouseElementListVisitor {
fn new() -> Self { HouseElementListVisitor }
}
impl HouseElementVisitor for HouseElementListVisitor {
fn visit(&self, element: &HouseElement) {
match element.as_any() {
house if house.is::<House>() => println!("Visiting the house..."),
living if living.is::<Livingroom>() => println!("Visiting the Living room..."),
_ => {}
}
}
}
struct HouseElementDemolishVisitor;
impl HouseElementDemolishVisitor {
pub fn new() -> Self {
HouseElementDemolishVisitor
}
}
impl HouseElementVisitor for HouseElementDemolishVisitor {
fn visit(&self, element: &HouseElement) {
match element.as_any() {
house if house.is::<House>() => println!("Annihilating the house...!!!"),
living if living.is::<Livingroom>() => println!("Bombing the Living room...!!!"),
_ => {}
}
}
}
fn main() {
let house = House::new();
// simply print out the house elements
house.accept(&HouseElementListVisitor::new());
println!();
// do something with the elements of a house
house.accept(&HouseElementDemolishVisitor::new());
}
5.23.5.3. raii模式
重构后的代码:
/*
利用Rust的ownership(linear/affine type)来设计接口
Refact
1. 去掉letter的Clone,使用所有权保证其唯一性;并且信封的wrap方法只接受获得所有权的信封,而非引用
2. 使用类型系统来保证信封的唯一性
3. 使用RAII机制来管理收尾逻辑,比如实现Drop
其他示例:
1. http response
2. steaming engine
*/
// #[derive(Clone)]
pub struct Letter {
text: String,
}
pub struct EmptyEnvelope {}
pub struct ClosedEnvelope {
letter: Letter,
}
pub struct PickupLorryHandle {
done: bool,
}
impl Letter {
pub fn new(text: String) -> Self {
Letter {text: text}
}
}
impl EmptyEnvelope {
pub fn wrap(self, letter: Letter) -> ClosedEnvelope {
ClosedEnvelope {letter: letter}
}
}
pub fn buy_prestamped_envelope() -> EmptyEnvelope {
EmptyEnvelope {}
}
impl PickupLorryHandle {
pub fn pickup(&mut self, envelope: ClosedEnvelope) {
/*give letter*/
}
pub fn done(self) {}
}
impl Drop for PickupLorryHandle {
fn drop(&mut self) {
println!("sent");
}
}
pub fn order_pickup() -> PickupLorryHandle {
PickupLorryHandle {done: false , /* other handles */}
}
fn main(){
let letter = Letter::new(String::from("Dear RustFest"));
let envelope = buy_prestamped_envelope();
let closed_envelope = envelope.wrap(letter);
let mut lorry = order_pickup();
lorry.pickup(closed_envelope);
}
有问题的代码:
/*
利用Rust的ownership(linear/affine type)来设计接口
存在的问题:
1. Letter有可能复制多份到多个信封(envelope)里,不安全
2. 信封里有可能有信,也有可能没有信, 可能寄出的是空信封;或者同一个信封装多次不同的信件, 造成信件的覆盖,不安全
3. 有没有把信交给邮车也是无法保证,不安全
*/
// 信纸
#[derive(Clone)]
pub struct Letter {
text: String,
}
// 信封
pub struct Envelope {
letter: Option<Letter>,
}
// 信件处理器
pub struct PickupLorryHandle {
done: bool,//是否寄出
}
impl Letter {
pub fn new(text: String) -> Self {
Letter {text: text}
}
}
impl Envelope {
// 装信纸进去
pub fn wrap(&mut self, letter: &Letter){
self.letter = Some(letter.clone());
}
}
// 创建空的信封
pub fn buy_prestamped_envelope() -> Envelope {
Envelope {letter: None}
}
impl PickupLorryHandle {
// 装车
pub fn pickup(&mut self, envelope: &Envelope) {
/*give letter*/
}
// 寄出
pub fn done(&mut self) {
self.done = true;
println!("sent");
}
}
// 创建处理器
pub fn order_pickup() -> PickupLorryHandle {
PickupLorryHandle {done: false , /* other handles */}
}
fn main(){
let letter = Letter::new(String::from("Dear RustFest"));
let mut envelope = buy_prestamped_envelope();
envelope.wrap(&letter);
let mut lorry = order_pickup();
lorry.pickup(&envelope);
lorry.done();
}
pub fn builder_pattern(){
unimplemented!();
}
5.24. 子进程
/// 子进程
///
/// process::Output 结构体表示已结束的子进程(child process)的输出,而 process::Command 结构体是一个进程创建者
///
/// std::Child 结构体代表了一个正在运行的子进程,它暴露了 stdin(标准 输入),stdout(标准输出) 和 stderr(标准错误) 句柄,
/// 从而可以通过管道与 所代表的进程交互
///
fn sub_process_command() {
println!("-------------sub_process_command--------------");
use std::process::Command;
let output = Command::new("rustc")
.arg("--version")
.output().unwrap_or_else(|e| {
panic!("failed to execute process: {}", e)
});
if output.status.success() {
let s = String::from_utf8_lossy(&output.stdout);
print!("rustc succeeded and stdout was:\n{}", s);
} else {
let s = String::from_utf8_lossy(&output.stderr);
print!("rustc failed and stderr was:\n{}", s);
}
// 管道
//
//
use std::error::Error;
use std::io::prelude::*; // 隐藏导入 万能导入
use std::process::{Stdio};
static PANGRAM: &'static str = "the quick brown fox jumped over the lazy dog\n";
// 启动 `wc` 命令
let process = match Command::new("wc")
.stdin(Stdio::piped())
.stdout(Stdio::piped())
.spawn() {
Err(why) => panic!("couldn't spawn wc: {}", why.description()),
Ok(process) => process,
};
// 将字符串写入 `wc` 的 `stdin`。
//
// `stdin` 拥有 `Option<ChildStdin>` 类型,不过我们已经知道这个实例不为空值,
// 因而可以直接 `unwrap 它。
match process.stdin.unwrap().write_all(PANGRAM.as_bytes()) {
Err(why) => panic!("couldn't write to wc stdin: {}", why.description()),
Ok(_) => println!("sent pangram to wc"),
}
// 因为 `stdin` 在上面调用后就不再存活,所以它被 `drop` 了,管道也被关闭。
//
// 若管道不关闭, `wc` 就不会开始处理我们刚刚发送的输入。
let mut s = String::new();
match process.stdout.unwrap().read_to_string(&mut s) {
Err(why) => panic!("couldn't read wc stdout: {}",
why.description()),
Ok(_) => print!("wc responded with:\n{}", s),
}
// 等待
//
//如果你想等待一个 process::Child 完成,就必须调用 Child::wait,这会返回 一个 process::ExitStatus。
//
let mut child = Command::new("sleep").arg("5").spawn().unwrap();
let _result = child.wait().unwrap(); // 必须调用 wait() 等待
println!("reached end of main");
}
5.25. 反射
// 标准库提供了 std::any::Any 来支持运行时反射。
// 可以接收任何静态生命周期类型 即 'static 类型, 不能接收非静态生命周期的类型
let v1 = 0xc0ffee_u32;
let v2 = E::He;
let v3 = S { x: 0xde, y: 0xad, z: 0xbeef };
let v4 = "rust";
let mut a: &Any; // trait object
a = &v1;
// 判断是否属于某种类型
assert!(a.is::<u32>());
// 全局唯一类型标识符
// 等价 get_type_id()
// TypeId { t: 12849923012446332737 }
println!("{:?}", TypeId::of::<u32>());
a = &v2;
assert!(a.is::<E>());
// TypeId { t: 15527215023668350898 }
println!("{:?}", TypeId::of::<E>());
a = &v3;
assert!(a.is::<S>());
// TypeId { t: 17868507538031848664 }
println!("{:?}", TypeId::of::<S>());
a = &v4;
assert!(a.is::<&str>());
// TypeId { t: 1229646359891580772 }
println!("{:?}", TypeId::of::<&str>());
// 向下转型为具体类型
use std::any::Any;
#[derive(Debug)]
enum E { H, He, Li}
struct S { x: u8, y: u8, z: u16 }
// 参数除使用&Any外,也可以使用 Box<Any>
fn print_any(a: &Any) {
if let Some(v) = a.downcast_ref::<u32>() {
println!("u32 {:x}", v);
} else if let Some(v) = a.downcast_ref::<E>() {
println!("enum E {:?}", v);
} else if let Some(v) = a.downcast_ref::<S>() {
println!("struct S {:x} {:x} {:x}", v.x, v.y, v.z);
} else {
println!("else!");
}
}
fn main() {
print_any(& 0xc0ffee_u32);
print_any(& E::He);
print_any(& S{ x: 0xde, y: 0xad, z: 0xbeef });
print_any(& "rust");
print_any(& "hoge");
}
// 非静态生命周期的类型未实现Any, 无法被 Any 类型接收
use std::any::Any;
struct UnStatic<'a> { x: &'a i32 }
fn main() {
let a = 42;
let v = UnStatic { x: &a };
let mut any: &Any;
any = &v; // Compile Error!
}
//ok
// 因为 使用了 静态生命周期类型来创建 UnStatic, 使得 UnStatic 也变为 了静态生命周期类型
static ANSWER: i32 = 42;
fn main() {
let v = UnStatic { x: &ANSWER };
let mut a: &Any;
a = &v;
assert!(a.is::<UnStatic>());
}
5.26. 宏
5.26.1. 宏基本介绍
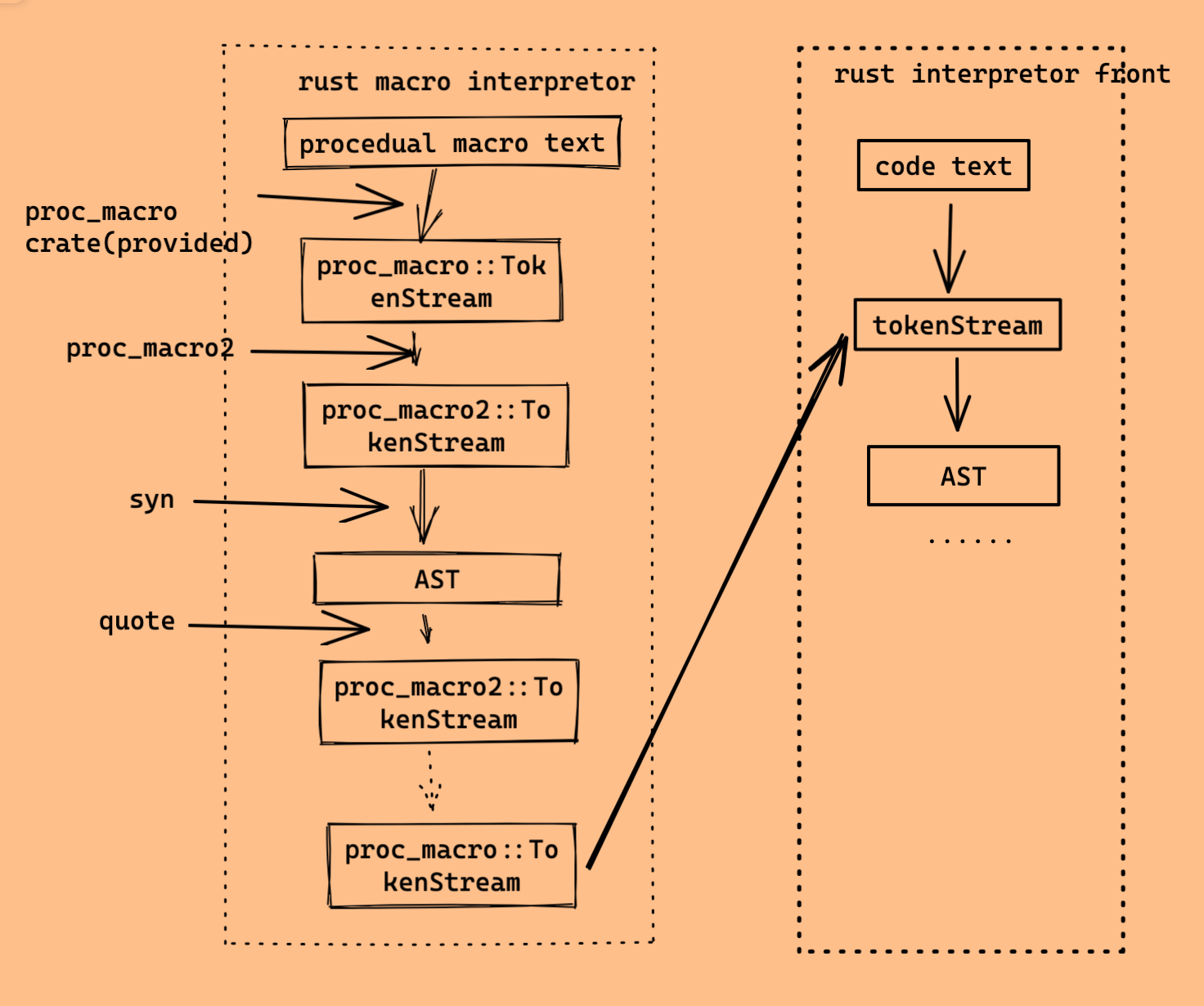
/// 可进行元编程(metaprogramming)
/// 宏并不产 生函数调用,而是展开成源码,并和程序的其余部分一起被编译
///
/// 使用场景:
/// - 避免重复代码 (https://doc.rust-lang.org/stable/rust-by-example/macros/dry.html)
/// - 领域专用语言(DSL,domain-specific language)。宏允许你为特定的目的创造特定的 语法
/// - 可变接口(variadic interface)。有时你需要能够接受不定数目参数的接口,比如 println!
///
按照定义方式分类:
- 声明宏, 通过 macro_rules! 定义 ( 输入代码, 通过 match 匹配, 以另外的代码替换输出)
- 过程宏 (接受 rust 代码作为输入, 在此基础上修改后, 输出;)
根据使用的语法形式又分为以下两种:
- 调用宏, 形如 println!、 assert_eq! 、 thread_local!等可以当作函数调用的宏,
- 属性宏, 也就是形如
#[derive(Debug))或#[cfg]这种形式的语法
按宏的来源,可以分为以下两类
- 内置宏
- 自定义宏
有哪些内置宏?
todo!()
print!()
println!()
eprintln!(" = {:?}", );
vec!
panic!
#[derive(Debug)] 调试打印 struct
#[allow(dead_code)] 用于屏蔽对未使用代码的警告
// 通过这个属性屏蔽警告。
#[allow(non_camel_case_types)]
#[cfg(test)] // 条件编译, 只在 测试时编译
5.26.2. 声明宏
5.26.2.1. 创建宏
// 宏展开:
// 假如是单独的文件则执行此命令展开
// rustc -Z unstable-options --pretty=expanded main.rs
// 假如是 cargo 生成的二进和l包则执行此命令
// cargo rustc -- -Z unstable-options --pretty=expanded
// macro rules!本身 也 是一种声明宏 , 只不过它由编译器 内部所定义
// 宏的原理和正则表达式匹配的原理类似
//
// 语法:
// macro_rule! $macro_name {
// // 扩展部分, 大小括号均可
// ($arg1:expr, $arg2:expr) => {code...}; // 分支以分号结尾
// () => () // 最后一个分支可省略分号
// }
// 未来会支持 macro 关键字
// #![feature(decl_macro)]
// macro unless($arg:expr, $branch:expr) {
// ( if !$arg { $branch });
// }
//
// 匹配表达式中类型支持: (各个类型能够匹配的范围有重叠覆盖)
// • item, 代表语言项,就是组成一个 Rust包的基本单位,比如模块、声明、函数定义 、 类型定义、结构体定义、 impl 实现等。
// • block, 代表代码块,由花括号限定的代码。
// • stmt,代表语句 , 一般是 指以分号结尾的代码 。
// • expr,指代表达式,会生成具体的值 。
// • pat,指代模式。
// • ty, 表示类型。
// • ident, 指代标识符。如 变量名或函数名
// • path,指代路径, 比如foo、 std::iter等。
// • meta, 元信息,表示包含在# [...]或#![...]属性 内的信 息。
// • tt , TokenTree 的 缩写,指代词条树。比 expr 能匹配的范围要广
// • vis,指代可见性,比如 pub。
// • lifetime, 指代生命周期参数 。
//
// 这是一个简单的宏,名为 `say_hello`。
macro_rules! say_hello {
// `()` 表示此宏不接受任何参数。
() => (// 这里使用 大括号亦可
// 此宏将会展开成这个代码块里面的内容。
println!("Hello cacro!");
)
}
// 这个调用将会展开成 `println("xxx");`!
say_hello!();// 这里使用大括号亦可
// 带参数
macro_rules! hello {
($name:expr) => {// 使用 大小括号均可
println!("Hello, {}", $name);
};
}
fn main() {
hello!("xy")// 使用大小括号均可
}
// 带代码段
macro_rules! unless {
($arg: expr, $logic:expr) => (
if !$arg {
$logic
}
);
}
fn main() {
let (a, b) = (1, 2);
unless!(a > b, {// 大括号可省略
println!("a < b");
});
}
// 参数类型为 标识符
macro_rules! create_function {
// `ident` 指示符, 标识 func_name 是变量名或函数名
($func_name:ident) => (
fn $func_name() {
// `stringify!` 宏把 `ident` 转换成字符串。
println!("You called {:?}()", stringify!($func_name))
}
)
}
// 借助上述宏来创建名为 `foo` 和 `bar` 的函数。
create_function!(foo);
create_function!(bar);
macro_rules! print_result {
// `expr` 指示符表示输入参数为一个表达式。
($expression:expr) => (
println!("{:?} = {:?}",
stringify!($expression),// `stringify!` 把表达式*原样*转换成一个字符串。
$expression)// 执行表达式
)
}
foo();
bar();
print_result!(1u32 + 1);
//代码块也是表达式!
print_result!({
let x = 1u32;
x * x + 2 * x - 1
});
5.26.2.2. 重复循环匹配
// 不定参数 可变接口
//宏在参数列表中可以使用 + 来表示一个参数可能出现一次或多次,
// 使用 * 来表示该 参数可能出现零次或多次
//
macro_rules! map {
($($key:expr => $value:expr),*) => {
// 包裹一层大括号, 表示返回一个值
{
// 使用绝对路径, 避免冲突
// 若使用到自定义函数, 需要在路径中使用 $crate , 避免导出时出 bug
let mut map = std::collections::HashMap::new();
// 循环读取
$(
map.insert($key, $value);
)*
map
}
};
}
fn main() {
// 调用时, 大小括号都可
let map = map!("a" => 1, "b" => 2, "c" => 3);
println!("map: {:?}", map);
let mat1 = map!{1 => "a", 2 => "b", 3 => "c"};
println!("mat1: {:?}", mat1);
//但还是存在问题, 末尾元素不能有逗号 , 可以通过添加多个匹配规则解决
// error
let map2 = map!("a" => 1, "b" => 2,);
}
// 解决:
macro_rules! map {
($($key:expr => $value:expr),*) => {
{
let mut map = std::collections::HashMap::new();
$(
map.insert($key, $value);
)*
map
}
};
// 新增一条匹配规则
($($key:expr => $value:expr,)*) => {
map!($($key => $value),*) // 递归调用前面的 匹配
};
}
// 或者最简单的方法, 将原来的匹配略加修改:
// 添加的 $(,)* 表示匹配任意次数的逗号
($($key:expr => $value:expr),* $(,)*) => {}
// or
($($key:expr => $value:expr,)* $(,)*) => {}
fn main() {
let map = map!(
1 => "a",
2 => "b", // 可以使用 逗号结尾了
);
println!("{:?}", map);
}
5.26.2.3. 实际案例
// 创建 map 宏
macro_rules! map {
// @unit 是约定俗成的在宏内部定义宏的命名规则
// 必须定义在开头, 否则就按照普通匹配分支处理了
(@unit $($x:tt)*) => {()}; // 统计 item 个数时使用的单位, 这里使用 空元组, 不占空间
(@count $($key:expr),* ) => {
(<[()]>::len(&[$(map!(@unit $key)),*]));
};
($($key:expr => $value:expr),* $(,)*) => (
{
let _cap = map!(@count $($key),*);
let mut _map = std::collections::HashMap::with_capacity(_cap);
$(
_map.insert($key, $value);
)*
_map
}
)
}
fn main() {
let map = map!(
1 => "a",
2 => "b",
);
println!("{:?}", map);
}
// 实例:
// `min!` 将求出任意数量的参数的最小值。
macro_rules! find_min {
// 基本情形:
($x:expr) => ($x);
// `$x` 后面跟着至少一个 `$y,`
($x:expr, $($y:expr),+) => (
// 对 `$x` 后面的 `$y` 们调用 `find_min!`
std::cmp::min($x, find_min!($($y),+))
)
}
println!("{}", find_min!(1u32));
println!("{}", find_min!(1u32 + 2 , 2u32));
println!("{}", find_min!(5u32, 2u32 * 3, 4u32));
// 创造 dsl
// 这里创造关键字 eval
//
macro_rules! calculate {
(eval $e:expr) => {
let val: usize = $e; // 强制类型为整型
println!("{} = {}", stringify!{$e}, val);
};
}
calculate! {
eval 1 + 2
}
calculate! {
eval (1 + 2) * (3 / 4)
}
// 升级版 dsl
// 可接受多个参数
//
macro_rules! calculate {
// 单个 `eval` 的模式
(eval $e:expr) => {{
{
let val: usize = $e; // Force types to be integers
println!("{} = {}", stringify!{$e}, val);
}
}};
// 递归地拆解多重的 `eval`
(eval $e:expr, $(eval $es:expr),+) => {{
calculate! { eval $e }
calculate! { $(eval $es),+ }
}};
}
calculate! {
eval 1 + 2,
eval 3 + 4,
eval (2 * 3) + 1
}
5.26.3. 宏调试
// 必须 nightly rust 才行
// #![feature(trace_macros) 标注宏定义, 然后在main 开头 trace_macros!(true);
#![feature(trace_macros)]
macro_rules! hashmap {
(@unit $($x:tt)*) => (());
(@count $($rest:expr),*) =>
(<[()]>::len(&[$(hashmap!(@unit $rest)),*]));
($($key:expr => $value:expr),* $(,)*) => {
{
let _cap = hashmap!(@count $($key),*);
let mut _map =
::std::collections::HashMap::with_capacity(_cap);
$(
_map.insert($key, $value);
)*
_map
}
};
}
fn main(){
trace_macros!(true);
let map = hashmap!{
"a" => 1,
"b" => 2,
"c" => 3,
};
assert_eq!(map["a"], 1);
}
5.26.4. 过程宏
5.26.4.1. 过程宏基本使用规则
// 可以用来:
// - 自定义派生属性, 类似于 #[derive(Debug)]这样的 derive 属性,可以自动为 结构体或枚举类型进行语法扩展, 增加新的方法实现
// - 自定义属性, 可以自定义类似于#[cfg()]这种属性
// - 类似函数调用的宏, 和 macro_rules!定义的宏类似,以 Bang 符号(就是叹号 "!" )结尾的宏 。可以像函数一样被调用 , custom!(...)。
# 过程宏,必须写在单独的lib类型的crate中, `cargo new --lib xxx`,
# 为什么不能在同一个 crate 里同时定义&使用 procedual macro ?
# procedual macro 是在项目编译前会被预先编译加工的一段程序, 如果定义和使用在同一个 crate, 就嵌入了死锁 (鸡生蛋蛋生鸡的问题)
# crate 代码要编译的话需要先处理 procedual macro展开, 而 处理 procedual macro 展开需要先编译
# 需要 为当前项目声明使用 proc_macro, proc_macro crate为 rust 自带, 默认不引入, 需要显式声明为 true
[lib]
# 设置为 proc_macro 类型
proc_macro = true
5.26.4.2. 自定义属性宏
Rust 自身有很多内置的属性 , 比如条件编译属性 #[cfgOJ和测试属性#[test]
过程宏实现自定义属性的功能还未稳定。在 该版本稳定之前,必须在 Nightly 版本下使用 #![feature(custom_attribute)]特性, 当前版本不需要了
定义宏:
use proc_macro::TokenStream;
#[proc_macro_attribute]
pub fn attr_with_args(args: TokenStream, _input: TokenStream) -> TokenStream {
// args 是 #[attr_with_args("Hello attr macro.")] 中的字符串
// _input 是输入, 即 fn boo() {}, 这里直接忽略了
format!("fn foo() -> &'static str {{{}}}", args.to_string()).parse().unwrap()
}
使用:
#[macro_use] extern crate proc_macro_me;
#[test]
fn tt() {
#[attr_with_args("Hello attr macro.")]
fn foo() {}
println!("{:?}", foo());//"Hello attr macro."
}
5.26.4.3. 函数调用宏
定义函数调用宏:
use proc_macro::TokenStream;
#[proc_macro]
pub fn make_fn_answer(_item: TokenStream) -> TokenStream {
"fn answer() -> u32 { 11 }".parse().unwrap()
}
使用:
#[macro_use] extern crate proc_macro_me;
#[test]
fn tt() {
make_fn_answer!();
println!("{:?}", answer());// 11
}
5.26.4.4. derive 宏
定义宏
// 自定义 derive 宏
//
// extern crate proc_macro;
// use proc_macro::TokenStream;
//or
// use self::proc_macro::TokenStream;
// or
use proc_macro::TokenStream;
// AnswerFn 相当于标识符, 使用时, 这样使用 #[derive(Hello, AnswerFn)]
#[proc_macro_derive(AnswerFn)]
pub fn derive_answer_fn(_input: TokenStream) -> TokenStream {
"fn answer() -> u32 { 11 }".parse().unwrap()
}
#[proc_macro_derive(Hello)]//表示其下方的函数专门处理自定义派生属性
pub fn derive_a_hello(input: TokenStream) -> TokenStream {
let input = input.to_string();
// 保证 代码中存在 struct A
assert!(input.contains("struct A"));
//方法最终会返回一个 Result<TokenSteam, Err〉类型,
// 所以还需要再次用 unwrap 方法才能返回。
r#"
impl A {
fn a(&self) -> String {
format!("hello from a impl")
}
}
"#.parse().unwrap()
}
使用:
// #[macro_use] extern crate proc_macro_me;
//or
use proc_macro_me::{AnswerFn, Hello};
#[derive(Hello, AnswerFn)]
pub struct A;
#[test]
fn test_derive_a() {
let aa = A;
assert_eq!("hello from a impl".to_string(), aa.a());
println!("{}", answer());
}
5.26.5. 使用第三方包
官方的过程宏库为proc_macro, 还没稳定,不推荐直接使用
derive_more
syn 完整实现了 Rust 源码 的语 法树结构
quote 可以将 syn 的语法树结构转为 proc macro::TokenStrem 类型
proc_macro2
proc-macro-workshop
seq-macro
paste
5.26.6. 编译器插件
cargo-expand
# install
cargo install cargo-expand
rustup component add rustfmt # this is used to format the expanded code
rustup install nightly # 在 Nightly 版本的 Rust 之下,配合, just need install nightly version, not have to switch to nightly
# 使用
cargo expand # this will expand all code
cargo expand <function name> # this will only expand the specified function
6. unsafe 屏蔽内存安全检查
6.1. unsafe 基本场景
// 使用 unsafe 定义 不安全的 函数/方法/trait, 以及为 trait 实现方法
//
// 如: String::from_utf8_unchecked 就是不安全的, 对于输入参数, 没有检查是否是有效的 utf-8字节序列; String::from_utf8_lossy 则是安全的
// 如: Send trait, Sync trait 都是 unsafe 的, 使 用 unsafe对 Send和 Sync进行标记,就意味着开发者手动实现它会有安全风险, 所以编译器会自动对我们自定义的类型实现这两个接口
// 如: Searcher trait, 没有检查截取的字符位置在字符串中是否是有效字符边界, 需要开发者自己保证
// 在 unsafe 块中执行不安全的操作 (对于不安全的操作, 会屏蔽内存安全检查, 但是对于安全的操作, 依然有安全检查)
//
/// - 解引用裸指针 (但是创建裸指针无需在 unsafe 中)
/// - 调用 unsafe 的函数/方法
/// - 访问修改可变静态变量
/// - 实现 unsafe 的 trait
// - 读写 union 联合体中的 字段
// 访问修改可变静态变量 (一般用不到, 只是用于和 c 交互)
//
//
// 静态变量是全局可访 问 的 。对于不可变静态变量来说,访问它不存在任何安全 问题
// 如果多个线程同时访 问可变静态变量, 会有安全问题, 所以要在 unsafe 中修改
static mut COUNTER: u32 = 0;
fn main() {
let inc = 3;
unsafe {
COUNTER += inc;
println!("COUNTER: {}", COUNTER);
}
}
// 访问 union 联合体 (只要还是为了方便 和 c 交互)
//
//
//
// 解引用裸/原生指针 (raw pointer), 裸指针常用于 和 c 交互
//
// 分为:
// 不可变裸指针 *const T
// 可变裸指针 *mut T
//
// - 允许忽略借用规则: 某个对象可以同时拥有可变不可变裸指针, 或者多个同时指向相同位置的可变裸指针
// - 不保证指向的内存是有效的, 允许指向空地址
// - 不保证线程安全
// - 没有自动清理的功能, 需要手动清理内存
//
let mut a = 1;
let rp1 = & a as *const i32; // 创建时无需在 unsafe
// 同时出现了 可变, 不可变借用, 编译器不报错
let rp2 = &mut a as *mut i32;
unsafe {
println!("rp1 = {}", *rp1);
println!("rp2 = {}", *rp2);
}
// 访问 unsafe 方法
//
//
unsafe fn danger() {
println!("dangerous");
}
unsafe {
danger();
}
//
6.2. 交叉编译
# 如果是针对 ARM 嵌入式开发平台, 不能使 用std标准库 (#![no_std))
rustc --target=arm-unknown-linux-gnueabihf hello .rs
cargo build --target=arm - unknown - linux - gnueabihf
# 第三方交叉编译工具 xargo
通过配置文件指定链接器: vim ~/ . cargo/config
[target . arm- unknown-linux-gnueabihf]
linker = ”arm-linux-gnueabihf-gcc-4.8”
6.3. ffi 外部函数接口
6.3.1. ffi 基本介绍
Java语言则将FFI称为JNI CJavaNativeInterface)
https://www.cnblogs.com/Jackeyzhe/p/12623689.html
https://rustcc.cn/article?id=3b8241d0-c4ca-4f49-8e07-0a5142b00f59
///外部语言函数接口
///
/// Rust 提供了到 C 语言库的外部语言函数接口(Foreign Function Interface,FFI)。
/// 外 部语言函数必须在一个 extern 代码块中声明,且该代码块要带有一个包含库名称 的 #[link] 属性
///
// 支持四种库:
// - dylib , rust动态库
// - rlib, rust 静态库
// - cdylib, 其他语言写的动态库
// - staticlib , 其他语言静态库
//
//
// 如何编译为库
//
// flag 参数
// (crate type 可以指定多个, #[crate_type = "bin"] 这种使用形式需要标注在 lib.rs or main.rs 开头)
//
// --crate-type=bin or #[crate_type = "bin"] 表示将生成-个可执行文件 。要求程序中必 须包含一个 main 函数
// --crate-type=lib or #[crate_type = "lib"] 表示将生成一个 Rust库。 具体生成什么类型库,由编译器自行决定。默认会产生 rlib静态 库
//--crate-type=rlib or #[crate_type = "rlib"] 静态 Rust库,由Rust编译器来使 用。
//--crate-type=dylib or #[crate_type = "dylib"] 动态 Rust库,由 Rust 编译器来使用(在 Linux上会创建*.so文件,在 MacOSX上会创建.dylib文件, 在 Windows上会创建.dll文件)
// --crate-type=staticlib or #[crate_type = "staticlib"] 生成静态系统库 。 Rust 编译器 永远不会链接该类型库,主要用于和 C 语言进行链接 ,达成和其他语 言交互 的目的 。 静态系统库在 Linux和 MacOSX上会创建.a文件,在 Windows上会创建*.lib文件
//--crate-type=cdylib or #[crate_type = "cdylib"] 生成动态系统库。同样 用 于生成 C 接口, 和其他语言交互。该类型在 Linux上会创建.so文件 ,在 MacOSX上会创建.dylib , 在 Windows上会创建.dll文件
6.3.2. 和 elixir 交互
rustler
6.3.3. 和c cpp 交互
Cbindgen
autocxx -> c++
6.3.3.1. 在 rust 中调用 C 函数
// 在 Rust 中调用 C 函数
//
// 这里指定使用 C-ABI,等价于 “extern fn foo () ”这样的函数声明; 此外还有 extern "Rust”, 这是默认的 ABI,任何普通 的函数都将使 用 该 ABI
extern "C" {//也可以 直接使用 extern 块,而省略掉ABI字符串°C” 。因为默认的extern块就是按C-ABI处理的
// 定义了 C 标准库内置的 isalnum 函数签名, 可以直接使用了
fn isalnum(input: i32) -> i32;
}
fn main() {
unsafe {
println!("Is 3 a number ? the answer is : {}", isalnum(3));
// error, 参数类型错误
println!("Is 'a' a number ? ", isalnum('a'));
}
}
6.3.3.2. 在 rust调用 cpp
// 调用 cpp c++
//
//
// 单精度复数的最简实现
#[repr(C)]
#[derive(Clone, Copy)]
struct Complex {
re: f32,
im: f32,
}
impl fmt::Debug for Complex {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
if self.im < 0. {
write!(f, "{}-{}i", self.re, -self.im)
} else {
write!(f, "{}+{}i", self.re, self.im)
}
}
}
// 这个 extern 代码块链接到 libm 库
#[link(name = "m")]
extern {
// 这个外部函数用于计算单精度复数的平方根
fn csqrtf(z: Complex) -> Complex;
// 这个用来计算单精度复数的复变余弦
fn ccosf(z: Complex) -> Complex;
}
// 由于调用其他语言的函数被认为是不安全的,我们通常会给它们写一层安全的封装
fn cos(z: Complex) -> Complex {
unsafe { ccosf(z) }
}
// z = -1 + 0i
let z = Complex { re: -1., im: 0. };
// 调用外部语言函数是不安全操作
let z_sqrt = unsafe { csqrtf(z) };
println!("the square root of {:?} is {:?}", z, z_sqrt);
// 调用不安全操作的安全的 API 封装
println!("cos({:?}) = {:?}", z, cos(z));
6.3.3.3. 在 c 中调用 rust
6.3.4. 和 Python 交互
https://github.com/PyO3/pyo3 https://saidvandeklundert.net/learn/2021-11-18-calling-rust-from-python-using-pyo3/ https://zhuanlan.zhihu.com/p/148144823
6.3.5. 和 Swift
cbingen
6.3.6. 和 js JavaScript nodejs 交互
neon -> 和 node 交互
https://github.com/napi-rs/napi-rs
https://rustwasm.github.io/ webassembly
6.3.7. 和 java 交互
https://github.com/jni-rs/jni-rs https://github.com/astonbitecode/j4rs
flapigen-rs, robusta
6.3.7.1. java 调用 rust
https://github.com/drrb/java-rust-example
https://github.com/jnr/jnr-ffi
https://github.com/drrb/java-rust-example https://stackoverflow.com/questions/30258427/calling-rust-from-java
https://blog.csdn.net/abcamus/article/details/81017325
https://rustcc.cn/article?id=98b96e69-7a5f-4bba-a38e-35bdd7a0a7dd 各种库区别
https://rustcc.cn/article?id=f371a5f1-08fa-4ab8-99a4-21d307223f82 rust 导出共享库
6.3.7.2. rust 调用 java
https://github.com/benanders/rjni
7. 内存管理
7.1. 堆 和 栈
手动管理内存 -> bug (内存泄漏, 垂悬指针)
gc -> 性能问题(stop the world, 因为GC 在工作的 时候必须保证程序不会引入新的“垃圾", 所以要使运行中的程序暂停)
虚拟内存管理技术: 对物理存储设备的抽象, 方便同时运行 多道程序 ,使得每个进程都有各自独立的进程地址空间
虚拟地址空间: (用户所接触到的地址都是虚拟地址,而不是真实 的物理地址)
是线性空间, 分为 用户空 间和内核空间 (它们的比例是 3:1 (Linux系统中)或 2:2 (Windows系统中))
32 位计算机Linux的地址空间大小是 4GB
好处:
用户程序可以使用比物理内存更大的地址空间
保护操作系统,让进程在各自的地址空间内操作内存
用户空间中的 栈 (stack), 堆 (heap)
栈 (堆栈): 用 于支持 CPU 入栈或出栈的指令操作, 如函数嵌套调用时需要存储方法栈帧
stack 内存中保存的数据,生命周期都比较短,会随着函数调用的完成而消亡,
对于基本原生数据类型来说, Rust 是默认将其分配到栈中的
结构体或枚举, 联合体只是定义,看它们被分配在哪 ,主要是看其类型实例如 何使用
堆: 一块巨大的内存空间, 长久地保存在内存中的数据,以便跨函数使用;程序不可以主动申请桔 内存,但可以主动申请堆内存
堆分配算法: 空闲链表 (Free List)和位图标记 (Bitmap)。
空闲链表实际上就是把堆中空闲的内存地址记录为链表 , 当系统收到程序申请时,会遍 历该链表:当找到适合的空间堆节点 时, 会将此节点从链表中删除;当空间被回收以后 , 再 将其加到空闲链表中。空闲链表的优势是实现简单,但如果链表遭到破坏 , 整个堆就无法正 常工作。
位图的核心思想是将整个堆划分为大量大小相等的块。 当程序申请内存时,总是分配整 数个块的空间。每块内存都用一个二进制位来表示其状态,如果该内存被占用 ,则相应位图 中的位置置为 1;如果该内存空闲,则相应位图中的位置置为 0。位图的优势是速度快,如 果单个内存块数据遭到破坏, 也不会影响整个堆,但缺点是容易产生内存碎片
内存释放: 分配的都是虚拟地址空 间 。 所以当堆空间被释放时,并不代表指物理 空 间也 马上被释放, 只是内存被归还给了内存分配器。 内存分配 器会对空闲的 内存进行统一 “整理”, 在适合( 比如空闲内存达到 2048KB)的时候,才会把 内存归还给系统 ,也就是指释放物理空 间
Rust 编译器目前自带两个默认分配 器: alloc_system 和 alloc_jemalloc, Rust 2018 版本 下, 默认使用 alloc_system, 可以自己指定
7.2. 内存对齐
内存对齐, 即字节对齐, 减少 cpu 读取内存次数
CPU在单位时间/一次计算能处理的位数 -> 字长, 32位CPU, 其字长为32位,也就是一次读取4个字节, 所以每次只能对 4 的 倍数的 地址 进行读取
现有一整数类型的数据,首地址并不是 4 的倍数,不妨设为 Ox3, 存储在 地址范围是 Ox3~Ox7 的存储空间, cpu 需要分别在 Ox1 和 Ox5 处进行两次读取, 采取内存对齐策略后, 数据的首地址变为 0x5, CPU只需要读取一次。
// 对应到代码层面:
struct A {
a: u8,// 1byte
b: u32,// 4byte
c: u16, // 2 byte
}
println!("{:?}", std :: mem::size o f : : < A > ( );// 8 , 单位 字节
// 分析:
// 总共是 7, 为什么打印 8 ?
// 因为存在内存对齐策略
//
// 内存对齐包括基本数据对齐和结构体(或联合体)数据对齐
// 对于基本数据类型,默认 对齐方式是按其大小进行对齐,也被称作自然对齐。 比如Rust中u32类型占4字节,则它默 认对齐方式为 4 字节对齐
7.3. 手动堆内存分配
在编写 Unsafe Rust的过程中,也需要手动进行堆内存分配,所以 Rust标准库 std::alloc 模块中也提供 了堆内存 分配的 相 关 API
// Rust 1.28之前默认全局内存分配器:jemalloc
// Rust 1.28内存分配器 : System,同时会提供其他全局分配器,可自定义
//
use std::alloc::{GlobalAlloc, System, Layout};
struct MyAllocator;// 可以直接使用GlobalAlloc, 这里是做了一个包装
unsafe impl GlobalAlloc for MyAllocator {
unsafe fn alloc(&self, layout: Layout) -> *mut u8 {
System.alloc(layout)
}
unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout) {
System.dealloc(ptr, layout)
}
}
// 声明为全局分配器
#[global_allocator]
static GLOBAL: MyAllocator = MyAllocator;
fn main() {
// 此处Vec的内存会由GLOBAL全局分配器来分配
let mut v = Vec::new();
v.push(1);
}
// 指定全局分配器为jemalloc
//
extern crate jemallocator;
use jemallacator::Jemalloc;
#[global_allocator]
static GLOBAL: Jemalloc = Jemalloc;
8. 工程管理 模块
8.1. 概念简单解释
https://www.jianshu.com/p/51693602114a https://zhuanlan.zhihu.com/p/73544030 or https://privaterookie.github.io/2019-07-14-Rust%E6%A8%A1%E5%9D%97%E4%B8%8E%E6%96%87%E4%BB%B6/
/// - 箱(Crate): 二进制程序文件or 库文件, 位于包中
///
/// - 包(Package): cargo new xxx 新建的 就是 包; 包必须由一个 Cargo.toml 文件来管理,该文件描述了包的基本信息以及依赖项。
///
/// 一个 package 最少有一个 crate
///
/// 当使用 cargo new 命令创建完包之后,src 目录下会生成一个 main.rs 源文件,Cargo 默认这个文件为二进制箱的根,编译之后的二进制箱将与包名相同。
///
/// - 模块(Module): 使用 mod 声明一个模块, 一个文件默认就是一个 module, 文件名就是 module name
//
// 每个包都拥有一个顶级 (top level) 模块 src/lib.rs 或 src/main.rs。
///
/// 每个 rust 文件都是一个 module, 比如:
// (若想在同个文件定义多个 module , 只需 mod xx_module {...} mod yy_module {...})
/// ```
/// // main.rs
/// mod second_module; // 声明一个模块
/// fn main() {
/// println!("This is the main module.");
/// println!("{}", second_module::message());
/// }
/// // second_module.rs, 模块名就是文件名
/// pub fn message() -> String {
/// String::from("This is the 2nd module.")
/// }
/// ```
//
// 若希望多个 文件, 组成一个 module,
// 需要:
// 合并到一个文件夹, 新建一个 mod.rs (2018 中可以省略了), 然后在其中导出即可 (pub use sub1; pub use sub2;), 新 module name = 文件夹名
//
// 若文件夹 和某个文件 aa.rs 同名, 则文件夹下定义的 module 都是 aa.rs 的子模块 (2015 中则不允许文件与目录同名)
//
//
fn mod_package_crate() {
// 路径:
// Rust 中的路径分隔符是 ::
//绝对路径从 crate 关键字开始描述。
// 相对路径从 self 或 super 关键字或一个标识符开始描述
// 如: 导入外部依赖
use super::{deserial, serial}; //导入 parent 指定资源
use super::*; // 导入 parent 的所有
use crate::codec::{serial, deserial}; // 绝对路径, codec 为依赖 (不论是自定义模块还是第三方依赖, 若为第三方模块, 则 crate 关键字可选), codec 也能是 同个项目的其他 module (rust 文件)
// 标准库 默认导入了, 所以以下两句可选
extern crate std; // 导入 标准库 std crate, 这是 2015 中的语法, 2018 中可选了, 只需要 cargo.toml 中导入即可, 无需再代码中显式指定
use std : :prelude: :vl: :* ; // 标准库的 prelude module
// 在 module 开头声明不需要 标准库, 使用 核心库(嵌入式开发必须)
#[no_std]
// govern 函数的绝对路径
crate::nation::government::govern();
// 相对路径
nation::government::govern();
//Rust 中有两种简单的访问权:公共(pub)和私有(模块成员默认都是私有)。
// 私有 模块中的元素都需要 pub 修饰才能在外部访问到 , 但是 枚举类的字段不受这个限制
//对于私有的模块,只有在与其平级的位置或下级的位置才能访问,不能从其外部访问。
mod nation {
pub mod government {
pub fn govern() {println!("govern()")}
}
mod congress {
pub fn legislate() {
println!("legislate()");
}
}
pub mod court {
pub fn judicial() {
print!("judicial - ");
super::congress::legislate();
}
}
// use 关键字可以与 pub 关键字配合使用:
pub use congress::legislate as le;
}
nation::government::govern();
nation::court::judicial();
// 导入 and 简化路径
use nation::court::judicial as ju;
// 现在可以直接使用
ju();
nation::le();
}
8.2. 可见性管理
pub use T 导出了 T,T 可以被其他 crate 使用;pub (crate) use T 只把 T 导出到当前的 crate,其他 crate 访问不了
8.3. 编译器版本管理
在项目根目录下, 放 rust-toolchain 文件, 指定编译器版本
8.4. 为项目单独指定config 配置
cargo 全局配置 : /.cargo/confg
当前用户全局配置: $HOME/.cargo/config
项目单独配置: $proj/.cargo/config (子模块亦可继续指定)
8.5. 依赖管理 cargo
8.5.1. cargo 基本命令
# 新建可执行程序, 默认是 --bin
# 生成 main.rs 启动类
cargo new [--bin] <proj>
# 不初始化 git
cargo new <proj> --vcs none
# 新建库, 在项目根目录下
# 生成 的库下, 有 src, toml, lib_name.rs (带有基本的测试)
cargo new --lib <lib name>
# 在当前文件夹下新建项目
cargo init [--bin]
cargo init --lib
# 构建, 更新依赖, 依赖在这里找 https://crates.io/
# 默认是以 debug 方式编译, 编译速度快, 但是生成的可执行文件未优化
# build 后会生成 Cargo.lock
# ./target/debug/project_name 中找到编译后的 可执行文件(exe) 运行
cargo build
# 使用 --release 参数编译最终发布版本。
# 编译器会对代码进行优化, 使得编译时间变慢, 但是代码运行速度会变快。
cargo build --release
# 指定条件编译属性 (可以在 Cargo.toml 中指定)
# 会给 rustc 传递 --cfg features="xxx", 表示 会编译 aa_module 模块, 不指定 xxx feature 则不会编译 该模块
cargo build --features "xxx"
# 在代码中这么使用
# # 表示若没有指定 xxx feature, 则编译报错
# #[cfg(not(feature = "xxx"))]
# compile_error!("xxx feature is required to build this crate")
#
# # 表示 只有指定 了 xxx feature, 编译时才会包含 aa_module 进去
# #[cfg(feature = "xxx")]
# mod aa_module
cargo check # 迅速检查错误, 时间短
cargo run
# 运行 example 文件夹下的 server.rs 的 main()
cargo run --example server
# 运行指定子模块
cargo run -p <xxx>
# 运行当前项目(rust_tools)下的 bin 文件夹下的 chat_server.rs 可执行文件
cargo run --package rust_tools --bin chat_server
# 从中心仓库安装
cargo install <package>
# 从 GitHub 安装
cargo install orz --git https://github.com/richox/orz --tag v1.6.1
cargo doc # 生成html文档
cargo doc --open # 同时打开文档预览
cargo doc --target-doc ./ #输出文档时指定target目录
# # 测试,
# 会跑 #cfg[test] 下的 #[test]; 也会跑文档注释 (单元测试)
# and tests/ 下的测试 (集成测试)
cargo test
cargo test xxx # 过滤, 运行任何名字中包含 xxx 的测试
cargo publish # publish a library to crates.io
cargo --version
# This will write out a new Cargo.lock with the new version information
cargo update # updates all dependencies
cargo update -p rand # updates just “rand”
# 第三方插件扩展:
# 需要 rustup component add rustfmt [一toolchain nightly]
cargo fmt # 格式化项目代码, 在项目根目录下执行, 会生成备份文件, .bk结尾, 跳过格式化 #[rustfmt_skip]
cargo fix # 自动修复代码警告
cargo clippy #捕捉常见错误,改善代码 (需要安装 clippy)
自定义格式化: 在项目根目录 rustfmt.tomI
max_width = 90 # 最大宽度
fn_call_width = 90 # 函数宽度
chain_one_line_max = 80 # 链式调用最大宽度
condense_wildcard_suffixes = true # 压缩通配符前缀
8.5.2. 文件布局结构
.
├── Cargo.lock
├── Cargo.toml
├── benches #性能测试
│ └── large-input.rs
├── examples # 示例
│ └── simple.rs
├── src # 源码
│ ├── bin # 其他可执行文件 (如果可执行文件包含不止一个源文件,则可以使用src/bin目录下,又一个包含main.rs文件的目录,而该目录将被视为具有父目录名称的可执行文件)
│ │ └── another_executable.rs
│ ├── lib.rs # 默认库文件
│ └── main.rs # 默认可执行文件
└── tests # 集成测试 , 单元测试一般就写在 src 下
└── some-integration-tests.rs
8.5.3. Cargo.toml
Cargo.toml 项目元信息, 包括版本, 依赖
[package]
...
build = "build.rs" # 构建脚本, 相对于根目录
workspace = ".." # 这是 sub crate 中的配置
member = ["", ""] # 这是 parent crate 中的配置
[[bin]]
name = "run-main" # 生成的可执行文件的名字
path = "src/main.rs" # 当想在一个作为库的包里同时包含 main.rs , 需要配置这个, 文件名必须为 main.rs, 若放在 src/bin 下则可以自定义文件名
bench = false # 生成 可执行文件时不执行性能测试
[[bench]]
name = "bench"
path = "src/bench.rs" # 性能测试代码
test = false
bench = true
# 依赖
# [dependencies] 专门用于设置第三方包的依赖,这些依赖会在执行 cargo build命令编译 时使用。
[dependencies]
uuid = "0.0.1" # 会从中心仓库下载
ferris-says = "0.1"
# 版本号规则
[dependencies]
gfx-hal = { version = "0.1.0", git = "https://github.com/gfx-rs/gfx", rev = "bd7f058efe78d7626a1cc6fbc0c1d3702fb6d2e7" }
# 或者写成多行 (使用点 "." 表示json 中的嵌套)
[dependencies.gfx-hal]
git = "https://github.com/gfx-rs/gfx"
version = "0.1.0"
rev = "bd7f058efe78d7626a1cc6fbc0c1d3702fb6d2e7"
# 本地项目导入
[dependencies]
hello_utils = { path = "../hello_utils", version = "0.1.0" }
# 默认不会被编译, 但是定义了一个 和依赖名称一样的 feature, 即 gif, 在代码中可以使用 cfg(feature = "gif"), 然后命令行中可以 --features gif 使用条件编译
# 当然, 也能这样使用:
# [dependencies]
# ravif = { version = "0.6.3", optional = true }
# rgb = { version = "0.8.25", optional = true }
#
# [features]
# avif = ["ravif", "rgb"] (无法直接使用 raif, 或者 rgb)
gif = { version = "0.11.1", optional = true }
# [dev-dependencies]表的作用用来设置测试( tests)、示例 (examples)和基准测试( benchmarks)时使用的依赖, 在执行 cargo test 或 cargo bench 命 令 时使用 。
[dev-dependencies]
# build 依赖库
[build-dependencies]
cc = "1.0"
# 打开指定 feature
[dependencies]
serde = { version = "1.0.118", features = ["derive"] }
# 禁用默认打开的 feature
flate2 = { version = "1.0.3", default-features = false, features = ["zlib"] }
# 条件编译功能 (选择性地编 译 代 码)
# 通过命令行 --features "foo bar"
# 默认所有 features 是关闭的, 除非手动打开, 通过 default feature 可以改变这一默认约定
# 可以通过引入依赖时指定 default-features=false 即 flate2 = { version = "1.0.3", default-features = false, features = ["zlib"] } 来防止默认打开某些 feature
[features]
default=["use_std"] # use_std feature 就默认打开了
use_std=[]
unstable= ["pattern"]
patter=[]
# 打开jpeg-decoder依赖的 rayon feature
parallel = ["jpeg-decoder/rayon"]
# 最终编译目标库的信息
[lib]
name = foo # 表示将来编译的库名字为“libfooa” 或 “libfoo.so"等。
crate-type = dylib # 比如 crate-type = [”dylib”, ”staticlib”],表示可 以同时编译生成动态库和静态库。
path = "src/lib.rs" # 表示库文件入口 , 如果不指定, 则默认是 src/lib.rs。
test=true # 表示可以使用单元测试
bench = true # 表示可以使用性能基准测试, 若代码中没有提供性能基准测试, 则可设置为 false
# 双中括号 -> 数组
[[test]]
path = "tests/test_default.rs"
name = "default"
[[test]]
name = "aa"
path = "tests/aa.rs"
# 使用本地仓库中的代码build
[patch.crates-io]
uuid = { path = "../path/to/uuid" }
# 默认 master 分支, # 手动指定 commit id, 不过有了 lock 文件, 就不必这么干了
uuid = {git = "https://github.com/uuid-rs/uuid.git", rev = "9f35b8e"}
# 四个内建的 profile : dev, release, test, and bench, 在命令行通过 --release 指定
# 对每个 profile 进行更细致的配置
# 分别代表对 Release、 Bench 和 Test, debug 四种 编译模式进行配置
[profile.release]
debug=true # 编译时, 包含 debug 信息
# 优化级别
opt-level = 3 # 编译优化, 耗时更长
[profile.bench]
debug=true
[profile.test]
debug=true
[profile.dev]
opt-level = 0 # 优化级别, 命令行通过 -C opt-level=1 指定
# 0: no optimizations, also turns on cfg(debug_assertions) (the default).
# 1: basic optimizations.
# 2: some optimizations.
# 3: all optimizations.
# s: optimize for binary size.
# z: optimize for binary size, but also turn off loop vectorization.
overflow-checks = false # Disable integer overflow checks
lto= # 连接时间优化
8.5.4. cargo.lock
锁定依赖版本
8.5.5. workspace
工作空间可以管理多个 proj 和 lib
新建 Cargo.toml 作为根包的元数据 (工作空间中的子包 也都有自己的 Cargo.toml 配置,各自独立, 互不影响)
[workspace]
members = [
"main", # 可执行 主程序
"core", # 核心类库
"util", # 工具库
]
不管是编译根包还是子包,最终的编译结 果永远都会输出到根包的 target 目录下,并且整个工作空间只允许有一个 Cargo.lock 文件。
cargo new [--bin] main, cargo new --lib core, cargo new --lib util; 由于每次创建时, cargo 都会检查 顶层 Cargo 配置文件中的 member 是否都存在, 所以中间可能检查出现错误, 不必担心, 全部创建完错误就消失了
lib 类型类型需要将新建的 module (即rs文件) 在 lib.rs 中声明 pub mod xxx, pub 可选
8.5.6. 依赖的版本号规则
// Rust 包使用的是语义化版本号 (SemVer)。基本格式为“X卫Z”
// • x,主版本号 当做了不兼容或颠覆性的更新时 , 修改此版本号。
// • y, ;欠版本号 (minor)。当做了向下兼容的功能性修改时,修改此版本号 。
// • z,修订版本号 (patch)。当做了向下兼容的问题修正时,修改此版本号。
// 符号:
// ^: 版本号必须大于指定版本, 新的版本必须满足不修改[major, minor, patch]中最左边非零数字。如指定 ^1.0.0, 等价于 >=1.0.0 <2.0.0
// *: 通配符, 可以用在[major, minor,patch]的任何一个上面。
// ~: 允许修改[major, minor, patch]中没有明确指定的版本号
// 手动指定, 通过 >, <, =, >=, <= 来指定版本号 。
8.6. build.rs
build.rs可实现本项目编译前的额外操作,比如代码生成(如 grpc)、调用cmake/clang/gcc/ndk-build等编译所依赖的C/C++库、读取C/C++头文件生成FFI文件给Rust项目使用等等,相当于Rust写的shell脚本
先于 cargo build 被编 译
fn main() {
...
}
8.7. 项目管理案例
8.7.1. 导出自定义宏
cargo new --bin hello_macro, 新建 lib.rs (名字任意), 定义 macro, 导出
#[macro_export]
macro_rules! map {
// 统计 item 个数时使用的单位, 这里使用 空元组, 不占空间
// @unit 是约定俗成的在宏内部定义宏的命名规则
// 必须定义在开头条, 否则就按照普通匹配分支处理了
(@unit $($x:tt)*) => {()};
(@count $($key:expr),* ) => {
(<[()]>::len(&[$(map!(@unit $key)),*]));
};
($($key:expr => $value:expr),* $(,)*) => (
{
let _cap = map!(@count $($key),*);
let mut _map = std::collections::HashMap::with_capacity(_cap);
$(
_map.insert($key, $value);
)*
_map
}
)
}
在 main.rs 中导入使用
// #[macro_use] extern crate hello_async;
// or
use hello_macro::map;
fn main() {
let map = map!(
1 => "a",
2 => "b",
);
println!("{:?}", map);
}
// 导出同个包下, 其他 mod 内的宏
#[macro_use]
mod macros {
macro_rules! xxx {...}
macro_rules! yy {..}
}
fn main() {
// 直接使用
xxx!(...);
}
8.7.2. 导入自定义 crate
cargo new web-server
cd web-server
cargo new --lib thread-pool
修改 web-server 的 cargo.toml:
[dependencies]
thread-pool = {path = "./thread-pool" } # 必须为 thread-pool, 和库名一致; thread_pool 错误, threadpool错误
# 使用: use thread_pool::xxxx (变为下划线)
8.7.3. 执行子目录中的 module
[[example]]
name = "udp_server"
path = "examples/udp_server.rs"
[[example]]
name = "udp_client"
path = "examples/udp_client.rs"
[[example]]
name = "tcp_server"
path = "examples/tcp_server.rs"
[[example]]
name = "tcp_client"
path = "examples/tcp_client.rs"
然后在 /examples 下新建 rs 文件, 写 main 方法即可
8.7.4. 导入自定义 module
//ferris_says 为自定义 module
mod ferris_says; // 方法 1: 通过声明导入 module
use ferris_says::say;// 方法 2: 导入模块的方法 // 支持 as , 如 use xxx as yyy
use std::io::{stdout, BufWriter};
fn demo() {
let stdout = stdout();
let message = String::from("Hello fellow Rustaceans!");
let width = message.chars().count();
let mut writer = BufWriter::new(stdout.lock());
say(message.as_bytes(), width, &mut writer).unwrap();
}
8.7.5. 导入第三方 crate
// Rust 2015 版本的写法
// 在 Rust2018 版本中,可以省略掉 extern erate, 因为在 Cargo.toml 中已经添加了依赖
// extern crate 声明包的名称 是 linked_list, 用的是下画线“_”, 而在 Cargo.tom! 中用的是连字符"-"。这是怎么回事呢?其实 Cargo 默认会把连字符转换成 下画线
extern crate linked_list,
9. 单元测试
https://github.com/nvzqz/divan 性能测试框架
/// 单元测试
///
/// 使用 cargo test 运行
///
/// 运行某个特定的测试方法 cargo test test_any_panic
///
/// cargo test panic 方法名中含有 panic 的测试方法会运行
///
#[cfg(test)]// 条件编译 , 告诉编译器只在运行测试( cargo test 命令)时才编译执行
mod tests {
// 注意这个惯用法:在 tests 模块中,从外部作用域导入所有名字。
use super::*;
#[test]
fn test_xx() {
println!("hello unit test");
}
// 测试 panic
#[test]
#[ignore] // 忽略测试, 或者使用 cargo test -- --ignored 命令来运行它们。
#[should_panic(expected = "assertion failed")] // 倒置我们的测试结果 (如果发生错误测试将会成功并且如果没有错误会失败), 一般 和 `(expected = "assertion failed")` 一起使用
fn test_any_panic() {
divide_non_zero_result(1, 0);
}
// 测试 带有输出文本的panic
#[test]
#[should_panic(expected = "Divide result is zero")]
fn test_specific_panic() {
divide_non_zero_result(1, 10);
}
10. 交叉编译 and 条件编译
https://github.com/japaric/rust-cross#tldr-ubuntu-example https://zhuanlan.zhihu.com/p/76611800 https://zhuanlan.zhihu.com/p/128626720
///条件编译
///
/// cfg 属性:在属性位置中使用 #[cfg(...)]
///cfg! 宏:在布尔表达式中使用 cfg!(...)
///
fn condition_compile() {
// 这个函数仅当目标系统是 Linux 的时候才会编译
#[cfg(target_os = "linux")]
fn are_you_on_linux() {
println!("You are running linux!")
}
// 而这个函数仅当目标系统 **不是** Linux 时才会编译
#[cfg(not(target_os = "linux"))]
fn are_you_on_linux() {
println!("You are *not* running linux!")
}
are_you_on_linux();
if cfg!(target_os = "linux") {
println!("Yes. It's definitely linux!");
} else {
println!("Yes. It's definitely *not* linux!");
}
// 自定义条件
//
// `rustc --cfg some_condition custom.rs && ./custom`
//
// #[cfg(some_condition)]
// fn conditional_function() {
// println!("condition met!")
// }
// conditional_function();
}
11. 并发
11.1. 通用概念
11.1.1. 进程 and 线程
进程是资源分配的最小单元,线程是程序执行时的最小单元
可以使用多进程来提供并发,比如 Master-Worker 模式,由 Master 进程来管理 Worker 子进程, Worker 子进程执行任务 。 Master 和 Worker 之间通常使用 Socket 来进行进程间通信好处是程序健壮, 缺点是耗费资源
使用线程提供并发, 占用资源少, 但是编程调试相当复杂
11.1.2. 事件回调实现的异步并发
多进程/线程 实现的并发, 还是无法支撑万级别的并发访问, 因为就算一个线程处理一个连接, 也要上万线程, 这时候服务器也崩了
事件驱动实现并发: 只有一个线程, 不断从事件队列中查询是否有事件发生, 若有, 则调用关联的回调函数, 整个过程是非阻塞的
为了解决回调地狱的问题, 新的方案出现了 --> Promise, Future, promise 站在任务处理者的角度,将异步任务完成或失败的 状态标记到 Promise 对象中 。 Future 则站在任务调用者的角度,来检测任务是否完成,如果 完成则直接获取结果,如果未完成则阻塞直到获取到结果 , 或者编写回调函数避免阻塞
为了进一步解决代码冗余 ---> 协程: 描述了一种任务协同执行的方式, 只有一个线程, 同时处理多个任务, 一个时间片在执行任务 1, 某个时间片又切到执行任务 2, 看起来就好像任务 1,2 同时在执行 (整个概念类似 CPU 对线程的调度方式)
总的来说,协程可以让开发者用写同步(顺序)代码的方 式编写可异步执行的代码
协程是以线程为容器的, 协程的特点是内存占用比线程更小、上下文切换的开销更小, 也被称为用户 态线程,所以可大量使用
虽然充分挖掘了单线程的利用率,在 单线程下可以处理高并发io,但却无法利用多核, 因为始终只有一个线程。
11.2. 线程基本使用
11.2.1. 创建线程
/// 并发 闭包
/// Rust 中通过 std::thread::spawn 函数创建本地操作系统(native OS)线程
///
/// spawn() 返回新线程的句柄(handle),我们必须拥有句柄,才能获取线程的返回值, 通过 handle.join().unwrap();
//
//
///
fn concurrent() {
use std::thread;
use std::time::Duration;
// 创建
//
// 普通函数的写法, 不推荐写法
//
fn spawn_function() {
for i in 0..5 {
println!("spawned thread print {}", i);
thread::sleep(Duration::from_millis(1));
}
}
let t = thread::spawn(spawn_function);
//
// 闭包的写法
let t = thread::spawn(|| {
for i in 0..5 {
println!("spawned thread print {}", i);
thread::sleep(Duration::from_millis(1));// 睡眠
}
});
t.join().unwrap();// 等待线程结束 or 获取返回值
//move 强制所有权迁移
//
//在子线程中尝试使用当前函数的资源, 这一定是错误的
// 需要使用 move, 将资源所有权移动到子线程内部使得外部资源失效
//
// let s = "hello"; // 若是 &str 类型, 则 move 执行的是 copy, 闭包外层 s 还是有效的
let s = "hello".to_owned();// 若为 String, 则 move 执行 移动语义, s 失效
let handle = thread::spawn(move || {// 一定要加 move
println!("sub thread, s = {}", s);
});
// 错误, s已经 失效了
println!("main thread, s= {}", s);
handle.join().unwrap();
}
11.2.2. 自定义配置线程
// 设置线程栈, 线程名
//
// 直接使用 thread::spawn生成的线程, 默认没有名称, 并且其栈大小默认为 2MB (其实底层还是通过 builder 创建的)
// 使用 thread::Builder 结构体来创建可配置的线 程, 主线程无法配置, 和 rust 无关, 因为主线程默认使用 进程的栈, 由操作系统决定
// 也可以通过指定环境变 量 RUST_MIN_STACK 设置新创建的线程的线程栈, 会被 builder 覆盖
//
//
use std::{panic::catch_unwind, thread::{Builder, current}};
fn main() {
let mut ths = vec![];
for id in 0..3 {
let thread_builder = Builder::new()
.name(format!("child-{}", id))
// unit: byte
.stack_size(3 * 1024);
let child = thread_builder.spawn(move || {
println!("child id = {}", id);
if id == 2 {
// panic!("panic.");
catch_unwind(|| {
panic!("panic.");
}).unwrap();
println!("catch panic in {}", current().name().unwrap());
}
}).unwrap();
ths.push(child);
}
for t in ths {
t.join().unwrap();
}
}
11.2.3. 线程本地变量
// 线程本地变量
use std::cell::RefCell;
use std::thread;
fn main() {
thread_local!(static FOO: RefCell<u32> = RefCell::new(1));
FOO.with(|f| {
assert_eq!(*f.borrow(), 1);
*f.borrow_mut() = 2;
});
thread::spawn(|| {
FOO.with(|f| {
assert_eq!(*f.borrow(), 1);
*f.borrow_mut() = 3;
});
});
FOO.with(|f| {
assert_eq!(*f.borrow(), 2);
});
}
11.2.4. 手动阻塞唤醒
use std::thread;
use std::time::Duration;
fn main() {
let parked_thread = thread::Builder::new()
.spawn(|| {
println!("Parking thread");
// 阻塞
// 也可以 通过 std::thread: :park_timeout 来显 式指定阻塞超时时间
thread::park();
println!("Thread unparked");
}).unwrap();
thread::sleep(Duration::from_millis(10));
println!("Unpark the thread");
// 唤醒
parked_thread.thread().unpark();
parked_thread.join().unwrap();
}
// 此外, 还有 yield_now() 谦让, 让出 cpu 控制权
11.3. 线程同步
11.3.1. 错误示例
// 在线程间传递可变字符串
//
// 直接使用 String
use std::thread::spawn;
fn main() {
let s = String::from("hello");
for _i in 0..3 {
// error
spawn(move || {
s.push_str("xxx");
});
}
}
// 使用 Rc
use std::{rc::Rc, thread::spawn};
fn main() {
// 想在多个线程中共享s,则需要使用。
// Rc实现了!Send, 不可在线程间传递所有权
let mut s = Rc::new(String::from("hello"));
for _i in 0..3 {
let mut s_clone = s.clone();
// error
// spawn 函数传入的 闭包没有实现 Send,这是因为捕获变量没
// 有实现 Send。捕获变量是 Rc<String>类型, 实现的是!Send,正好和 Send相反
spawn(move || {
s_clone.push_str("xxx");
});
}
}
// 使用可以在多线程间被移动和共享的 Arc<T>
use std::{sync::Arc, thread::spawn};
fn main() {
let s = Arc::new(String::from("hello"));
for _i in 0..3 {
let s_clone = s.clone();
// error
// 这是因为 Arc<T>默认是不可变的, 考虑使用具有内部可变性的类型, 如 Cell/RefCell
spawn(move || {
s_clone.push_str("xxx");
});
}
}
// 使用 RefCell 提供内部可变性
use std::{cell::RefCell, sync::Arc, thread::spawn};
fn main() {
let s = Arc::new(RefCell::new(String::from("hello")));
for _i in 0..3 {
let s_clone = s.clone();
// error
// `RefCell<String>` cannot be shared between threads safely
spawn(move || {
let s_clone = s_clone.borrow_mut();
s_clone.push_str("xxx");
});
}
}
// 正确方式: 使用 Mutex
//
use std::{sync::{Arc, Mutex}, thread::spawn};
fn main() {
// Arc 用于支持安全的多引用
// Mutex 用于安全的提供内部可变性
let s = Arc::new(Mutex::new(String::from("hello")));
let mut ths = vec![];
for _i in 0..3 {
let s_ref = s.clone();
let child = spawn(move || {
let mut s_ref_mut = s_ref.lock().unwrap();
s_ref_mut.push_str(" xxx");
});
ths.push(child);
}
for t in ths {
t.join().unwrap();
}
}
11.3.2. 锁
// Mutex<T> 互斥锁: 支持跨线程安全共享可变变量的容器, 同时只允许一个线程访问内部 可变数据, 类似 线程安全版本的 RefCell
/// - lock() 返回内部数据的可变引用(阻塞当前线程, 直到拿到锁)
// 返回值 LockResult<MutexGuard<T>>, 超出作用域会自动释放锁
// - try_lock() 获取 锁的时候不会阻塞当前线程, 如果得到锁 , 就返回 MutexGuard<T>; 如果得不到锁,就返回 Err。
//
/// RefCell<T>: 使得内部数据可变
// Rc<T>: 原子引用计数 , 允许多引用
//
// Arc<T> : 线程安全的 Rc<T>, 允许多线程下的多引用
/// Mutex<T> : 线程安全的 RefCell, 提供多线程下内部数据的可变引用
///
///
/// 通道都类似于单所有权,因为一旦将一个值传送到通道中,将无法再使用这个值。
/// 锁类似于多所有权: 多个线程可以访问相同的内存位置 , 只是不能同一时候访问
///
///
///
///
fn lock_demo() {
//
// 计数器示例
//
use std::sync::{Mutex, Arc};
use std::thread;
// 不能仅仅使用 Mutex::new(0), 因为有多个 Thread需要它, counter移动进入某个Thread后其他Thread就没法拥有counter了
// 也不能用Rc::new(Mutex::new(0)), 因为Rc<T>的引用计数, 在多线程下不安全
let counter = Arc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Arc::clone(&counter);
// or
let counter = counter.clone();
let handle = thread::spawn(move || {
// lock() 这个调用会阻塞当前线程, 直到获取锁为止
//
//如果另一个线程拥有锁,并且那个线程 panic 了,
// 则本线程 lock 调用会失败。在这种情况下,没人能够再获取锁,
// 所以这里选择 unwrap 在遇到这种情况时使线程直接 panic
//
//返回 result, 拆包后是 MutexGuard<T>, 是个智能指针, 实现了 Deref所以可以解引用
// 实现了 Drop ,当 MutexGuard 离开作用域时自动释放锁
//
let mut num = counter.lock().unwrap();
// 解引用后, 数据是可变的
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
// 中毒: 线程在获得锁之后发生恐慌
//
let mutex = Arc::new(Mutex::new(1));
let c_mutex = mutex.clone();
let _ = thread::spawn(move || {
let mut data = c_mutex.lock().unwrap();
*data = 2;
// 子线程 panic, 中毒了
panic!("oh no");
}).join();
// 是否中毒, 即查看获取锁的子线程是否 panic
assert_eq!(mutex.is_poisoned(), true);
// 主线程获取锁, 当然获取不到
match mutex.lock() {
// 不可达
Ok(_) => unreachable!(),
Err(p_err) => {
// 提供了 get_ref或 get_mut方法, 获取锁内部的数据
let data = p_err.get_ref();
println!("recovered: {}", data);//2
}
};
// 读写锁
// RwLock<T> 支持多个读线程和一个写线程同时访问 (不像 Mutex<T>只能线程独占访问)
//
// 只要线程没有拿到写锁 , RwLock<T>就 允许任意数量 的读线程获得读锁
//
let lock = RwLock::new(5);
// 读锁和 写锁要使用显式作用域块隔离开 ,这样的话 , 读锁或写锁才能在离开作用 域之后自 动释放 ; 否则会引起死锁,因为读锁和写锁不能同时存在
{
// 获取多个读锁
let r1 = lock.read().unwrap();
let r2 = lock.read().unwrap();
assert_eq!(*r1, 5);
assert_eq!(*r2, 5);
}
{
// 获取写锁
let mut w = lock.write().unwrap();
*w += 1;
assert_eq!(*w, 6);
}
}
// 屏障 (类似 java 的 CountDownLatch)
//
use std::sync::{Arc, Barrier};
use std::thread;
fn main() {
let mut handles = Vec::with_capacity(5);
let barrier = Arc::new(Barrier::new(5));
for _ in 0..5 {
let c = barrier.clone();
handles.push(thread::spawn(move|| {
println!("before wait");
// 使得当前子线程阻塞, 知道 clone 5 次后 barrie 归零后, 线程恢复执行
c.wait();
println!("after wait");
}));
}
for handle in handles {
handle.join().unwrap();
}
}
// 条件变量
// 满足指定条件之前阻塞某一个得到互斥锁的线程
// 条件变量需要配合互斥锁才能使用
//
// - 每个条件变量每次只能和一个互斥体一起使用
// - 使用场景: 当状态成立时通知互斥体
use std::sync::{Arc, Condvar, Mutex};
use std::thread;
fn main() {
let pair = Arc::new((Mutex::new(false), Condvar::new()));
let pair_clone = pair.clone();
thread::spawn(move || {
let &(ref lock, ref cvar) = &*pair_clone;
let mut started = lock.lock().unwrap();
// 修改锁内部数据
*started = true;
// 通知主线程
cvar.notify_one();
});
let &(ref lock, ref cvar) = &*pair;
let mut started = lock.lock().unwrap();
while !*started {
println!("{}", started); // false
//阻塞当前线程(主线程), 直到收到条件变量的通知
started = cvar.wait(started).unwrap();
println!("{}", started); // true
}
}
11.3.3. 原子类型
// AtomicBool、 AtomicIsize、 AtomicPtr 和 AtomicUsize
// 实现自旋锁
use std::sync::Arc;
use std::sync::atomic::{AtomicUsize, Ordering};
use std::thread;
fn main() {
// 初始值设置为 1
let spinlock = Arc::new(AtomicUsize::new(1));
let spinlock_clone = spinlock.clone();
let thread = thread::spawn(move|| {
// 修改为 0;
// 同时指定内存顺序
spinlock_clone.store(0, Ordering::SeqCst);
});
// 若不为 0, 则自旋
while spinlock.load(Ordering::SeqCst) != 0 {}
// 阻塞主线程, 等待子线程完成
if let Err(panic) = thread.join() {
println!("Thread had an error: {:?}", panic);
}
}
11.3.4. channel
/// channel 消息传递
///
/// 具体实现实际上是一个 多生产者单消费者 (Multi-Producer-Single-Consumer, MPSC) 的先进先出(FIFO〕 队列, 底层基于链表实现
//
// 三种类型的csp 进程:
// - Sender 用于发送异步消息
// - SyncSender 发送同步消息
// - Receiver接收消息
//
// 两种类型的 channel
// - 异步无界 Channel - let (sender, receiver): (Sender, Receiver) = channel(); 发送消息是异步无阻塞的, 缓冲区无限大
// - 同步有界 Channel - let (sender, receiver): (SyncSender, Receiver) = sync_channel(size);可以预分配具有固定大小的缓冲区 , 满了就阻塞消息发送, 若缓冲区 == 0, sender和 receiver 间变为原子操作
//
fn channel_demo() {
//一个发送者(transmitter)和一个接收者(receiver)
use std::sync::mpsc;// mpsc 是 多个生产者,单个消费者(multiple producer, single consumer)的缩写
use std::thread;
// tx: 发送者
// rx : 接收者
// 此时还无法编译, 因为 Rust 不知道我们想要在通道中发送什么类型, 后续编译器能够自动推断类型
let (tx, rx) = mpsc::channel();
//创建一个新线程作为发送者
//
// //使用 move 将 tx 移动到闭包中这样新建线程就拥有 tx 了, 当
// 发送者执行完逻辑, 退出作用域, tx 也就自动析构了, 接收端也就收到关闭的信号
// (若没有 使用 move, tx 始终存活, 无法自动析构, 会造成 接收者始终阻塞)
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
});
// 接收
//
//这个方法会阻塞主线程执行直到从通道中接收一个值,
//当通道发送端关闭,recv 会返回一个错误表明不会再有新的值到来了
//
//try_recv 不会阻塞,相反它立刻返回一个 Result<T, E>:Ok 值包含可用的信息,而 Err 值代表此时没有任何消息
//可以编写一个循环来频繁调用 try_recv,在有可用消息时进行处理,其余时候则处理一会其他工作直到再次检查
//
let received = rx.recv().unwrap();
println!("Got: {}", received);
//也可以迭代接收器, 当通道被关闭时,迭代器也将结束
//
for received in rx {// 或者 rx.iter()
println!("Got: {}", received);
}
//通过克隆发送者来创建多个生产者
//
//
use std::sync::mpsc::{Sender, Receiver};
static NTHREADS: i32 = 3;
let (tx, rx): (Sender<i32>, Receiver<i32>) = mpsc::channel();// 手动指定传输数据的类型
for id in 0..NTHREADS {
// sender 端可被复制
let thread_tx = tx.clone();
// 或者
let tx1 = mpsc::Sender::clone(&tx);
thread::spawn(move || {
// 被创建的线程取得 `thread_tx` 的所有权
thread_tx.send(id).unwrap();
println!("thread {} finished", id);
});
}
let mut ids = Vec::with_capacity(NTHREADS as usize);
for _ in 0..NTHREADS {
// 若无可用消息的话,`recv` 将阻止当前线程
ids.push(rx.recv());
}
// 显示消息被发送的次序
println!("{:?}", ids);
}
11.3.5. tokio 中的各种 channel 实现
sync : 容量有限, sender 会被 block
async: 容量无限, sender 不会被 block
rendezvous: 容量为 0, 用于线程间同步
oneshot: 只允许发送一次数据
async/await : 和 sync channel 类似, 但是 waker 不同
11.4. 多线程小例子
11.4.1. 实现线程池
第三方包: threadpool
这里手动实现
11.4.2. 实现 map-reduce 算法
//例子:
//实现 map-reduce 算法
//
let data = "86967897737416471853297327050364959
11861322575564723963297542624962850
70856234701860851907960690014725639
38397966707106094172783238747669219
52380795257888236525459303330302837
58495327135744041048897885734297812
69920216438980873548808413720956532
16278424637452589860345374828574668";
// 创建一个向量,用于储存将要创建的子线程
let mut children = vec![];
let chunked_data = data.split_whitespace();
for (i, data_segment) in chunked_data.enumerate() {
println!("data segment {} is \"{}\"", i, data_segment);
children.push(thread::spawn(move || -> u32 {
// 计算该段的每一位的和:
let result = data_segment
// 对该段中的字符进行迭代..
.chars()
// ..把字符转成数字..
.map(|c| c.to_digit(10).expect("should be a digit"))
// ..对返回的数字类型的迭代器求和
.sum();
// println! 会锁住标准输出,这样各线程打印的内容不会交错在一起
println!("processed segment {}, result={}", i, result);
// 不需要 “return”,因为 Rust 是一种 “表达式语言”,每个代码块中
// 最后求值的表达式就是代码块的值。
result
}));
}
// 把每个线程产生的中间结果收入一个新的向量中
let mut intermediate_sums = vec![];
for child in children {
// 收集每个子线程的返回值
let intermediate_sum = child.join().unwrap();
intermediate_sums.push(intermediate_sum);
}
let final_result = intermediate_sums.iter().sum::<u32>();
println!("Final sum result: {}", final_result);
11.4.3. 多线程统计和
//
//
//
const TOTAL_SIZE:usize = 100 * 1000; //数组长度
const NTHREAD:usize = 6; //线程数
let data : Vec<i32> = (1..(TOTAL_SIZE+1) as i32).collect(); //初始化一个数据从1到n数组
let arc_data = Arc::new(data); //data 的所有权转给了 ar_data
let result = Arc::new(AtomicU64::new(0)); //收集结果的数组(原子操作)
let mut thread_handlers = vec![]; // 用于收集线程句柄
for i in 0..NTHREAD {
// clone Arc 准备move到线程中,只增加引用计数,不会深拷贝内部数据
let test_data = arc_data.clone();
let res = result.clone();
thread_handlers.push(
thread::spawn(move || {
let id = i;
//找到自己的分区
let chunk_size = TOTAL_SIZE / NTHREAD + 1;
let start = id * chunk_size;
let end = std::cmp::min(start + chunk_size, TOTAL_SIZE);
//进行求和运算
let mut sum = 0;
for i in start..end {
sum += test_data[i];
}
//原子操作
res.fetch_add(sum as u64, Ordering::SeqCst);
println!("id={}, sum={}", id, sum );
}
));
}
//等所有的线程执行完
for th in thread_handlers {
th.join().expect("The sender thread panic!!!");
}
//输出结果
println!("result = {}",result.load(Ordering::SeqCst));
11.4.4. 带线程池的 webserver
main.rs 是项目启动入口
lib.rs 为 项目内部的 子库
main.rs :
mod lib;
use std::net::{TcpListener, TcpStream};
use std::io::{Read, Write};
use std::fs::read_to_string;
use std::thread;
use std::time::Duration;
use thread_pool::ThreadPool;// 横线变为下划线了
fn main() {
let listener = TcpListener::bind("127.0.0.1:8080").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
match stream {
Ok(stream) => {
pool.execute(|| {
handle_conn_quick(stream);
});
// handle_conn_quick(stream);
}
Err(_) => eprintln!("error of connection"),
}
}
}
//
fn handle_conn_quick(mut stream: TcpStream) {
let mut buf = [0u8; 512];
stream.read(&mut buf).unwrap();
println!("************** req ***************");
println!("{}\n", String::from_utf8_lossy(&buf));
let get = b"GET / HTTP/1.1\r\n";
let sleep = b"GET /sleep HTTP/1.1\r\n";
let (status_line, html_path) = if buf.starts_with(get) {
("HTTP/1.1 200 OK\r\n\r\n", "resources/hello.html")// 相对于根路径
} else if buf.starts_with(sleep) {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK\r\n\r\n", "resources/hello.html")
}
else {
("HTTP/1.1 404 NOT FOUND\r\n\r\n", "resources/404.html")
};
let resp = format!("{}{}", status_line, read_to_string(html_path).unwrap());
println!("************** resp ***************");
println!("{}\n", resp);
stream.write(resp.as_bytes()).unwrap();
stream.flush().unwrap();
}
// 这是单线程 webserver 的代码
#[allow(dead_code)]
fn handle_conn(mut stream: TcpStream) {
let mut buf = [0u8; 1024];
let mut content = String::new();
loop {
let len = stream.read(&mut buf).unwrap();
content.push_str(&String::from_utf8_lossy(&buf)[..]);
if len < buf.len() {
break;
}
}
let get = "GET / HTTP/1.1\r\n";
let (status_line, html_path) = if content.starts_with(get) {
("HTTP/1.1 200 OK\r\n\r\n", "resources/hello.html")
} else {
("HTTP/1.1 404 NOT FOUND\r\n\r\n", "resources/404.html")
};
let html = read_to_string(html_path).unwrap();
let resp = format!("{}{}", status_line, html);
stream.write(resp.as_bytes()).unwrap();
stream.flush().unwrap();
}
lib.rs:
use std::thread::{JoinHandle, spawn};
use std::sync::mpsc::{Sender, channel, Receiver};
use std::sync::{Arc, Mutex};
#[cfg(test)]
mod tests {
#[test]
fn it_works() {
assert_eq!(2 + 2, 4);
}
}
pub struct ThreadPool {
// 要实现的行为是创建线程并稍后发送任务代码
// 所以不能直接存 Thread, 而要引入中间层 worker
// 若直接使用 Thread, 创建线程后, 任务会直接立即执行, 不行
workers: Vec<Worker>,
sender: Sender<Msg>,
}
impl Drop for ThreadPool {
fn drop(&mut self) {
// 向每个 worker发送终止消息, 使得任务代码跳出receive循环
// 为什么要分为两个for循环?
//如果尝试在同一循环中发送消息并立即 join 线程,则无法保证当前迭代的 worker 是从通道收到终止消息的 worker
for _ in &mut self.workers {
self.sender.send(Msg::TerminateMsg).unwrap();
}
for w in &mut self.workers {// 需要获取workers的可变引用
println!("worker {} stop", w.id);
// join 调用者需要是 非引用
// 那么, 需要一个方法将 thread 移动出拥有其所有权的 Worker 实例以便 join 可以消费这个线程。
//
// w.thread.join().unwrap();
if let Some(thread) = w.thread.take() {//take 方法会取出 Some 而留下 None
thread.join().unwrap();
}
}
}
}
enum Msg {
JobMsg(Job),
TerminateMsg,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// 创建线程池。
///
/// # Panics
///
/// `new` 函数在 size 为 0 时会 panic。
pub fn new(size: usize) -> Self {
assert!(size > 0);
let mut workers = Vec::with_capacity(size);
let (sender, receiver) = channel();
let receiver = Arc::new(Mutex::new(receiver));
//多 生产者,单 消费者 的。这意味着不能简单的克隆通道的消费端来解决问题
//我们希望通过在所有的 worker 中共享单一 receiver,在线程间分发任务
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender,
}
}
pub fn execute<F>(&self, f: F)
// 没参数, 没返回值的闭包
where F: FnOnce() + Send + 'static
{
let job = Box::new(f);
self.sender.send(Msg::JobMsg(job)).unwrap();
}
}
struct Worker {
id: usize,
thread: Option<JoinHandle<()>>,// "()" 表示线程中的任务没有返回值
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<Receiver<Msg>>>) -> Self {
let thread = spawn(move|| {
// 不可使用 while let, 因为while 表达式中的值还有块都一直处于作用域中, 锁无法释放
//
// 只能使用 loop 循环,
//使用 loop 并在循环块之内而不是之外获取锁和任务,
// lock 方法返回的 MutexGuard 在 let job 语句结
// 束之后立刻就被丢弃了。这确保了 recv 调用过程中持有锁,
// 而在 job() 调用前锁就被释放了,这就允许并发处理多个请求
loop {
let msg = receiver.lock().unwrap().recv().unwrap();
match msg {
Msg::JobMsg(job) => {
println!("worker {} running", id);
job();
},
Msg::TerminateMsg => {
println!("worker {} receive terminate msg", id);
break;
},
}
}
});
Self {
id,
thread: Some(thread),
}
}
}
11.5. rayon 并行执行任务
轻松地将顺序计算转换为安全的并行计算,并且保证无数据竞争
底层使用 线程池执行任务, 若工作线程都被占用, 则新加的任务会顺序执行
// 并行迭代器
//
extern crate rayon;
use rayon::prelude::*;
fn sum_of_squares(input: &[i32]) -> i32 {
input.par_iter()// 返回一个不可变的并行迭代器类型, 通过 map 构造了新的 集合迭代器
.map(|&i| i * i).sum()
}
fn increment_all(input: &mut [i32]) {
input.par_iter_mut() // 回一个可变的并行迭代器类型。
.for_each(|p| *p += 1);// 直接在原有基础上修改
}
fn main(){
let v = [1,2,3,4,5,6,7,8,9,10];
let r = sum_of_squares(&v);
println!("{}", r);
let mut v = [1,2,3,4,5,6,7,8,9,10];
increment_all(&mut v);
println!("{:?}", v);
}
// join()
// 并不保证接收的两个闭包一定并行执行, 因为 若 线程池中没有空闲的线程了, 新任务还是只能顺序执行
//
extern crate rayon;
fn fib(n: u32) -> u32 {
if n < 2 { return n; }
let (a, b) = rayon::join(
// 接收两个闭包 , 并行执行
|| fib(n - 1), || fib(n - 2)
);
a + b
}
fn main() {
let r = fib(32);
assert_eq!(r, 2178309);
}
11.6. CrossBeam 无锁的数据结构
是对 标准库的扩展和包装,
// - 扩展原子类型, 为基础库中的原子类型实现了 AtomicConsume trait
// - Scoped 线程: 允许子线程可以安全地使用父线程中的引用
// - 使用缓存行填充提升井发性能
// - MPMC Channel: 多生产者多消 费者通道
11.7. RwLock 和 RefCell
// RwLock<T>相当于线程安全版本的 RefCell<T>,同时运行多个 reader或者一个 writer
// RwLock 读写锁,是多读单写锁,也 叫共享独占锁 。 它允许多个线程读,单个线程写 。 但是在写的时候 , 只能有一个线程占有写锁 ; 而在读的时候, 允许任意线程获取读锁 。 读锁和写锁不能被同时获取
// 所以在度多写少的场景, 使用 读写锁可以有更高的并发支持
11.8. Mutex
// Mutex<T>是锁,同一时间仅允许有-个线程进行操作, 不管是读还是写。
// 本质是一个 struct
11.9. AtomicPtr 和 Cell
// Atomic 系列类型: AtomicBool、 Atomiclsize、 AtomicUsize和AtomicPtr
// 可以用 AtomicPtr 来模拟其他想要的类型
// AtomicPtr 相当于线程安全版本 的 Cell<T>
11.10. Send 和 Sync trait
Send 表示该类型的值可以安全的在多线程中传递, 转移 ownership (表示跨线程 move);
几乎所有的Rust类型都是Send的,但是例外:例如Rc<T>是不能Send的。
任何完全由Send类型组成的类型也会自动被标记为Send
Sync 表示类型可以安全的在多个线程中拥有其值的引用 (表示跨线程 share data, 可以被安全的 borrow)
即,对于任意类型T,如果&T(T 的引用)是Send的话T就是Sync的,这意味着其引用就可以安全的发送到另一个线程
手动实现Send和Sync是不安全的。通常并不需要手动实现Send和Sync trait,因为由Send和Sync的类型组成的类型,自动就是Send和Sync的。因为他们是标记trait,甚至都不需要实现任何方法
12. 异步并发
12.1. 异步概念
12.1.1. 为什么使用异步
想要同时运行多个任务, 可以使用多线程, 但是在不同线程之间的切换和线程之间的数据共享过程中,涉及到很多开销。即使是一个只是坐着什么都不做的线程,也会消耗宝贵的系统资源
异步可以在不创建多个线程的情况下同时运行多个任务, 具体来说就是使用协程 coroutine
12.1.2. 普通多线程 webserver
例子: 从两个 server下载, 第一个资源 耗时 3s, 第二个资源耗时 1s , 总共耗时 4s, 改为 多线程可以缩短为 3s, 但是有线程切换的开销, 最好的是 改为异步
// client
fn start_client() -> Result<()> {
// 顺序执行, 耗时长, 4s
// connect_to_server("localhost", 8080, "send to server0: 8080")?;
// connect_to_server("localhost", 8081, "send to server1: 8081")?;
// 多线程, 进一步, 可以考虑 使用线程池
let mut handles = Vec::new();
let handle_server0 = spawn(move || {
connect_to_server("localhost", 8080, "send to server0: 8080");
});
handles.push(handle_server0);
let handle_server1 = spawn(move || {
connect_to_server("localhost", 8081, "send to server0: 8081");
});
handles.push(handle_server1);
for handle in handles {
handle.join();
}
Ok(())
}
fn connect_to_server(host: &str, port: u16, content: &str) -> Result<()> {
let mut s = TcpStream::connect((host, port))?;
s.write(content.as_bytes())?;
let mut buf_reader = BufReader::new(&s);
let mut buf = Vec::new();
buf_reader.read_until(b'\n', &mut buf)?;
println!(">>> recv from server : {}", std::str::from_utf8(&buf).unwrap());
Ok(())
}
// server1
fn start_server1() -> Result<()> {
let tcp_listener = TcpListener::bind("localhost:8080")?;
for stream in tcp_listener.incoming() {
handle_conn(&mut stream?, 3)?
}
Ok(())
}
//server2
fn start_server2() -> Result<()> {
let tcp_listener = TcpListener::bind("localhost:8081")?;
for stream in tcp_listener.incoming() {
handle_conn(&mut stream?, 1)?
}
Ok(())
}
fn handle_conn(s: &mut TcpStream, wait_seconds: u64) -> Result<()> {
let mut buf = [0; 512];
loop {
let len = s.read(&mut buf)?;
if len == 0 {
return Ok(());
}
sleep(Duration::from_secs(wait_seconds));
s.write(&buf[..len])?;
s.write("\n".as_bytes())?;
}
}
12.1.3. 改进后的异步版本
use std::{
io::{BufRead, BufReader, Read, Result, Write},
net::{TcpListener, TcpStream},
str::from_utf8,
};
use futures::{executor::block_on, join};
fn main() {
block_on(conn_all_async())
}
async fn conn_all_async() {
let f0 = conn_server_async("localhost", 8080, "send to server0: 8080");
let f1 = conn_server_async("localhost", 8081, "send to server0: 8081");
join!(f0, f1);// 等待 f0, f1 完成
}
async fn conn_server_async(host: &str, port: u16, content: &str) -> Result<()> {
conn_serve(host, port, content)
}
fn conn_serve(host: &str, port: u16, content: &str) -> Result<()> {
let mut s = TcpStream::connect((host, port))?;
s.write(content.as_bytes())?;
let mut buf = Vec::new();
let mut buf_reader = BufReader::new(&s);
buf_reader.read_until(b'\n', &mut buf)?;
println!("recv from server: {}", from_utf8(&buf).unwrap());
Ok(())
}
12.2. 基本使用
12.2.1. block_on
定义异步函数, 然后使用 block_on 阻塞主线程:
// futures = "0.3"
use futures::executor::block_on;
fn main() {
let hello_future = hello();// 异步执行 (不会等待执行完), hello_future 代表异步函数的 handle 句柄
println!("main finish");
// 阻塞 main thread,
// 接受一个 future, 返回真实结果
block_on(hello_future);
}
// 异步函数
async fn hello() {
println!("hello async");
}
12.2.2. await
使用 .await 等待异步函数执行完, 用于多个异步函数有依赖关系
// futures = "0.3"
use futures::executor::block_on;
fn main() {
block_on(hello2());// 阻塞等待 hello2 执行完
}
async fn hello() {
println!("hello async");
}
async fn hello1() {
hello().await;// 等待 hello() 执行完
println!("hello 1");
}
async fn hello2() {
hello1().await; //等待 hello1 执行完
println!("hello 2");
}
12.2.3. joinn
并行执行异步函数
use futures::executor::block_on;
use std::time::Duration;
fn main() {
let main = async_main();
block_on(main);//阻塞
}
#[derive(Debug)]
struct Song;
async fn learn_song() -> Song {
// 不能使用 thread::sleep
async_std::task::sleep(Duration::from_secs(1)).await; //async-std = "1.5"
println!("learn song");
Song
}
async fn sing_song(song: Song) {
async_std::task::sleep(Duration::from_secs(1)).await;
println!("sing song: {:?}", song);
}
async fn dance() {
println!("dance");
}
async fn learn_and_sing() {
let song = learn_song().await;// 等待执行完
sing_song(song).await;// 也要加 await, 否则主线程不会等待 sing_song() 执行完就继续前进了
}
async fn async_main() {
let f1 = learn_and_sing();
let f2 = dance();
// `join!` 类似于 `.await` ,但是可以等待多个 future 并发完成
futures::join!(f1, f2); // f1, f2 并行完成, 返回 (handle1, handle2)
//dance
//learn song
//sing song: Song
}
12.3. future并发模式
12.3.1. future底层是生成器
要支持async/await异步开发, 最好是能有协程的支持,
一种是有栈协程(Stackful); 另一种是无栈协程(Stackless)。对于有栈协程的实现, 一般每个协程都自带独立的栈,功能强大, 但是比较耗 内存, 性能不如无栈协程。 而无栈协程一般是基于状态机(StateMachine) 来实现的, 不使 用独立 的栈,具体的应用形式 叫生成器( Generator), rust 使用后者
// 基本使用
#![feature(generators, generator_trait)]
use std::{ops::{Generator, GeneratorState}, pin::Pin};
fn main() {
// 生成器无法接受参数
// 和闭包一样可以捕获外部环境的变量,也可以使用move关键字
// 生成器自动实现了Send和Sync,但不会自动实现Copy或Clone之类的trait
let mut gen = || {
yield 1;// 每个 yield 对应一个不同的状态, 每次调用 resume(), 则返回对应值, 生成器暂时被挂起, 直到再次 调用 resume(),
yield 2;
return 3; // 调用 resume 返回 3, 则 生成器结束
};
match Pin::new(&mut gen).resume(()) {
GeneratorState::Yielded(1) => {},
_ => panic!("error 1"),
}
match Generator::resume(Pin::new(&mut gen), ()) {
GeneratorState::Yielded(2) => {},
_ => panic!("error 2"),
}
match Generator::resume(Pin::new(&mut gen), ()) {
// error
// GeneratorState::Yielded(3) => {},
GeneratorState::Complete(3) => {},
_ => panic!("error 3"),
}
// error
// let state = Generator::resume(Pin::new(&mut gen), ());
// println!("{:?}", state);
}
// 作为函数返回值
//
//
#![feature(generators, generator_trait)]
use std::ops::Generator;
pub fn up_to(limit: u64) -> impl Generator<Yield = u64, Return = u64> {
move || {
for x in 0..limit {
yield x;
}
return limit;
}
}
fn main(){
let a = 10;
let mut b = up_to(a);
unsafe {
for _ in 0..=10{
let c = b.resume();
println!("{:?}", c);
}
}
}
// 和迭代器 的关系
//
//
// Generator<Yield=T, Return=()> - 如果只关注计算 的过程,而不关 心计 算的结果, 则可以 将 Return 设置为单元类型,只保留 Yield 的类型, 那 么生成器就可以化身为法代器
//
// 生成器的性能比迭代器更高。因为生成器是一种延迟计算或惰性计算, 它避免了不必 要的计算,只有在每次需要时才通过 yield来产生相关的值
//
#![feature(generators, generator_trait)]
use std::{ops::{Generator, GeneratorState}, pin::Pin};
fn main() {
let mut gen = gen();
let mut state = Pin::new(&mut gen);
for _ in 0..3 {
match state.as_mut().resume(()) {
GeneratorState::Yielded(i) => println!("{:?}", i),
_ => println!("complete"),
}
}
}
fn gen() -> impl Generator<Yield = u64, Return = ()> {
|| {
let mut i = 0;
loop {
i += 1;
yield i;
}
}
}
// 和 future关系
//
// Generator<Yield = (), Return = Result<T, E>> - 不关 心过 程 , 只关注结果, 生成器就可以化身为 Future
pub fn up_to(limit: u64) -> impl Generator<Yield = (), Return = Result<u64, ()>> {
move || {
for x in 0..limit {
yield ();
}
return Ok(limit);
}
}
fn main(){
let limit = 2;
let mut gen = up_to(limit);
unsafe {
for i in 0..=limit{
match gen.resume() {
GeneratorState::Yielded(v) => println!("resume {:?} : Pending", i),// 表示还没处理完
GeneratorState::Complete(v) => println!("resume {:?} : Ready", i), // 处理完成, 拿到结果
}
}
}
}
12.3.2. future基本使用用
第三方库 futures-rs 提供
// 基本组件
//
// - Future 真实结果的包装
// 核心函数 poll(), 返回 计算结果是否准备好
// - Executor 调度器
// - Task 具体的异步任务
// 实现一个 Future trait的方式
//
// 方式1:使用 async fn,async fu 会自动为开发者生成返回值是 impl Future 类 型的函数
// 方式2:自定义 结构体,并实现 Future trait
// async/await 原理:
// async 关键字定义异步函数/异步块,底层都会先转为 async 块的形式, 再将 async 块生成一个 Generator<Yield=()>类型的生成器来使用
12.3.3. 动手实现 Future 类型
https://www.rectcircle.cn/posts/rust%E5%BC%82%E6%AD%A5%E7%BC%96%E7%A8%8B/
12.3.4. 动手实现 异步 sleep
通过自定义类型的方式实现一个异步的sleep, 类似于async_std::task:sleep
use futures::executor::block_on;
use std::time::Duration;
use async_std::sync::Arc;
use std::sync::Mutex;
use futures::task::{Waker, Context, Poll};
use futures::Future;
use std::pin::Pin;
use std::thread::{spawn, sleep};
fn main() {
block_on(async { // 异步代码块
println!("start");
TimerFuture::new(Duration::from_secs(2)).await;
println!("end");
});
}
struct TimerFuture {
shared_state: Arc<Mutex<SharedState>>,
}
struct SharedState {
completed: bool,
waker: Option<Waker>,
}
impl Future for TimerFuture {
type Output = ();
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> {
let mut shared_state = self.shared_state.lock().unwrap();
if shared_state.completed {
Poll::Ready(())
} else {
shared_state.waker = Some(cx.waker().clone());
Poll::Pending
}
}
}
impl TimerFuture {
fn new(du: Duration) -> Self {
let shared_state = Arc::new(Mutex::new(SharedState {
completed: false,
waker: None,
}));
let thread_shared_state = shared_state.clone();
spawn(move || {
sleep(du);
let mut state = thread_shared_state.lock().unwrap();
state.completed = true;
if let Some(waker) = state.waker.take() {
waker.wake();
}
});
TimerFuture {
shared_state,
}
}
}
12.4. async-std
相较于 tokio, 年轻, 没有历史包袱, 兼容标准库, 更加小巧
12.5. tokio
13. 简单文件系统
https://zhuanlan.zhihu.com/p/115464045
14. 网络编程
14.1. tcp
use std::net::TcpListener;
use std::io::Read;
// server
fn main() -> std::io::Result<()> {
let listener = TcpListener::bind("127.0.0.1:1080")?;
for stream in listener.incoming() {
match stream {
Ok(mut stream) => {
let mut buf = [0u8; 512];
let len = stream.read(&mut buf)?;
println!("{}", String::from_utf8_lossy(&buf));
},
Err(_) => eprintln!("Error of accept request."),
}
}
Ok(())
}
// client
fn main() -> std::io::Result<()> {
let mut stream = TcpStream::connect("127.0.0.1:1080")?;
for index in 0..3 {
let msg = format!("tcp msg {}", index);
stream.write_all(msg.as_bytes());
debug!("send: {}", msg);
let mut buf = [0u8; 512];
stream.read(&mut buf);
}
Ok(())
}
14.2. udp
// server
use std::net::UdpSocket;
fn main() -> std::io::Result<()> {
let socket = UdpSocket::bind("127.0.0.1:1080")?;
loop {
let mut buf = [0u8; 512];
// receive from client
// len: data length
// src_addr: source address
let (len, src_addr) = socket.recv_from(&mut buf)?;
println!("recv: {}", String::from_utf8_lossy(&buf));
let resp_buf = &mut buf[..len];
resp_buf.reverse();
socket.send_to(resp_buf, src_addr)?;// send data to client
println!("send: {}", String::from_utf8_lossy(resp_buf));
}
Ok(())
}
// client
fn main() -> std::io::Result<()> {
let socket = UdpSocket::bind("127.0.0.1:34254")?;
socket.connect("127.0.0.1:8080");
for index in 0..3 {
let msg = format!("udp msg {}", index);
socket.send(msg.as_bytes());
println!("send: {}", msg);
let mut buf = [0u8; 512];
socket.recv(&mut buf);
println!("recv: {}", String::from_utf8_lossy(&buf));
}
Ok(())
}
15. 消息中间件
https://github.com/nkbai/learnrustbynats
TODO
16. 游戏开发
https://www.yuque.com/quaint/rust/ldnc5g TODO
17. 爬虫
Hyper :一个快速和正确的 Rust HTTP实现。 https://github.com/hyperium/hyper reqwest : rust http client实现 https://github.com/seanmonstar/reqwest html5ever:Rust html解析库 https://github.com/servo/html5ever select :基于html5ever 的html解析库,类似于python的 beautifulsoap https://github.com/utkarshkukreti/select.rs crates.io https://crates.io/crates/select 附:https://github.com/carllerche/curl-rust
18. rpc 框架
https://zhuanlan.zhihu.com/p/36528189
19. 编写代理
https://github.com/gwuhaolin/blog/issues/12 https://github.com/importcjj/rust-miniproxy https://github.com/wangyuntao/socks5-rs https://github.com/importcjj/gkd-rs
https://zhuanlan.zhihu.com/p/28645724 https://www.jianshu.com/p/d1048d0b687f https://doc.rust-lang.org/std/net/ https://zhuanlan.zhihu.com/p/97200083 https://www.mojidong.com/post/2015-03-07-socket5-1/ https://www.zhihu.com/search?type=content&q=rust%20socket
TODO
https://lowlvl.org/ 使用 rust 学习 tcp
https://github.com/shadowsocks/shadowsocks-rust https://github.com/trojan-gfw/trojan https://github.com/p4gefau1t/trojan-r https://github.com/importcjj/rust-miniproxy
19.1. http 代理
http 代理: 基于 HTTP 协议. 属于应用层协议,一般只会代理转发 HTTP 请求,当然也可以使用 CONNECT 方法来实现一般 TCP 的代理转发 https://github.com/linmx0130/rust-http-proxy
19.2. socket 代理
Socket是一套标准,它完成了对TCP/IP的高度封装; Socket = IP地址 + 端口 + 协议。
socket5代理: socket5 是一个tcp、udp的代理协议(socket4不支持udp), 传输层代理协议, 它直接通过协议握手来进行连接,并直接修改报头来实现转发,所以速度非常快,大部分软件都支持socket5代理。
https://github.com/importcjj https://github.com/zhboner/realm 流量转发 https://cloud.tencent.com/developer/article/1484318 https://github.com/gwuhaolin/blog/issues/12
20. 开发微信小程序-web 游戏
21. 第三方 crates
https://crates.io/ https://s0docs0rs.icopy.site/
https://rust-lang-nursery.github.io/rust-cookbook/
https://github.com/crate-ci/typos 拼写检查
21.1. 事实上的标准库
clap
serde
reqwest http client
hyper 快速HTTP实现 , 经常使用Actix而不是Hyper
rayon 数据并行
slog and log
itertools
PyO3 包装 rust lib 在 Python 中使用 (https://github.com/ijl/orjson, https://github.com/mre/hyperjson)
proptest 基于属性的测试库
libloading 将Go或其他c-lib库混合到Rust前端
regex 正则
21.2. markdown
https://github.com/raphlinus/pulldown-cmark 简单
https://github.com/kivikakk/comrak 复杂, 强大
https://github.com/wooorm/markdown-rs
21.3. 桌面开发
https://github.com/tauri-apps/tauri
https://github.com/oscartbeaumont/tauri-specta
21.4. 视频处理
https://github.com/larksuite/rsmpeg 飞书团队出品 ffmpeg 的 rust binding
https://github.com/gyroflow/gyroflow 视频防抖
21.5. 图片处理
https://github.com/Aloxaf/silicon
21.6. 游戏开发三方库
https://github.com/rust-gamedev/arewegameyet
bevy
21.7. 系统信息
https://github.com/GuillaumeGomez/sysinfo
21.8. web 开发
21.8.1. swagger openapi 生成
https://github.com/GREsau/okapi
21.8.2. web框架
https://github.com/leptos-rs/leptos 类似 react
https://hardocs.com/d/rustprimer/quickstart/quickstart.html
rocket https://rocket.rs/
https://github.com/actix/actix-web
tiny_http
warp
https://github.com/yewstack/yew 使用 jsx 语法写 wasm
对比选型 http://jiagoushi.pro/book/export/html/334
Zola 静态网站
i18n
https://github.com/unicode-org/icu4x 可用于资源受限的系统
21.8.3. orm
Diesel ORM
21.8.4. http client
http - HTTP标准相关的基础类型,如Request<T> 、Response<T>以及StatusCode和常用的Header
hyper - HTTP底层库,它封装了HTTP的报文解析、报文编码处理、连接控制
21.9. 序列化反序列化
21.9.1. toml
use std::env::args;
fn main() {
let config = {
let config_path = args().nth(1).unwrap();
let content = std::fs::read_to_string(config_path).unwrap();
content.parse::<toml::Value>().unwrap()
};
println!("{:#?}", config);
// let tbl = config.as_table().unwrap();
let input = config.get("input").unwrap();
println!("{:#?}", input);
let json_file = input.get("json_file").unwrap().as_str().unwrap();
println!("{:#?}", json_file);
}
21.9.2. json
serde_json 是基于 serde 实现的
21.10. 读写数据
bytes
21.11. 增强工具
itertools
time
21.12. 授权 Authorization
oso
21.13. 日志系统
日志 https://segmentfault.com/a/1190000021681959
log 提供 api, 如果只是开发一个 lib , 无需导入实现, 如果是在一个可执行程序里, 必须有实现才能打印
具体实现有多种
21.13.1. tracing
日志 追踪
21.13.2. env_logger
RUST_LOG=info ./bin_file
#[macro_use]
extern crate log;
fn main() {
env_logger::init();
debug!("debug");
info!("info");
warn!("warn");
trace!("trace");
error!("error"); // default
}
21.13.3. log4rs and log
[dependencies]
log = "0.4.11"
log4rs = "0.13.0"
log4rs.yml
refresh_rate: 30 seconds
appenders:
stdout:
kind: console
requests:
kind: file
path: "log/requests.log" # 相对于项目根目录
encoder:
pattern: "{d} - {m}{n}"
root:
level: debug
appenders:
- stdout
- requests
#loggers:
# app::backend::db:
# level: info
# app::requests:
# level: info
# appenders:
# - requests
# additive: false
fn main() {
let log_file = "config/log4rs.yml"; // 相对于 项目根目录
log4rs::init_file(log_file, Default::default()).unwrap();
debug!(">>> load log config file: {}", log_file);
let listener = TcpListener::bind("127.0.0.1:8090").unwrap();
info!("visit ==> http://127.0.0.1:8090");
}
21.14. 文本解析器 parser
https://github.com/Geal/nom https://zhuanlan.zhihu.com/p/115017849
pest
pom
21.15. lazy static 延迟初始化
可以把定义全局静态变量延迟到运行时,而非编译时
在运行时初始化静态变量, 即静态变量延迟初始化
例如, 某些静态变量由命令行参数决定, 得等到运行时才能确定静态变量
use std::collections::HashMap;
use lazy_static::lazy_static;
// or
// #[macro_use]
// extern crate lazy_static;
lazy_static! {
static ref HASH_MAP: HashMap<u32, &'static str> = {
let mut m = HashMap::new();
m.insert(1, "hello");
m.insert(2, "world");
println!("hash map init");
m
};
}
fn main() {
println!("{}", HASH_MAP.get(&1).unwrap());
print!("{}", HASH_MAP.get(&2).unwrap());
}
21.16. 电子书
mdBook 生成电子书
21.17. 命令行程序
indicatif 进度条
clap 命令行参数解析
借助第三方解析库:
https://rust-cli.github.io/book/tutorial/cli-args.html http://llever.com/cli-wg-zh/tutorial/cli-args.zh.html
ansi_term 彩色输出
https://github.com/fdehau/tui-rs
https://github.com/cjbassi/ytop 命令行系统监控程序
21.17.1. structopt
整合 clap, 将参数直接解析为 struct, 更加方便
use std::path::PathBuf;
use structopt::StructOpt;
#[derive(StructOpt, Debug)]
#[structopt(name = "basic")]
struct Opt {
// 不指定 short long, 会使用 field name
#[structopt(short = "v", long)]
verbose: bool,
#[structopt(short = "r", long = "result", parse(from_os_str))]
result: PathBuf,
#[structopt(parse(from_os_str))]
files: Vec<PathBuf>,
}
fn main() {
// result this cmd: cargo run input.txt input2.txt -v --result res.xy
let opt = Opt::from_args();
println!("{:#?}", opt);
}
21.17.2. clap
功能强大, 使用不够简单
21.18. 异步编程
tokio
21.19. websocket
https://github.com/websockets-rs/rust-websocket
wsl 中可能 build 失败, 如下解决:
apt install -y openssl
apt install -y libssl-dev
apt install -y pkg-config
21.20. 缩小体积
cargo-bloat
21.21. http client
chttp
21.22. 容错运行时
bastion
21.23. 监控
sentry 错误监控
21.24. 电子邮件
tera
21.25. 分发工具
Cargo-release
21.26. 并发编程
https://github.com/crossbeam-rs/crossbeam
Rayon 并行流
dashmap
parking_lot
crossbeam
flume
rsRust
21.27. gui 图形库
https://github.com/PistonDevelopers/conrod 2d
https://github.com/DioxusLabs/dioxus Fullstack GUI library for desktop, web, mobile, and more.
可视化库
https://github.com/yuankunzhang/charming 类似 echarts
21.28. 底层网络 api
libpnet, 如 pnet = "0.25.0"
21.29. 正则
- regex 官方实现, 不支持环视 ( look-around ) 和 反向引用 ( backreference)
- fancy-regex , 支持 支持环视 ( look-around ) 和 反向引用 ( backreference)
21.30. 随机
21.30.1. rand 随机数字
use rand::prelude::*;
fn main() {
let mut rng = rand::thread_rng();
let i = rng.gen_range(0..3); // 0/1/2
println!("{}", i);
// error
// let s: &str = rng.gen();
let boo = rng.gen::<bool>();
println!("bool true from gen() : {}", boo);
let rate = rng.gen_ratio(1, 2);
if rng.gen_bool(1.0 / 2.0) {
println!("percent of true");
}
if rng.gen() {
println!("bool from gen() without turbofish");
}
if rand::random() {
println!("rand bool from random()");
}
}
21.31. 搜索引擎
https://github.com/valeriansaliou/sonic https://github.com/tantivy-search/tantivy https://artem.krylysov.com/blog/2020/07/28/lets-build-a-full-text-search-engine/ 实现原理
21.32. 开源集合容器
https://github.com/jonhoo/flurry A port of Java's ConcurrentHashMap to Rust
其他语言引擎
https://github.com/boa-dev/boa js JavaScript 引擎
https://github.com/RustPython/RustPython python 引擎
22. 开源项目
https://zhuanlan.zhihu.com/p/62325234 https://zhuanlan.zhihu.com/p/139180791 https://www.zhihu.com/question/30511494
23. 参考链接
https://github.com/johnthagen/min-sized-rust 减少 缩小二进制包体积
https://fasterthanli.me/articles/a-half-hour-to-learn-rust
libp2p
是用于构建P2P网络的模块化网络堆栈和库,源自开源项目IPFS,模块化设计使它能够用来构建各种去中心化应用的P2P网络层。目前,知名区块链项目Ethereum 2.0、Pokdot、BitXHub都选择基于Libp2p库搭建系统网络层。
https://github.com/WumaCoder/rust-boom
https://github.com/rustlang-cn/rusty-book 开源库
https://github.com/search?q=algorithm+language%3ARust&type=Repositories&ref=advsearch&l=Rust&l= 算法
https://github.com/rust-unofficial/patterns 规范
https://github.com/lapce/lapce 编辑器, ui
https://github.com/develon2015/dnsd https://github.com/develon2015/remote_bind https://github.com/ppbl/scicode yew+actix
https://github.com/bitlabx/cherry orm
https://github.com/mini-lust/tutorials 手把手动手实现 rpc
https://rust-cli.github.io/book/index.html 命令行
https://github.com/wisespace-io/binance-rs
https://www.youtube.com/watch?v=qyRIkcdRfRg&t=974s 企业级开发最佳实践 https://www.youtube.com/watch?v=36_TiWriqQ4 rust and webasembly
https://course.rs/about-book.html
https://github.com/sunface/rust-course
https://github.com/sunface/rust-course
https://github.com/0voice/Understanding_in_Rust
https://github.com/KernelErr/awesome-rust-zh https://github.com/studyrs/fancy-rust https://github.com/TaKO8Ki/awesome-alternatives-in-rust
https://github.com/pingcap/talent-plan 课程 https://github.com/google/comprehensive-rust
https://github.com/meilisearch/MeiliSearch 搜索引擎, 类似 algolia, 不过是开源的
https://docs.rs/ cates api 文档 https://crates.io/ crates 搜索
https://github.com/pretzelhammer/rust-blog
https://github.com/rust-embedded/rust-raspberrypi-OS-tutorials 在树莓派上实现操作系统
https://github.com/mre/idiomatic-rust 最佳实践 https://github.com/ctjhoa/rust-learning
https://github.com/sassman/t-rec-rs 终端记录工具 录制 gif
https://github.com/wtklbm/crm 简单项目 镜像源切换
https://github.com/rust-embedded/rust-raspberrypi-OS-tutorials 嵌入式 os 内核 开发
https://folyd.com/blog/ Rust的Pin与Unpin
https://github.com/ajmwagar rust 小项目 https://github.com/kilerd https://github.com/ramsayleung
https://github.com/warycat/rustgym 算法 https://github.com/aylei/leetcode-rust 算法实现 https://github.com/sunface/rust-algos https://github.com/dxx/datastructure-algorithm
https://github.com/rust-unofficial/awesome-rust https://github.com/rust-lang-nursery/rust-cookbook
https://play.integer32.com/ https://play.rust-lang.org/
https://rust-unofficial.github.io/patterns/ 设计模式
https://www.rust-lang.org/ 官方站
https://www.zhihu.com/question/31038569 如何学
https://users.rust-lang.org/ 社区 https://rustcc.cn/ 中文社区
https://doc.rust-lang.org/std/ std api
https://doc.rust-lang.org/book/ch04-01-what-is-ownership.html the book 手册 https://kaisery.github.io/trpl-zh-cn/title-page.html the book 翻译 https://course.rs/into-rust.html https://rust-by-example.budshome.com/
https://github.com/rust-lang/nomicon 死灵书 设计原理
https://doc.rust-lang.org/stable/reference/introduction.html
https://doc.rust-lang.org/stable/rust-by-example/macros/dsl.html example https://books.budshome.com/rust-by-example/testing/unit_testing.html 中文
https://rust-unofficial.github.io/too-many-lists/ another tutorial https://github.com/rust-unofficial/too-many-lists
https://cheats.rs/#data-structures 速查表 cheatsheet
https://doc.rust-lang.org/cargo/index.html cargo book https://cargo.budshome.com/index.html
https://github.com/chinanf-boy?tab=stars - 爱好者 https://github.com/AurevoirXavier - 爱好者 https://github.com/BurntSushi - master https://github.com/mre master https://github.com/rust-lang 官方GitHub
http://intorust.com/ 动画介绍
https://zhuanlan.zhihu.com/c_208092758/ 知乎专栏 https://zhuanlan.zhihu.com/c_118514498
https://github.com/phil-opp/blog_os rust 实现os
https://github.com/Kilerd/resource - 中文资料收集 https://zhuanlan.zhihu.com/rust-lang https://wiki.jikexueyuan.com/project/rust-primer/concurrency-parallel-thread/thread.html
https://www.zhihu.com/question/382172347/answer/1103525234 tips https://www.zhihu.com/question/393796866/answer/1213171124
https://www.zhihu.com/question/30407715/answer/48032883
https://www.zhihu.com/question/34665842?sort=created 练手 https://www.zhihu.com/question/352420716/answer/973279231
https://www.zhihu.com/question/30511494/answer/649921526 值得关注
https://github.com/rajasekarv/vega spark 替代