TCP IP, p2p
https://github.com/isno/theByteBook
https://iximiuz.com/en/posts/computer-networking-101/
http://c.biancheng.net/tcp_ip/ https://coolshell.cn/articles/11564.html http://www.tcpipguide.com/ https://www.lanqiao.cn/courses/98 结合WireShark (https://www.wireshark.org/) 或者 tcpdump 边看边抓包. 推荐书目《WireShark 数据包分析实战》、《TCP/IP详解 卷一》 谢希仁教授的《计算机网络》 TODO
- 1. 物理层(physical-layer)
- 2. 数据链路层(data-link-layer 或者 mac layer)
- 3. 网络层(network-layer 或者 ip 层)
- 4. 传输层(transport-layer)
- 5. 应用层(application-layer)
- 6. 入门
- p2p
1. 物理层(physical-layer)
网线, 电磁信号... 通过电信号传输 0 1
早些年, 电脑连电脑啊,还是电脑连网口用的网线不同;
电脑连电脑。这种方式就是一根网线,有两个头。一头插在一台电脑的网卡上,另一头插在另一台电脑的网卡上。但是在当时,普通的网线这样是通不了的,所以水晶头要做交叉线,用的就是所谓的1-3、2-6交叉接法: 水晶头的第1、2和第3、6脚,它们分别起着收、发信号的作用。将一端的1号和3号线、2号和6号线互换一下位置,就能够在物理层实现一端发送的信号,另一端能收到 除了网线要交叉,还需要配置这两台电脑的IP地址、子网掩码和默认网关, 可以一个是192.168.0.1/24,另一个是192.168.0.2/24
多台机器互联:
集线器(hub, 没有大脑,它完全在物理层工作。它会将自己收到的每一个字节,都复制到其他端口上去),
交换机(Switch, 在 mac 层工作, 会记住每个口对应机器的 mac 地址, 转发包时, 能把MAC头拿下来,检查一下目标MAC地址, 如果目标MAC地址不是这台电脑的,这个口就不用转发了)
交换机怎么知道每个口的电脑的MAC地址呢?这需要交换机会学习 一台MAC1电脑将一个包发送给另一台MAC2电脑,当这个包到达交换机的时候,一开始交换机也不知道MAC2的电脑在哪个口,所以没办法,它只能将包转发给除了来的那个口之外的其他所有的口。但是,这个时候,交换机会干一件非常聪明的事情,就是交换机会记住,MAC1是来自一个明确的口。以后有包的目的地址是MAC1的,直接发送到这个口就可以了 过了一段时间之后,就有了整个网络的一个结构了,这个时候,基本上不用广播了,全部可以准确转发。当然,每个机器的IP地址会变,所在的口也会变,因而交换机上的学习的结果,我们称为转发表,是有一个过期时间的
2. 数据链路层(data-link-layer 或者 mac layer)
ARP, VLAN, STP 协议
数据包的定义, 网卡mac地址, broadcasting ------- 现在可以在数据链路层输出数据了
考虑三个问题:
- 数据包的发送方, 接收方如何确定 --- mac地址
- 包发送先后顺序, 如何防止堵车混乱 --- 信道划分协议, 轮流协议, 随机接入协议
- 如何处理发送中的错误 - CRC 循环冗余检测
2.1. mac 和 mac地址
Medium Access Control,即媒体访问控制, 其实就是控制在往媒体上发数据的时候,谁先发、谁后发的问题。防止发生混乱, 这个规则叫做 多路访问
三种方式解决混乱问题:
方式一:分多个车道。每个车一个车道,你走你的,我走我的。这在计算机网络里叫作信道划分;
方式二:今天单号出行,明天双号出行,轮着来。这在计算机网络里叫作轮流协议;
方式三:不管三七二十一,有事儿先出门,发现特堵,就回去。错过高峰再出。我们叫作随机接入协议。著名的以太网,用的就是这个方式。
MAC地址: 每个物理设备(网卡)都有的唯一标识, 48二进制位, 通过12个十六进制数表示;只和厂商有关; 解决发给谁,谁接收的问题;
MAC地址的通信范围比较小,局限在一个子网里面。例如,从192.168.0.2/24访问192.168.0.3/24是可以用MAC地址的。一旦跨子网,即从192.168.0.2/24到192.168.1.2/24,MAC地址就不行了,需要IP地址起作用了
为什么有了 mac 地址, 还会发明 ip 地址呢
mac 地址本身无法在网络中定位: 因为MAC地址虽然唯一但是本身就是一串随机字符串, 不能表明用户在整个互联网中的位置,除非维护一个超级大MAC地址对应表,那寻址效率肯定爆炸; 而 IP地址是网络提供商给你的,所以你在哪个局域网整个网络都是知道的.
mac 地址安全性问题: 获取MAC地址是通过ARP协议来完成的,如果只用MAC地址通信,那么广播风暴是个难题
为什么有了 ip 地址还要 mac 地址?
局域网中机器的 ip 都是变化的, 这时就需要mac地址来唯一对应一台机器
2.2. mac 层数据包格式
对于以太网,第二层的最开始,就是目标的MAC地址和源的MAC地址:
target mac address 6 byte
有了这个目标MAC地址,数据包在链路上广播,MAC的网卡才能发现,这个包是给它的。MAC的网卡把包收进来,然后打开IP包,发现IP地址也是自己的,再打开TCP包,发现端口是自己,也就是80,而nginx就是监听80
nginx返回一个网页。然后将网页需要发回请求的机器。然后层层封装,最后到MAC层。因为来的时候有源MAC地址,返回的时候,源MAC就变成了目标MAC,再返给请求的机器
source mac address 6byte
类型 2byte
类型 0800 : ip 数据报 (大部分的类型是IP数据包,然后IP里面包含TCP、UDP,以及HTTP等)
类型 0806: ARP 请求, 应答
数据 46 ~ 1500 byte
CRC 4 byte (循环冗余检测)
通过XOR异或的算法,来计算整个包是否在发送的过程中出现了错误,主要解决第三个问题。
2.3. ARP 协议
ARP协议,也就是已知IP地址,求MAC地址的协议, 通过广播的方式来寻找目标MAC地址,拿到后记住一段时间,这个叫作缓存;
RARP协议,即已知MAC求IP的协议
机器 a 访问机器 b 过程:
a 根据 b 的 ip 查看本地 ARP缓存表, 没找到 mac
广播 ARP请求, "谁是 192.168.0.2 ? 你的 mac 是多少"
b ARP 应答 "我就是 192.168.0.2, 我的 mac 是 xxx"
a 缓存 ip-mac 映射表
两台机器互联可以使用 hub, 多台机器使用有学习功能的 switch
2.3.1. 解决环路问题(广播风暴) stp 协议
随着网络中 switch 越来越多, 出现环路问题 and 广播风暴
如果一个局域网里面有多个交换机, 或者 2 个局域网有多个 switch 连接,ARP广播的模式有广播风暴的问题 比如数据包经过交换机A到达交换机B,交换机B又将包复制为多份广播出去, 如果整个局域网存在一个环路,使得数据包又重新回到了最开始的交换机A,这个包又会被A再次复制多份广播出去。如此循环,数据包会不停得转发,而且越来越多,最终占满带宽,或者使解析协议的硬件过载,形成广播风暴
那么如何破除环路呢? stp 协议: 数据结构中, 有环的我们常称为图。将图中的环破了,就生成了树。在计算机网络中,生成树的算法叫作STP,全称Spanning Tree Protocol。
stp 缺点:
- STP 对于跨地域甚至跨国组织的网络支持,就很难做了,计算量摆着呢
- 某个交换机状态发生变化的时候,整个树需要重新构建
- 被破开的环的链路被浪费了
所以现在很少用了
2.3.2. 网络隔离
随着 switch 变多, 也需要进行网络隔离, 这是因为当一个局域网中有各种各样的数据包, 混合在一起, 无法保证安全性
物理隔离: 组件多个子网, 通过路由器连接
虚拟隔离: VLAN,或者叫虚拟局域网
一个交换机上会连属于多个虚拟局域网的机器
那交换机怎么区分哪个机器属于哪个局域网呢?在原来的二层的头上加一个TAG,里面有一个VLAN ID,一共12位; 当这个交换机把二层的头取下来的时候,就能够识别这个VLAN ID。这样只有相同VLAN的包,才会互相转发,不同VLAN的包,是看不到的。这样广播问题和安全问题就都能够解决了
交换机之间怎么连接呢?将两个交换机连接起来的口应该设置成什么VLAN呢?对于支持VLAN的交换机,有一种口叫作Trunk口。它可以转发属于任何VLAN的口。交换机之间可以通过这种口相互连接
2.4. 两台机器不通
ping + traceroute/wireshark
3. 网络层(network-layer 或者 ip 层)
ICMP, ip, arp, ospf, bgp, IPSec, GRE
定义主机到主机的通信规范, 例如 ip协议, 将运输层产生的报文段or用户数据报封装成ip数据报
引入新的地址: 网址(ip地址) ------------ 确定机器所在的子网 (mac地址确定这个子网中的具体哪一台机器)
3.1. ip 地址
4 * 8 bit ; 习惯用 4段 十进制数字表示
分为 "网络段" + "主机段", 子网掩码来决定怎么分段, 同一子网的主机 网络段相同;
无类型域间选路(CIDR): 表示法, 10.100.122.2/24,这个IP地址中有一个斜杠,斜杠后面有个数字24。这种地址表示形式,就是CIDR。后面24的意思是,32位中,前24位是网络号,后8位是主机号
广播地址: 10.100.122.255。如果发送这个地址,所有10.100.122网络里面的机器都可以收到
子网掩码: 写法类似ip地址, 32bit, 网络段"全部是1", 主机段"全部是0", 例如 255.255.255.0; 判断两个ip地址是否处于同一个子网 - 将2个ip分别和各自的子网掩码做"and"运算, 然后看看是否相等
ip地址分类: 分成了5类。C类太少,B类太多。C类254个,网络都不够;D类6万多,给企业都太多;
如何弥补IP设计者犯的错误: CIDR 10.100.122.2/24
D 类是组播地址。使用这一类地址,属于某个组的机器都能收到
公有 ip, 私有 ip: A类、B类或者C类 ip 地址中, 都有私有 ip 地址段, 供局域网内部使用, 如 192.168.0.x, 家庭网设备不会超过256个,所以/24基本就够了
而整个网络里面的第一个地址192.168.0.1,往往就是你这个私有网络的出口地址; Wi-Fi路由器的地址就是192.168.0.1,而192.168.0.255就是广播地址
ipv6: 32位地址不够用。于是有了现在IPv6(128位)
根据ip协议发送的数据 叫做 ip数据包 ------ 存储在 以太网数据包(frame)中的 "data(数据)" 部分; 最大容量 65535 byte
head - 版本号, 长度, ip地址; 20 ~ 60 byte
data - ip数据包的具体内容; 最大容量: 65535-20 = 65515byte
3.1.1. 查询 IP地址
ifconfig, ipconfig, ip addr
scope: 在IP地址的后面有个scope,对于eth0这张网卡来讲,是global,说明这张网卡是可以对外的,可以接收来自各个地方的包。对于lo来讲,lo全称是loopback,又称环回接口,往往会被分配到127.0.0.1这个地址。这个地址用于本机通信,经过内核处理后直接返回,不会在任何网络中出现
网络设备的状态标识:
<BROADCAST,MULTICAST,UP,LOWER_UP>;UP表示网卡处于启动的状态;
BROADCAST表示这个网卡有广播地址,可以发送广播包;
MULTICAST表示网卡可以发送多播包;
LOWER_UP表示L1是启动的,也即网线插着呢,
MTU1500 最大传输单元MTU为1500,这是以太网的默认值, MTU是二层MAC层的概念, 以太网规定连MAC头带正文合起来,不允许超过1500个字节。正文里面有IP的头、TCP的头、HTTP的头。如果放不下,就需要分片来传输; MTU 大小是不包含二层头部和尾部的,MTU 1500表示二层MAC帧大小不超过1518. MAC 头14 字节,尾4字节
qdisc pfifo_fast : 排队规则。规定数据包如何进出的。有pfifo, pfifo_fast
ifconfig 属于 net-tools, ip addr 属于iproute2 net-tools起源于BSD,自2001年起,Linux社区已经对其停止维护,而iproute2旨在取代net-tools,并提供了一些新功能。一些Linux发行版已经停止支持net-tools,只支持iproute2。 net-tools通过procfs(/proc)和ioctl系统调用去访问和改变内核网络配置,而iproute2则通过netlink套接字接口与内核通讯。 net-tools中工具的名字比较杂乱,而iproute2则相对整齐和直观,基本是ip命令加后面的子命令。 虽然取代意图很明显,但是这么多年过去了,net-tool依然还在被广泛使用
3.1.2. 手动配置 ip 地址
配置 ip 地址: sudo ifconfig eth1 10.0.0.1/24 && sudo ifconfig eth1 up or sudo ip addr add 10.0.0.1/24 dev eth1 && sudo ip link set up eth1
真正配置的时候,一定不是直接用命令配置的,而是放在一个配置文件里面。不同系统的配置文件格式不同,但是无非就是CIDR、子网掩码、广播地址和网关地址
ip 地址不能随便配置, 否则包无法发送出去, 比如 随便配置为 16.158.23.6, 局域网另外机器为 192.168.1.6, 本机 ping192.168.1.6, 不通; 这是发生了什么?
此时数据包 源IP地址16.158.23.6,也有目标IP地址192.168.1.6,但是包发不出去,这是因为MAC层还没填. 源 mac 地址自己知道, 目标 mac 地址却不是192.168.1.6这台机器的MAC地址, 是什么呢 -----Linux首先会判断,要去的这个地址和我是一个网段的吗, 只有是一个网段的,它才会发送ARP请求,获取目标MAC地址, 若不在同个子网, Linux 会通过 ARP 获取网关 mac, 将包发送给网关(若配置了网关), 再通过网关发给另外子网的网关
如果将网关配置为192.168.1.6呢?不可能,Linux不会让你配置成功的,因为网关要和当前的网络至少一个网卡是同一个网段的,怎么可能16.158.23.6的网关是192.168.1.6呢
3.1.3. 动态分配地址 DHCP
动态主机配置协议(Dynamic Host Configuration Protocol),简称DHCP。
只需要配置一段共享的IP地址。每一台新接入的机器都通过DHCP协议,来这个共享的IP地址里申请,然后自动配置好就可以了。等人走了,或者用完了,还回去,这样其他的机器也能用
工作过程:
- DHCP Discover: 新来的机器使用IP地址0.0.0.0发送了一个广播包,目的IP地址为255.255.255.255 (广播包封装了UDP,UDP封装了BOOTP协议)数据包结构:
mac header: 新人 mac (xxx), 广播 mac(ff:ff:ff:ff:ff:ff)
ip header: 新人 ip (未知 0.0.0.0), 广播 ip(255.255.255.255)
udp header: 源端口(68), 目标端口(67)
bootP header: boot request
实际数据: 我的 mac 是 xxx, 还没有 IP地址
- DHCP Offer: 如果一个网络中配置了DHCP Server , 这个 server 挑选一个闲置 ip, 也发送广播包: (如果有多个DHCP Server,这台新机器会收到多个IP地址)
mac header: DHCP server mac (xxx), 广播 mac(ff:ff:ff:ff:ff:ff)
ip header: DHCP server ip (192.168.1.2), 广播 ip(255.255.255.255)
udp header: 源端口(67), 目标端口(68)
bootP header: boot reply
实际数据: 我知道了你的 mac, 分配给你的 ip 是 xxx, 请答复
- DHCP request: 新机器发送广播包答复准备使用哪个 ip
mac header: 新人 mac (xxx), 广播 mac(ff:ff:ff:ff:ff:ff)
ip header: 新人 ip (未知 0.0.0.0), 广播 ip(255.255.255.255)
udp header: 源端口(68), 目标端口(67)
bootP header: boot request
实际数据: 我的 mac 是 xxx, 我准备租用这个 server 给的 ip 了, ip 是 xxx, 其他 ip 都不要了
- DHCP ACK: server 广播确认消息
mac header: DHCP server mac (xxx), 广播 mac(ff:ff:ff:ff:ff:ff)
ip header: DHCP server ip (192.168.1.2), 广播 ip(255.255.255.255)
udp header: 源端口(67), 目标端口(68)
bootP header: boot reply
实际数据: 这个新人的 ip 是我租给他的, 租约如下
ip 地址回收和续租: 客户机会在租期过去50%的时候,直接向为其提供IP地址的DHCP Server发送DHCP request消息包。客户机接收到该服务器回应的DHCP ACK消息包,会根据包中所提供的新的租期以及其他已经更新的TCP/IP参数,更新自己的配置
预启动执行环境(PXE):管理多个主机, 安装操作系统 (DHCP协议能给客户推荐“装修队”PXE,能够安装操作系统,这个在云计算领域大有用处)
3.2. ping 原理 ICMP协议
ping是基于ICMP协议工作的。ICMP全称Internet Control Message Protocol,就是互联网控制报文协议
ICMP报文是封装在IP包里面的。因为传输指令的时候,肯定需要源地址和目标地址.
分类如下:
查询报文: 主动发起的查询, 例如,常用的ping就是查询报文,是一种主动请求,并且获得主动应答的ICMP协议
差错报文: 异常情况发起的,来报告发生了不好的事情, 如 Traceroute 就是使用的差错报文
数据结构是这样的:
- ICMP 报文内容 (如 类型, 序号)
- source ip, target ip
- source mac, target mac
3.3. 路由器作为网关
路由器工作在这层, 所以是三层设备;
网关往往是一个路由器,是一个三层转发的设备, 就是把MAC头和IP头都取下来,然后根据里面的内容,看看接下来把包往哪里转发的设备
两台机器互联:
如果是同一个网段,例如,你访问你旁边的兄弟的电脑,那就没网关什么事情,直接将源地址和目标地址放入IP头中,然后通过ARP获得MAC地址,将源MAC和目的MAC放入MAC头中,发出去就可以了
如果不是同一网段,分两种网关:
转发网关, 不改变数据包IP地址. 例如,你要访问你们校园网里面的BBS(192.168.4.0/24), 假设经历了路由器 A, B, 首先需要发往默认网关 A, 将源地址和目标IP地址放入IP头中,通过ARP获得网关的MAC地址,将源MAC和网关的MAC放入MAC头中,发送出去。网关A所在的端口,例如192.168.1.1/24 发现 mac 地址符合, 将网络包收进来,查看A配置的静态路由, 要想访问192.168.4.0/24,要从192.168.56.1这个口出去,下一跳为192.168.56.2(即 B 的入口), 路由器A发送ARP获取B 的MAC地址,然后发送包, 包到达B 的192.168.56.2这个网口,发现MAC一致,将包收进来
NAT 网关 (Network Address Translation, 常见), 改变IP地址. 如 机器 x, y 都有局域网 ip 192.168.0.101/24, 两者通信, 需要网关在发出接受数据包时, 转换 ip 地址为公网 ip 地址. 否则就冲突了
人们把网关就叫作路由器。其实不完全准确,而另一种比喻更加恰当:路由器是一台设备,它有五个网口或者网卡,相当于有五只手,分别连着五个局域网。每只手的IP地址都和对应局域网的IP地址处在相同的网段,每只手都是它握住的那个局域网的网关; 想发往其他局域网的包,都会到达其中一只手,被拿进来,拿下MAC头和IP头,看看,根据自己的路由算法,选择另一只手,加上IP头和MAC头,然后扔出去。
数据包跨过网关, mac 都会变, ip 地址则不一定变
静态路由: 其实就是在路由器上,配置一条一条规则, 每一条规则至少包含这三项信息:
目的网络:这个包想去哪儿?
出口设备:将包从哪个口扔出去?
下一跳网关:下一个路由器的地址
通过route命令和ip route命令配置, 例如,我们设置ip route add 10.176.48.0/20 via 10.173.32.1 dev eth0,就说明要去10.176.48.0/20这个目标网络,要从eth0端口出去,经过10.173.32.1。还能配置复杂的策略路由, 实现控制转发策略.
动态路由: 根据路由协议算法生成动态路由表. 动态路由主流算法有两种,距离矢量算法和链路状态算法。基于两种算法产生两种协议,BGP协议和OSPF协议
3.4. nat 网络地址转换
NAT(Network Address Translation,网络地址转换)将IP数据报文头中的IP地址转换为另一个IP地址, nat 服务一般部署在网络出口如路由器/防火墙中
为什么出现? To ease off the lack of ipv4 number To expose services in private network to the public internet
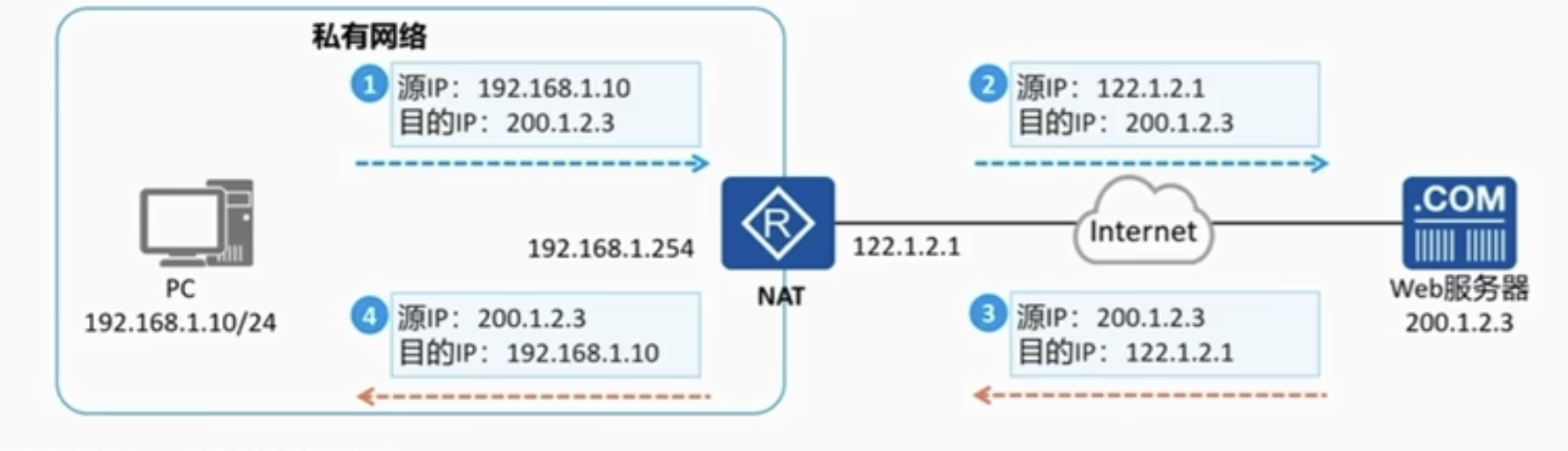
局限性:
NAT违反了IP地址结构模型的设计原则
由于NAT的存在,使得P2P应用实现出现困难,因为P2P的文件共享与语音共享都是建立在IP协议的基础上的
NAT使得IP协议从面向无连接变成面向连接
NAT必须维护专用IP地址与公用IP地址以及端口号的映射关系。
在TCP/IP协议体系中,如果一个路由器出现故障,不会影响到TCP协议的执行。因为只要几秒收不到应答,发送进程就会进入超时重传处理。而当存在NAT时,最初设计的TCP/IP协议过程将发生变化,Internet可能变得非常脆弱。
3.4.1. nat 分类
静态 nat: every single private ip will be mapped to a corresponding public ip, 多用于服务器。 动态 nat: 在外部网络中定义了一个或多个合法地址,采用动态分配的方法映射到内部网络。
or
Basic NAT:只转化IP,不映射端口 PAT: 除了转化IP,还做端口映射,可以用于多个内部地址映射到少量(甚至一个)外部地址
4. 传输层(transport-layer)
transport-layer 定义了不同主机进程间的通信规则, 是通用的, 不同应用有不同的应用层协议,但是都是基于通用的transport-layer协议;
如 tcp, udp, sctp协议
传输控制协议 TCP(Transmission Control Protocol)--提供面向连接的,可靠的数据传输服务。
所谓面向连接, 就是通信双方可以维护一定状态
用户数据协议 UDP(User Datagram Protocol)--提供无连接的,不可靠的数据传输服务
4.1. udp协议
udp数据包内嵌在 ip数据包 的 "data"部分; 总长度最大 65535byte
结构:
head - 包括: send port, receive port; 8byte
data
特点:
- 无连接, 不保证可靠性, 相应的也无需维护负责的连接状态
- 没有拥堵控制 (因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如 直播,实时视频会议等))
- 发送一个一个数据包来传输数据 (基于数据报的,一个一个地发,一个一个地收)
- 支持一对一, 一对多, 多对一,多对多的通信
- UDP 的首部开销小,只有8个字节,比TCP的20个字节的首部要短
使用场景:
需要资源少,在网络情况比较好的内网中使用, 如 DHCP就是基于UDP协议的
不需要一对一沟通,而是可以广播的应用, 如 DHCP就是一种广播
需要处理速度快,时延低,可以容忍少数丢包的场景, 如直播,实时视频会议
QUIC(全称Quick UDP Internet Connections,快速UDP互联网连接)是Google提出的一种基于UDP改进的通信协议
物联网通信协议Thread,就是基于UDP协议的
4.2. tcp协议
顺序问题,丢包问题,连接维护,流量控制(对另一端),拥塞控制(针对网络)
4.2.1. 基本特点
https://hit-alibaba.github.io/interview/basic/network/TCP.html
面向连接, 可以维护通信双方的状态
发送字节流传输数据, 发送的时候发的是一个流,没头没尾
有拥塞控制 (意识到包丢弃了或者网络的环境不好了,就会根据情况调整自己的行为)
有确认机制, 每次发送一个数据包, 都要收到确认才会认为发送成功(不成功就重发)
内嵌在ip数据包的 "data部分"
没有长度限制, 但是为了性能, tcp 包长度不会超过ip数据包长度, 以确保单个tcp包不会被分割
- 必须先建立连接, 可靠(数据不丢失,不重复,有序到达)
- 只能一对一通信
- 面向字节流(“面向字节流”的含义是:虽然应用程序和 TCP 的交互是一次一个数据块(大小不等),但 TCP 把应用程序传下来的数据仅仅看成是一连串的无结构的字节流。)
4.2.2. 三次握手
建立 tcp 连接需要 "三次握手"
图示: online
第一次握手(SYN=1, seq=x):
客户端发送一个 TCP数据包, 包的
SYN标志位为1, 指明客户端打算连接的服务器的端口,以及初始序号X,保存在包头的序列号(Sequence Number)字段里。发送完毕后,客户端进入 SYN_SEND 状态。
第二次握手(SYN=1, ACK=1, seq=y, ACKnum=x+1):
服务器发回确认包, 包含两部分, 一部分是确认client端的连接请求(ACK=1, ACKnum=x+1), 告诉client, server是运行着的, server 确实接受到了 client 的消息; 另一部分是 server 测试能否链接 client (SYN=1, seq=y), 需要等待 client 的响应来确认。即
SYN 标志位和ACK 标志位均为1。服务器端选择自己 ISN 序列号,放到 Seq 域里,同时将确认序号(Acknowledgement Number)设置为客户的 ISN 加1,即X+1。发送完毕后,服务器端进入 SYN_RCVD 状态。
第三次握手(ACK=1,ACKnum=y+1)
客户端再次发送确认包(ACK),SYN 标志位为0 (即不发送),ACK 标志位为1,并且把确认序号设置位服务器发来 ACK 的序号字段+1,
发送完毕后,客户端进入 ESTABLISHED 状态,当服务器端接收到这个包时,也进入 ESTABLISHED 状态,TCP 握手结束。
总结: 一开始,客户端和服务端都处于CLOSED状态。先是服务端主动监听某个端口,处于LISTEN状态。然后客户端主动发起连接SYN,之后处于SYN-SENT状态。服务端收到发起的连接,返回SYN,并且ACK客户端的SYN,之后处于SYN-RCVD状态。客户端收到服务端发送的SYN和ACK之后,发送ACK的ACK,之后处于ESTABLISHED状态,因为它一发一收成功了。服务端收到ACK的ACK之后,处于ESTABLISHED状态,因为它也一发一收了。
为什么两次握手不行?
如果只有两次握手, 可能出现这种错误: 超时的连接请求报文突然成功到达服务端, 服务端成功进入链接建立状态, 而此时客户端已经使用完关闭了, 那么服务端会永远无法关闭.
为什么四次握手不行?
是可以的, 但是耗费资源. 第三次握手后, 客户端会继续发送数据, server 端收到, 这完全可以代替第四次握手.
4.2.3. 四次挥手
断开 tcp 连接需要 "四次挥手"
图示: online
第一次挥手(FIN=1,seq=x)
假设客户端想要关闭连接,客户端发送一个 FIN 标志位为1的包,表示自己已经没有数据可以发送了,但是仍然可以接受数据。
发送完毕后,客户端进入 FIN_WAIT_1 状态。
第二次挥手(ACK=1,ACKnum=x+1)
服务器端确认客户端的 FIN 包,发送一个确认包,表明自己接受到了客户端关闭连接的请求,但还没有准备好关闭连接。
发送完毕后,服务器端进入 CLOSE_WAIT 状态,客户端接收到这个确认包之后,进入 FIN_WAIT_2 状态,等待服务器端关闭连接。
第三次挥手(FIN=1,seq=y)
服务器端准备好关闭连接时,向客户端发送结束连接请求,FIN 置为1。
发送完毕后,服务器端进入 LAST_ACK 状态,等待来自客户端的最后一个ACK。
第四次挥手(ACK=1,ACKnum=y+1)
客户端接收到来自服务器端的关闭请求,发送一个确认包,并进入 TIME_WAIT 状态,等待可能出现的要求重传的 ACK 包。
服务器端接收到这个确认包之后,关闭连接,进入 CLOSED 状态。
客户端等待了某个固定时间(两个最大段生命周期,2MSL,2 Maximum Segment Lifetime)之后,没有收到服务器端的 ACK ,认为服务器端已经正常关闭连接,于是自己也关闭连接,进入 CLOSED 状态。
为什么需要四次挥手?
TCP连接是双向的,因此在四次挥手中,前两次挥手用于断开一个方向的连接,后两次挥手用于断开另一方向的连接
4.2.4. TCP包的序号问题
A要告诉B,我这面发起的包的序号起始是从哪个号开始的,B同样也要告诉A,B发起的包的序号起始是从哪个号开始的。
为什么序号不能都从1开始呢? 因为这样往往会出现冲突。例如,A连上B之后,发送了1、2、3三个包,但是发送3的时候,中间丢了,或者绕路了,于是重新发送,后来A掉线了,重新连上B后,序号又从1开始,然后发送2,但是压根没想发送3,但是上次绕路的那个3又回来了,发给了B,B自然认为,这就是下一个包,于是发生了错误。 因而,每个连接都要有不同的序号。这个序号的起始序号是随着时间变化的,可以看成一个32位的计数器,每4ms加一,如果计算一下,如果到重复,需要4个多小时,那个绕路的包早就死翘翘了
4.3. tcp如何保证可靠传输
- 数据被分割成合适的数据块
- tcp会给每个数据报编号, 接收方接收到后排序;
- 校验和 - tcp将维护首部和数据的校验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段
- TCP 的接收端会丢弃重复的数据。
- 拥塞控制: 当网络拥塞时,减少数据的发送。
- 停止等待协议 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组
- 超时重传: 当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
TCP协议为了保证顺序性,每一个包都有一个ID。在建立连接的时候,会商定起始的ID是什么,然后按照ID一个个发送, 对于发送的包都要进行应答, 这个应答也不是一个一个来的, 而是会应答某个之前的ID,表示都收到了,这种模式称为累计确认或者累计应答(cumulative acknowledgment)。
这就需要发接双方都要维护数据包的缓存, 发送端的缓存里是按照包的ID一个个排列,根据处理的情况分成四个部分:
- 发送了并且已经确认的
- 发送了并且尚未确认的
- 没有发送,但是已经等待发送的
- 没有发送,并且暂时还不会发送的
这里面为什么要区分第三部分和第四部分呢?为了流量控制, 防止拥堵
接收端会给发送端报一个窗口的大小,叫Advertised window。这个窗口的大小应该等于上面的第二部分加上第三部分,就是已经交代了没做完的加上马上要交代的。超过这个窗口的,接收端做不过来,就不能发送了
涉及到三个值:
LastByteAcked:第一部分和第二部分的分界线
LastByteSent:第二部分和第三部分的分界线
LastByteAcked + len(AdvertisedWindow):第三部分和第四部分的分界线
对于接收端来讲,它的缓存里记录的内容:
- 接受并且确认过的
- 还没接收,但是马上就能接收的 (能够接受的最大工作量)
- 还没接收,也没法接收的
涉及到三个值:
MaxRcvBuffer:最大缓存的量;
LastByteRead之后是已经接收了,但是还没被应用层读取的;
NextByteExpected是第一部分和第二部分的分界线
TODO
5. 应用层(application-layer)
application-layer 定义了app进程间的通信规则,专门完成进程间的数据交互, 不同应用有不同的应用层协议
应用层协议包括:DHCP(分配 ip), DNS(域名查询), HTTP/HTTPS(网页访问),SMTP邮件协议, P2p, rpc;
应用层交互的数据单元称为报文。
6. 入门
6.1. 五层模型
- 应用层: (http) 业务数据封装
- 传输层 (tcp)
- 网络层(ip) 远程路由
- 数据链路层(mac) 局域网定位
- 物理层 (网线) 连接
所谓的二层设备、三层设备,都是这些设备上跑的程序不同而已。一个HTTP协议的包经过一个二层设备,二层设备收进去的是整个网络包。这里面HTTP、TCP、 IP、 MAC都有。什么叫二层设备呀,就是只把MAC头摘下来,看看到底是丢弃、转发,还是自己留着。那什么叫三层设备呢?就是把MAC头摘下来之后,再把IP头摘下来,看看到底是丢弃、转发,还是自己留着
6.2. 一次请求涉及到的网络协议
三要素: 语法, 语义, 顺序
- 应用层: 输入 URL, 浏览器通过 DNS/httpdns 查找 到 ip 地址 (假设 本机 host 中没有任何配置), 根据 HTTP/HTTPS 协议, 浏览器打包请求, 交给传输层.
- 传输层: tcp/udp 协议将浏览器监听端口, 目标服务器端口封装, 交给网络层
- 网络层: ip 协议将将本机 ip 和目标 ip 封装. 交给mac 层(数据链路层)
- mac 层: os 通过 ARP 协议以及默认网关 ip 找到本地网关 mac 地址(一般在 os 启动时, os 根据 DHCP协议分配本机 ip 地址, 已经网关地址192.168.1.1). 将本机 mac 地址, 网关 mac 地址封装, 交给网卡, 发给本地网关
- 网关/路由器在不同的局域网间, 通过路由协议,(常用的有OSPF和BGP)沟通
6.3. 数据包结构
Mac头 Ip头 Tcp头 Http头 数据体
- 以太网头部 (mac header) --- 在数据链路层包装/解除
- target mac address 48bit
- source mac address 48bit
- 协议类型 16bit : 用来说明里面是IP协议
- ip header --- 在网络层包装/解除
- 版本 4bit: 目前主流的还是IPv4
- 首部长度 4bit
- 服务类型 TOS (type of service) 8bit: 代表了当前的包是高优先级的,还是低优先级的。
- 总长度 16bit
- 标识 16bit
- 标志 3bit
- 片偏移 13bit
- TTL 8bit
- 协议 8bit: TCP还是UDP
- 首部校验和 16bit
- 源 ip address 32bit
- 目的 ip address 32bit
- 选项
- tcp header --- 传输层包装/解除
- 源 port number
- 目的 port number
- tcp 校验和 (checkSum, 指传输位数的累加,当传输结束时,接收者可以根据这个数值判断是否接到了所有的数据。另外, 防篡改)
- 序号 32bit, 解决乱序问题
- 确认序号 32bit, 确认包收到, 解决丢包的问题
- 实际数据 --- 应用层 (http 数据,ftp 数据...)