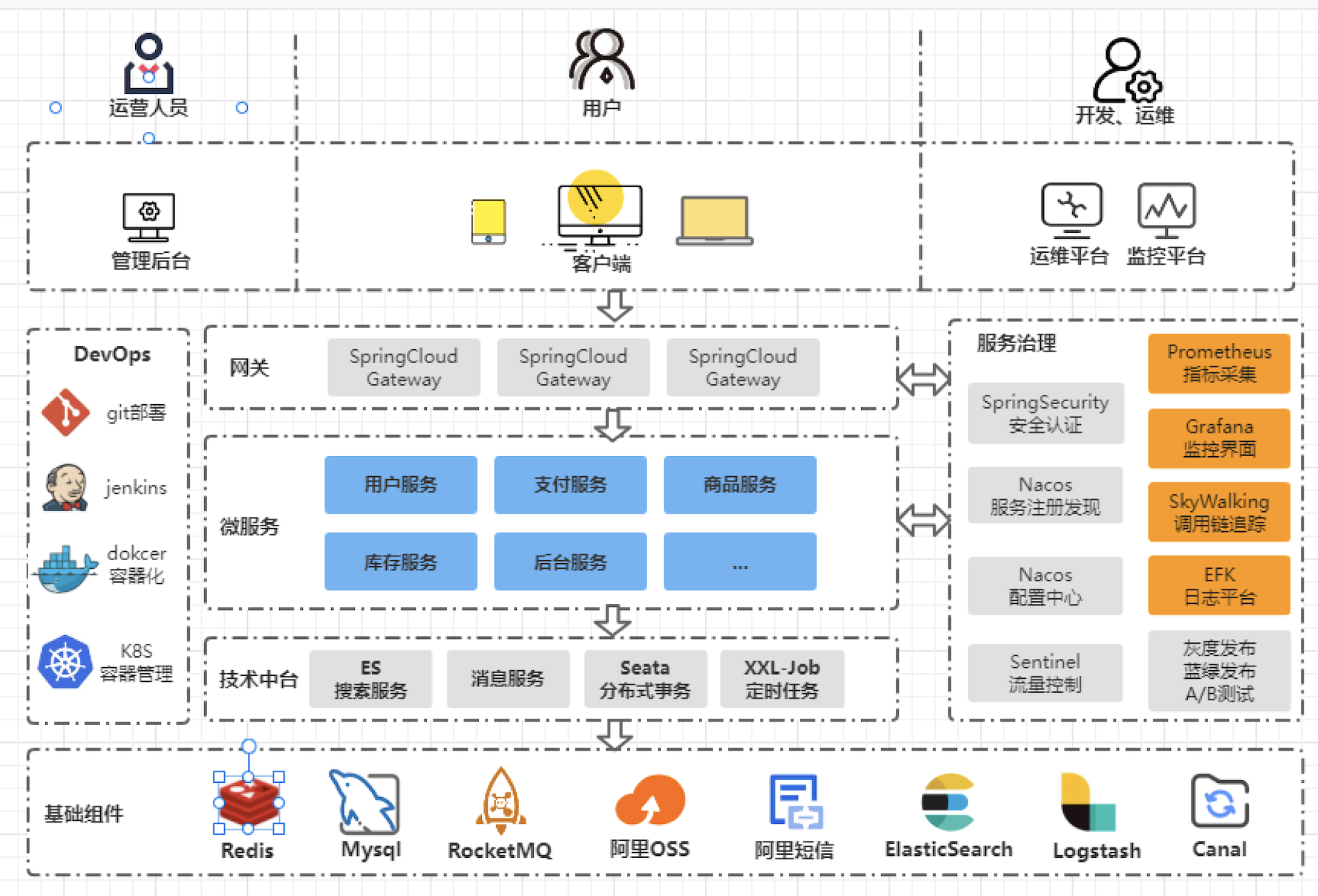
Spring Cloud 笔记🌈
https://github.com/macrozheng/mall-swarm TODO
Spring Cloud是一系列框架的有序集合, 它利用Spring Boot简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等; 官网; 微服务的架构演化 https://www.youtube.com/watch?v=aO3W-lYnw-o (一个入门介绍) demo在这里
spring cloud alibaba: nacos (服务注册, 配置中心, bus), sentinel (熔断限流), seata (分布式事务)
https://juejin.im/post/6870288195674718222 选型 2020
https://github.com/macrozheng 电商系统tutorial
https://github.com/zhoutaoo/SpringCloud demo
https://docshome.gitbook.io/microservices/ 从设计到部署
- 1. 一套微服务平台技术选型
- 2. 微服务核心要素和 spring cloud 工作流程
- 3. 和dubbo-zookeeper对比
- 4. 配置中心
- 5. 注册中心
- 6. 服务相互调用
- 7. 负载均衡
- 8. 熔断器
- 9. 服务网关
- 10. 调用链路追踪
- 11. 业务日志收集
- 12. 运维监控
- 13. 消息总线
- 14. spring-cloud-stream 消息驱动
- 15. spring-cloud-data-flow
- 16. 分布式事务
- 17. spring cloud alibaba 配合 dubbo
- 18. 实际设计案例 票务网站
- 19. 案例 在线教育
- 20. 案例 聚合支付
- 21. 案例 广告系统
- 22. 案例 电商类网站
- 23. 案例 物联网平台
1. 一套微服务平台技术选型
开发组件
spring boot
jpa / mybatisplus
mapstruct 对象转换插件
knife + swagger api 文档
easycode 代码生成
idea 插件
jrebel
mybatisx
batslog
generateAllsetter
swagger tools
restful tool
string manipulation
gsonformatplus
Maven helper
key promoter
Rainbow brackets
grep console
code glance
微服务
nacos 配置中心, 注册中心
spring-cloud-gateway 网关
spring-security + oauth2.0 安全验证
seata 分布式事务
sentinel 限流(流量防护, 带有控制面板)
open feign 服务调用(负载均衡)
skywalking 链路追踪
elastic search 业务搜索
EFK(es, filebeat, kibana) 分布式日志存储展示
Prometheus + grafana 监控 (指标采集 + 展示面板)
钉钉告警
canal 数据同步 (MySql -> ES)
xxl-job 分布式任务调度
rocketMQ 消息队列
redis-cluster 缓存
redission 基于redis 的分布式锁
MySQL 数据库
jeepay 支付聚合平台
云原生 devops
docker 容器化
Harbor 私有镜像仓库
k8s 编排管理, 部署
kubesphere 容器监控
gitlab 代码管理
Jenkins 持续集成
Maven 打包编译
nexus Maven 私有仓库
2. 微服务核心要素和 spring cloud 工作流程
Spring Cloud主要的要素/组件:
service registry/find (client, server)
distributed configuration management (server , client)
http/rpc, load balance
circuit breaker
gateway
以及它的访问流程:
外部或者内部的非Spring Cloud项目都统一通过API网关(Zuul)来访问内部服务.
网关接收到请求后,从注册中心(Eureka)获取可用服务
由Ribbon进行均衡负载后,分发到后端的具体实例
微服务之间通过Feign进行通信处理业务
Hystrix负责处理服务超时熔断
Turbine监控服务间的调用和熔断相关指标
3. 和dubbo-zookeeper对比
dubbo是用来跨系统通信的,是一个 rpc 框架。
zookeeper 是一个分布式系统节点管理, 可以做注册中心
一个系统用作客户端,一个系统则充当服务端。服务端要把自己的接口定义提供给客户端,客户端将接口定义在spring中的bean。客户端可以直接使用这个bean,就好像这些接口的实现也是在自己代码里一样。 客户端和服务端启动的时候都会把自己的机器IP注册到zookeeper上。客户端会把zk上的服务端ip拉到磁盘上,并记录哪些ip提供哪些服务(服务端启动的时候暴露给zk)。然后调用的时候客户端会根据ip调用服务端的服务,这时候即使zk挂掉也没关系。
springcloud 是 dubbo 的超集;
可以自定义名字 , 位置;
4. 配置中心
使用了配置中心后, 在各个 config client 需要用 bootstrap application context, 对应的 配置文件 bootstrap.yml, 用于配置不会经常变化的 配置, 如 app name, config server addr
先于 application.yml 读取, 应用于更加早期配置信息读取,如可以使用来配置application.yml中使用到参数等
如使用 Spring Cloud Config Server 的时候,在 bootstrap.yml 里面指定 spring.application.name 和 spring.cloud.config.server.git.uri
spring:
application:
name: service-a
cloud:
bootstrap:
# 禁用 bootstrap 过程
enabled: false
config:
uri: http://127.0.0.1:8888
fail-fast: true
username: user
password: ${CONFIG_SERVER_PASSWORD:password}
retry:
initial-interval: 2000
max-interval: 10000
multiplier: 2
max-attempts: 10
4.1. Spring-Cloud-Config
进入 maintenance
包含了Client和Server两个部分, server自动将存储的配置文件发布成REST接口, client通过接口获取数据、并依据此数据初始化自己的应用
客户端完全透明(但是需要在 client 的 bootstrap.properties 中配置server端信息, 至少需要 spring.cloud.config.server.git.uri, 同时可以配置搜索目录 spring.cloud.config.search-paths), server 需要开启 @enableConfigServer
Spring cloud使用git或svn存放配置文件,默认情况下使用git;
和 eureka 配合后, config server端api接口使用规则:
/{application}/{profile}[/{label}]
# application - [主文件名]
# profile 为 文件名profile 后缀, 没有则为 default
# label(分支名)可选,默认为master, 返回结构化的json
/{application}-{profile}.yml # 直接返回property source文件内的文本内容
/{application}-{profile}.properties
/{label}/{application}-{profile}.yml
/{label}/{application}-{profile}.properties
git repo config file 默认命名规则: 对于 git repo 中的配置文件 'config-client-dev.yml', config-client 为client端 spring.application.name 的值, dev 为 client 激活的 profiles
如果希望自定义 git repo config file 命名, 可以在 config client 配置 spring.cloud.config.name/profile/label/, name 是主文件名, profile 是后缀名
client 的刷新功能: 最好通过 spring cloud bus 实现; 但是基本的 refresh 也实现了, curl -d{} http://localhost:8080/refresh 之后 client 才会使用新的配置, 如果开启了 actuator , 则会出现 404, 需要配置 management.endpoints.web.exposure.include=refresh,info,health (默认值只有 info , health. 如果是 yml , 则值需要加单引号), 然后 curl -d{} http://xxx:xxx/actuator/refresh, 涉及到刷新的类, 需要 @RefreshScope (to support config refresh; 原理是 config server 修改了配置, 这个 controller bean 会销毁重新生成)
引入 配置中心后, client 端的 application.yml 需要 rename 为 bootstrap.yml, 最先读取, 会被后面读取的配置覆盖, 所以优先级低于 config server 中的配置
config server 修改配置后, commit(git 仓库在本地) 或者 push (git 库在远程) 后 client 端即可生效
多服务公用配置文件 (公共配置文件):
方法1: 在配置文件仓库增加配置文件 application.properties 作为公共文件即可. serviceA 无法在自己的配置文件 (如 serviceA.properties, serviceA-dev.properties) 找到配置项, 会到 公共文件中找
方法2: 新建 common.properties 作为公共文件, 到每个 client 端 修改
spring.cloud.config.name=ServiceA,common配置多个配置文件名
重要的配置
# server
server.port=8888
# 本地的git repo 就这么设置 file://${user.home}/config-repo(Linux) file:///${user.home}/config-repo (windows), 最新版本无需如此设置了
# 如果是 remote git repo, 还需要 username, password, basedir (clone to here), search-path(properties source 路径)
spring.cloud.config.server.git.uri=${user.home}/Desktop/config
# client
spring.application.name=reservation-service
# 一般在 bootstrap.yml 配置
# default
# 还有 label(master), profile(default to `default`), fail-first(default to false), name(file name in remote config repo)
spring.cloud.config.uri=http://localhost:8888
# config refresh required: curl -d{} http://localhost:8000/actuator/refresh
management.endpoints.web.exposure.include=refresh,info,health
4.2. apolo
来自携程
4.3. alibaba nacos 作为配置中心
namespace 命名空间
若不配置, 则 App 默认读取 public 下的配置; {spring.application.name}.yml/properties
常用的隔离方案有两个: 如 每个 sub module 拥有一个 namespace, 每个 namespace 里面分 dev.yml, prod.yml... ; 或者有三个 namespace: dev, prod, test. 每个 namespace 下有 sub-module1.yml, sub-module2.yml, sub-module3.yml...
data-id 配置集, 可将一个配置文件分拆为多个配置文件, 每个配置集都有位于 extension-configs 下的 data-id, group, refresh(需要 @NacosValue(value = "${aa.bb}", autoRefreshed = true) 配合)
若不配置, 默认读取 {spring.application.name}.yml/properties
一般项目中的配置文件会拆分为多个配置集, 如 datasource.yml, mybatis.yml...
必须配置为 文件全名(即包括后缀, xml, json, properties, yml)
group 配置的分组
若不配置, 加载时, 默认每次都加载某 namespace 下属于 DEFAULT_GROUP 分组的配置文件
一般用来区分环境, 如 dev , prod , test . 场景: 双十一临时使用 分组 11-11 下的配置文件, 可以方便的切换
5. 注册中心
5.1. 注册中心选型
https://blog.csdn.net/fly910905/article/details/100023415
阿里巴巴为什么不使用 zk 作为 registry center
Eureka, consul (golang), zookeeper; 新出的 nacos
eureka就是个servlet程序,跑在servlet容器中; Consul则是go编写而成。
cap 支持不同:
Consul优先保证强一致性(C), 服务注册相比Eureka会稍慢一些。因为Consul的raft协议要求必须过半数的节点都写入成功才认为注册成功; Leader挂掉时,重新选举期间整个consul不可用。保证了强一致性但牺牲了可用性。
Eureka优先保证高可用(A), 但是会保证最终一致性, 服务注册相对要快,因为不需要等注册信息replicate到其他节点; 当数据出现不一致时,虽然A, B上的注册信息不完全相同,但每个Eureka节点依然能够正常对外提供服务,这会出现查询服务信息时如果请求A查不到,但请求B就能查到。如此保证了可用性但牺牲了一致性
zookeeper 优先保证 c , client 没有心跳, 立即删除该节点
nacos 是用于替代 eureka, 特性和 eureka 类似, 保证 ap, 也支持控制台
对外暴露的接口情况不同:
consul 和 eureka 支持 http
zookeeper 只提供了 client, 需要通过 client 交互
5.2. eureka
目前 maintenance
默认下, eureka client 加入 class path 后, 应用会自动注册到 eureka server (默认 defaultZone 为 http://localhost:8761/eureka); 作为 eureka server, eureka client 依赖不需要引入了
client 端连接 server, 如果自定义 eureka 地址, client 需要配置 eureka.client.serviceUrl(map 类型), 增加 defaultZone (大小写敏感, 默认值为 localhost:8761/eureka) 属性, 用来定位 server 地址, 然后 @EnableDiscoveryClient // compared with @EnableEurekaClient, more comprehensive
提供服务注册和发现, Eureka的工作过程:
每个 service 都包含一个 Eureka client 组件, 将 机器ip, 监听端口上报给 Eureka server, Eureka server 中保存有一个注册表, application name 和 ip 端口 一一对应, Eureka client 会从 Eureka server 拉去注册表缓存在本地,
注册中心是比较重要的基础组件, 仅仅使用“单点”还不够, 更多使用“集群”(通过运行多个实例,并进行互相注册的方式来实现高可用的部署);
自我保护机制: 某一时刻有大量节点的心跳无法被某个 eureka 节点接收到, eureka 会认为发生了网络分区故障 (比如 延时 卡顿 拥挤), eureka 不会立即清除这些节点, 而是会保持一段时间 (保证 ap, 牺牲掉了 cp),
控制台显示信息优化: 默认 eureka 控制台 ui 中, 已注册节点 table 的 status 列会显示主机名, eureka.instance.instance-id 可以定制显示的 实例名, 一般和 application name 相同或者是 ${spring.cloud.client.ip-address}:${server.port}, 还有 eureka.instance.prefer-ip-address=true(超链接显示 ip), 这两个都是针对 eureka client 的配置
重要的配置
# server
# 自我保护模式, default true, 若希望保证一致性, 不要可用性, 可以关闭
# If set this to true, the registration info cannot be changed if register/remove frequently
eureka.server.enable-self-preservation: true
# Remove invalid service instance info every xxx ms
# 续期时间,即扫描失效服务的间隔时间(缺省为60*1000ms)
eureka.server.eviction-interval-timer-in-ms: 6000
# The time that server wait between two heartbeats, if the second heartbeat arrives late, then remove the instance
# Have to > 客户端的 lease-renewal-interval-in-seconds
eureka.instance.lease-expiration-duration-in-seconds: 90
# client
# 设置是否将自己作为客户端注册到注册中心(缺省true)
# 其实查看@EnableEurekaServer注解的源码,会发现它间接用到了@EnableDiscoveryClient), so server 端无需引入 client 依赖
eureka.client.register-with-eureka=true
# 需要注册到的地址 , serviceUrl 是一个 map, defaultZone 无法使用 '-', yml 文件 map 为 `{xxx: yyy}`, list 为 `- xxx: yyy`
# 如果单点就是注册到自己, 高可用就需要配置为注册到别的 eureka 节点, 注册到多个 eureka 用 `,` 分开
eureka.client.serviceUrl.defaultZone=http://localhost:${server.port}/eureka/
# 是否同步其他已经注册的 service 数据, 单点需要 false (default 为 true, 集群必须为true, 否则 ribbon不可用)
eureka.client.fetch-registry
# depend on spring-boot-starter-actuator, default to true
eureka.client.health-check.enabled=true
# fetch info from eureka server interval, default 30s (clients have an copy of registration info from server)
eureka.client.registry-fetch-interval-seconds=30
# the Frequency that client send heartbeat to server, default 30s (心跳时间 / 服务续约间隔时间)
eureka.instance.lease-renewal-interval-in-seconds=30
# server 在受到最后一次心跳后的等待时间 (default to 90s), 超时则删除节点
eureka.instance.lease-expiration-duration-in-seconds=90
# 定制 ui 页中的 status 列显示什么 (主机名称:服务名称修改)
eureka.instance.instance-id=xxx
# ui 页中的访问路径可以显示 ip 地址
eureka.instance.prefer-id-address=true
eureka 集群配置:
修改机器 hosts
127.0.0.1 eureka001.com
127.0.0.1 eureka002.com
127.0.0.1 eureka003.com
为 eureka 加上安全校验:
引入 spring-boot-starter-security, security.user.name=你的用户名 和 security.user.password=你的密码
eureka.client.serviceUrl.defaultZone=http://${security.user.name}:${security.user.password}@127.0.0.1:${server.port}/eureka/
5.3. consul
功能比 Eureka 多 (还能做 配置中心, 消息总线bus), 作为注册中心, 区别在于: Eureka保证 AP (自我保护机制导致 ap), Consul为CP。
目前,Consul 已经取代 Eureka 成为 Spring Cloud 的缺省服务注册发现组件
5.4. zookeeper
业界使用暂时不多, 原生不带 ui 界面
5.5. nacos 作为注册中心
完美替代 eureka
https://www.jianshu.com/p/6b6cf891ac6a 扩展Ribbon支持Nacos权重的三种方式 todo
修改配置: (数据源, auth)
# 数据库连接配置,原来这三项是注释了的,去掉前面的"#"号
# 数据库连接地址及数据库名称根据自己实际情况修改
db.url.0=jdbc:mysql://127.0.0.1:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC
# 数据库的用户名及密码根据自己的实际情况修改
db.user.0=root
db.password.0=rootPassword
# 原来该配置的为false,开启nacos接入鉴权,这行最为关键
nacos.core.auth.enabled=true
# 当nacos.core.auth.enabled设置为true之后,下面两项必须给值,原来的以下两项都没有值,可以直接使用下面的值,不报错
nacos.core.auth.server.identity.key=serverIdentity
nacos.core.auth.server.identity.value=security
# 原来这项配置为空,key还必须为base64,就用以下这个key可以不报错
nacos.core.auth.plugin.nacos.token.secret.key=SecretKey012345678901234567890123456789012345678901234567890123456789
5.6. etcd
TODO golang 实现
6. 服务相互调用
6.1. 手动实现调用框架
https://zhuanlan.zhihu.com/p/29348799 https://github.com/xwjie/MyRestUtil
6.2. feign
进入 maintenance, 不推荐使用
6.3. OpenFeign
声明式的rest client, 底层是通过 ribbon 实现负载均衡 (相当于 RestTemplate + ribbon)
包含了 hystrix 依赖
使用feign时默认提供了Ribbon 的load balancing
使用 Feign 时也引入了 hystrix, 默认不开启 (hystrix 一般是作用在服务调用即客户端这一端, 也就是常常和Feign一起使用)
一个client 就是一个接口, feign 针对这个接口实现了代理类 (动态代理)
@EnableFeignClients
@FeignClient(also support 'url', 用于无 eureka 的情况; fallback 为 class type , 是当前 client interface 的实现类, 需要 @component, 在实现的方法中做降级回调逻辑, configuration 当前 feign client 的配置类,可以自定义Feign的Encoder、Decoder、LogLevel、Contract ; path: 定义当前FeignClient的统一前缀)
# enable hystrix support, default to false, 也可以使用 @EnableCircuitBreaker 开启
feign.hystrix.enabled: true
6.3.1. 基本使用
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
6.3.2. 超时综合配置
各种超时配置,如果都存在,则时间小的配置生效
最常用的配置配置原则:
1 开启Feign的hystrix开关
2 hystrix超时时长
3 配置ribbon的ConnectTimeout时长
4 配置ribbon的ReadTimeout 时长
# hystrix可配置的部分 (feign 默认 关闭 hystrix)
hystrix.command.default.execution.timeout.enable=true //为false则超时控制有ribbon控制,为true则hystrix超时和ribbon超时都是用,但是谁小谁生效,默认为true
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds=3000//熔断器的超时时长默认1秒,最常修改的参数
circuitBreaker.requestVolumeThreshold=20 //触发熔断的最小请求次数,默认为20
circuitBreaker.sleepWindowInMilliseconds=5000 //休眠时长,默认为5秒
circuitBreaker.errorThresholdPercentage=50 //触发熔断的失败请求最小占比,默认50%
# ribbon的可配置部分
ribbon.ReadTimeout=1000 //处理请求的超时时间,默认为1秒
ribbon.ConnectTimeout=1000 //连接建立的超时时长,默认1秒
ribbon.MaxAutoRetries=1 //同一台实例的最大重试次数,但是不包括首次调用,默认为1次
ribbon.MaxAutoRetriesNextServer=0 //重试负载均衡其他实例的最大重试次数,不包括首次调用,默认为0次
ribbon.OkToRetryOnAllOperations=false //是否对所有操作都重试,默认false
# Feign的可配置部分
feign.hystrix.enabled=false //Feign是否启用断路器,默认为false
# default为全局配置,如果要单独配置每个服务,改为服务名
feign.client.config.default.connectTimeout=10000 //Feign的连接建立超时时间,默认为10秒
feign.client.config.default.readTimeout=60000 //Feign的请求处理超时时间,默认为60s
feign.client.config.default.retryer=feign.Retryer.Default //Feign使用默认的超时配置,在该类源码中可见,默认单次请求最大时长1秒,重试5次
# 服务实例缓存
#LoadBalancer为了提高性能,不会在每次请求时去获取实例列表,而是将服务实例列表进行了本地缓存。
spring:
cloud:
loadbalancer:
cache: # 负载均衡缓存配置
enabled: true # 开启缓存
ttl: 5s # 设置缓存时间
capacity: 256 # 设置缓存大小
6.3.3. feign client interceptor
https://www.cnblogs.com/keeya/p/13559151.html#feignclient-%E6%B3%A8%E8%A7%A3%E5%8F%82%E6%95%B0
public class FeignBasicAuthRequestInterceptor implements RequestInterceptor {
private static final Logger logger = LoggerFactory.getLogger(FeignBasicAuthRequestInterceptor.class);
@Override
public void apply(RequestTemplate requestTemplate) {
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder
.getRequestAttributes();
HttpServletRequest request = attributes.getRequest();
Enumeration<String> headerNames = request.getHeaderNames();
if (headerNames != null) {
while (headerNames.hasMoreElements()) {
String name = headerNames.nextElement();
String values = request.getHeader(name);
requestTemplate.header(name, values);
}
}
Enumeration<String> bodyNames = request.getParameterNames();
StringBuffer body =new StringBuffer();
if (bodyNames != null) {
while (bodyNames.hasMoreElements()) {
String name = bodyNames.nextElement();
String values = request.getParameter(name);
body.append(name).append("=").append(values).append("&");
}
}
if(body.length()!=0) {
body.deleteCharAt(body.length()-1);
requestTemplate.body(body.toString());
logger.info("feign interceptor body:{}",body.toString());
}
}
}
配置 让所有 FeignClient,使用 FeignBasicAuthRequestInterceptor
feign:
client:
config:
default:
connectTimeout: 5000
readTimeout: 5000
loggerLevel: basic
requestInterceptors: com.leparts.config.FeignBasicAuthR
也可以配置让 某个 FeignClient 使用这个 FeignBasicAuthRequestInterceptor
feign:
client:
config:
xxxx: # 远程服务名
connectTimeout: 5000
readTimeout: 5000
loggerLevel: basic
requestInterceptors: com.leparts.config.FeignBasicAuthR
在转发Feign的请求头的时候, 如果开启了Hystrix, Hystrix的默认隔离策略是Thread(线程隔离策略), 因此转发拦截器内是无法获取到请求的请求头信息的。
可以自定义 hystrix 隔离策略
6.3.4. 日志配置
了解 http 请求细节
日志级别:
none: 默认, 不显示日志
basic 仅仅记录请求方法, url, response status code, 响应时间
headers: 增加了 header 信息
full: 增加了 请求响应体
配置类中增加
@Configuration
class FeignConfig {
@Bean
public Logger.Level feignLoggerLevel() {
return Logger.Level.FULL;
}
}
然后配置文件中, 指定监控的 feign client 接口以及日志级别 logging.level.io.github.xiaoyu.xxx.ReservationResource=debug
6.3.5. feign Client 在生产者端还是在消费者端定义
在生产端API中声明Feign客户端 (消费端服务直接依赖生产端提供的API包,然后通过@Autowired注解注入,就可以直接调用生产者提供的接口)
好处 是:简单方便,消费端直接使用生产者提供的Feign接口即可。
坏处 也很明显:
熔断降级类也在生产端, 无法自定义
消费端在调用时由于包路径可能与生产者不一样,必须要通过@SpringBootApplication(scanBasePackages = {"com.javadaily.feign"})扫描Feign的路径,当消费端需要引入很多生产者Feign时那就需要扫描很多个接口路径。
在消费端声明Feign客户端 (推荐)
好处 是:客户端可以按需编写自己需要的接口,熔断降级都由消费者控制;不需要在启动类上加入额外的扫描注解scanBasePackages。
坏处 是:消费端代码冗余,每个消费者都需要编写Feign客户端;服务间耦合比较紧,修改一处接口三处都要修改。
Retrofit
类似 openfeign, 支持通过接口的方式发起HTTP请求
7. 负载均衡
7.1. 集中式负载均衡和客户端负载均衡
下面都是 client side LoadBalance
或者叫 进程式负载均衡, 就是 将 负载均衡逻辑集成到consumer, consumer从注册中心的 client 端获知有那些地址可以用,然后自己再从这些地址中选择出一个合适的 provider
7.2. ribbon
已经被弃用, 推荐 LoadBalancer
进入 maintenance, 但是 spring cloud 官方还在用, 只是日志中会推荐使用 spring cloud loadbalancer
Ribbon: (client side) load balancing; ribbon可以将请求均匀的分配到各个机器上, 必须和 注册中心一起使用 (eureka client 依赖包含了 ribbon 依赖)
7.2.1. 如何使用 ribbon
一种方法是 @LoadBalanced + restTemplate:
@SpringBootApplication
@EnableDiscoveryClient
@RestController
public class RibbonDemoApplication {
@Autowired
private RestTemplate restTemplate;
@GetMapping("/hello")
public String hello() {
//Spring Cloud Ribbon有一个拦截器,它能够在这里进行实际调用的时候,自动的
// 去选取服务实例,并将实际要请求的IP地址和端口替换这里的服务名
return restTemplate.getForObject("http://eureka-single-client/hah", String.class);
}
public static void main(String[] args) {
SpringApplication.run(RibbonDemoApplication.class, args);
}
@Bean
@LoadBalanced // ribbon
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
还有一种就是 配合 openFeign: (推荐)
@FeignClient("reservation-service")
// also support 'url' ( outside eureka)
interface ReservationResources {
@RequestMapping("/reservations")
CollectionModel<Reservation> reservations();
@RequestMapping("/message")
String message();
}
7.2.2. 负载均衡算法
ribbon 提供的负载均衡算法
默认使用Round Robin轮询算法 (请求将依次分发到1~n台机器, 如果还没分发完, 再次从第一台机器开始循环);
算法实现: 每次计算出 instance index 后都对其进行记录, 下一次请求过来在上次 index 基础上增加一, 如果下标超出 instance 个数, 使用 instance count 取余
响应时间权重算法, 即根据每个 provider 的 response time 为该 provider 实例分配一个权重, response time 越长, 权重越小, 被选中的几率越低
随机
最少并发数策略: 选择这样的 provider, 它的正在处理的并发数最少, 并且这个 provider 没有处于熔断中
如何替换 ribbon 提供的算法, 做个性化配置?
自定义一个 配置类, 将 选定的 规则 bean 注入 spring, @RibbonClient(name = "target-service", configuration = {RibbonRuleConfig.class}) (意思是对名为 target-service 的服务端以 RibbonRuleConfig 中配置的策略做负载均衡, 即 service 和 rule 的映射)
自定义 ribbon 配置类不要放在 @componentScan 扫的 package 下, 否则这个自定义配置中的 rule bean 会被所有 ribbon client 共享
分析 RoundRobinRule 源码:
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
log.warn("no load balancer");
return null;
}
Server server = null;
int count = 0;
// 从 loadBalancer 获取 allServer, 重试 10 次
while (server == null && count++ < 10) {
List<Server> reachableServers = lb.getReachableServers();
List<Server> allServers = lb.getAllServers();
int upCount = reachableServers.size();
int serverCount = allServers.size();
if ((upCount == 0) || (serverCount == 0)) {
log.warn("No up servers available from load balancer: " + lb);
return null;
}
int nextServerIndex = incrementAndGetModulo(serverCount);
server = allServers.get(nextServerIndex);
if (server == null) {
/* Transient. */
Thread.yield();
continue;
}
if (server.isAlive() && (server.isReadyToServe())) {
return (server);
}
// Next.
server = null;
}
if (count >= 10) {
log.warn("No available alive servers after 10 tries from load balancer: "
+ lb);
}
return server;
}
/**
* Inspired by the implementation of {@link AtomicInteger#incrementAndGet()}.
*
* @param modulo The modulo to bound the value of the counter.
* @return The next value.
*/
private int incrementAndGetModulo(int modulo) {
// cas + 自旋
// nextServerCyclicCounter 是上次选中的 instance index
for (;;) {
int current = nextServerCyclicCounter.get();
int next = (current + 1) % modulo;
if (nextServerCyclicCounter.compareAndSet(current, next))
return next;
}
}
7.3. spring cloud loadBalancer
Spring Cloud Load Balancer并不是一个独立的项目,而是spring-cloud-commons其中的一个模块
项目中用了Eureka以及相关的 starter,想完全剔除Ribbon的相关依赖基本是不可能的,Spring 社区的人也是看到了这一点,所以给出的做法是: 通过配置spring.cloud.loadbalancer.ribbon.enabled=false去关闭Ribbon, 自动就启用了 Spring-Cloud-LoadBalancer, 成为默认的负载均衡器。 (https://www.yht7.com/news/92837)
openfeign 集成了, 推荐openfeign 来使用
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
/**
* RestTemplate相关配置
*/
@Configuration
public class RestTemplateConfig {
/*
rest:
template:
config: # RestTemplate调用超时配置
connectTimeout: 5000
readTimeout: 5000
*/
@Bean
@ConfigurationProperties(prefix = "rest.template.config")
public HttpComponentsClientHttpRequestFactory customHttpRequestFactory() {
return new HttpComponentsClientHttpRequestFactory();
}
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate(customHttpRequestFactory());
}
}
/**
* LoadBalancer相关配置
* 将ServiceInstance的instanceId放入到请求头X-InstanceId中;
*/
@Configuration
public class LoadBalancerConfig {
@Bean
public LoadBalancerRequestTransformer transformer() {
return new LoadBalancerRequestTransformer() {
@Override
public HttpRequest transformRequest(HttpRequest request, ServiceInstance instance) {
return new HttpRequestWrapper(request) {
@Override
public HttpHeaders getHeaders() {
HttpHeaders headers = new HttpHeaders();
headers.putAll(super.getHeaders());
headers.add("X-InstanceId", instance.getInstanceId());
return headers;
}
};
}
};
}
}
8. 熔断器
8.1. hystrix
进入 maintenance, 但是设计理念值得学习
8.1.1. hystrix 原理
Hystrix: 隔离, 熔断(防止故障扩散, circuit breaker), 降级, 限流, 实时的监控
为什么需要 CircuitBreaker? 防止 cascading failure (服务雪崩)
服务雪崩效应: 在一个 micro service system 里, 会涉及到服务的 级联调用, 如果下游的 service 异常, 上游的 service 也会卡住(然后超时异常), 上游 service 卡住的请求多了 线程等资源会耗尽, 进而这个上游 service 也会异常, 由于连锁反应, 最后整条调用链上的服务都会异常; 而实际上上游 service 是可以在下游 service 挂掉后单独提供服务的, 比如 订单服务 和 积分服务
hystrix 是 熔断器的一个实现, 消费侧,服务侧都可使用
熔断器(CircuitBreaker): (熔断器模式就像是那些容易导致错误的操作的一种代理。这种代理能够记录最近调用发生错误的次数,然后决定使用允许操作继续,或者立即返回错误) 熔断器就是保护服务高可用的最后一道防线。
原理: 当前 service 调用其他不同的 service, 都有一个独立的 thread pool (隔离), 防止线程资源由于某个 service 故障而被耗尽; 将函数调用包装在一个 circuit breaker 对象中, 对调用失败次数进行监控, 达到设定的阈值, 直接返回错误而不访问原始函数 (熔断), 同时有一个回调函数, 进行额外动作(降级)
熔断只是作用在服务调用这一端(consumer 组件端)
Hystrix特性:
熔断机制 : 当Hystrix Command请求后端服务失败数量超过一定比例(
默认50%), 断路器会切换到开路状态(Open). 这时所有请求会直接失败而不会发送到后端服务, 在一个 时间窗口期内 (默认 5s) , fallback 成为主逻辑, 当休眠时间窗到期, , 自动切换到半开路状态(HALF-OPEN). 这时会判断下一次请求的返回情况, 如果请求成功, 断路器切回闭路状态(CLOSED), 否则重新切换到开路状态(OPEN), 时间窗重新计时.Fallback: 降级操作.
对于查询操作, 可以实现一个fallback方法, 当请求后端服务出现异常的时候, 可以使用fallback方法返回值. fallback方法的返回值一般是设置的默认值或者来自缓存.
什么时候需要降级? 超时, 异常, 熔断, 线程池/信号量 打满
资源隔离: 在Hystrix中, 主要通过线程池来实现资源隔离; 通常在使用的时候我们会根据调用的远程服务划分出多个线程池. 例如调用产品服务的Command放入A线程池, 调用账户服务的Command放入B线程池. 这样做的主要优点是运行环境被隔离开了. 这样就算调用服务的代码存在bug或者由于其他原因导致自己所在线程池被耗尽时, 不会对系统的其他服务造成影响. 但是带来的代价就是维护多个线程池会对系统带来额外的性能开销. 如果是对性能有严格要求而且确信自己调用服务的客户端代码不会出问题的话, 可以使用Hystrix的信号模式(Semaphores)来隔离资源.
8.1.2. hystrix 降级使用
8.1.2.1. 单独使用
一种使用方法: @HystrixCommand(fallbackMethod = "defaultHah") , defaultHah 方法可以多一个参数表示异常; 然后 @EnableCircuitBreaker/@EnableHystrix (后者包含了前者)
熔断条件配置, 可以在配置文件
server:
port: 8080
circuitBreaker:
# 符合这些条件, 打开
# When calls to a particular service exceed
requestVolumeThreshold: 20
# failure percentage is greater than
errorThresholdPercentage: 50%
metrics:
rollingStats:
# in a rolling window defined by .., the circuit opens and the call is not made
timeInMilliseconds: 10
也可以直接在注解上配置:
@HystrixCommand(fallbackMethod = "fallback", commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "3000")
})
@RequestMapping("/reservations/names")
public ResponseEntity<Collection<String>> names() {
// 超时或者异常 都走 fallback 方法
// if (enableErr) {
// throw new RuntimeException("some error produced");
// }
try {
Thread.sleep(5 * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return new ResponseEntity<>(reservationResources.reservations().getContent().stream()
.map(Reservation::getName).collect(Collectors.toList()), HttpStatus.OK);
}
类级别的(全局的)降级: 类级别的注解 @DefaultProperties(defaultFallback = "defaultFallback"), defaultFallback 是当前类的一个方法
配置参数及默认值在 HystrixCommandProperties 可以查看
@HystrixCommand(fallbackMethod = "fallback", commandProperties = {
@HystrixProperty(name = "circuitBreaker.enabled", value = "true"), // 是否开启
@HystrixProperty(name = "circuitBreakerVolumeThreshold", value = "10"),// 请求次数, 默认 20 次, 超过才会打开
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliSeconds", value = "5000"),// 睡眠时间窗口 (这段时间后进入半开状态), 默认 5s
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "60")// 失败率限额, 超过则断开
@HystrixProperty(name = "metrics.rollingStats.timeInMilliseconds", value = "10000")// 滚动统计时间窗口
})
@RequestMapping("/reservations/names")
public ResponseEntity<Collection<String>> names() {
// 超时或者异常 都走 fallback 方法
// if (enableErr) {
// throw new RuntimeException("some error produced");
// }
try {
Thread.sleep(5 * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return new ResponseEntity<>(reservationResources.reservations().getContent().stream()
.map(Reservation::getName).collect(Collectors.toList()), HttpStatus.OK);
}
8.1.2.2. 配合 openFeign
第二种使用方法: 一般是配合 openFeign 进行降级
@FeignClient(value = "reservation-service", fallback = ReservationResourcesFallback.class)
// also support 'url' ( outside eureka)
interface ReservationResources {
@RequestMapping("/reservations")
CollectionModel<Reservation> reservations();
@RequestMapping("/message")
String message();
}
@Component
class ReservationResourcesFallback implements ReservationResources {
@Override
public CollectionModel<Reservation> reservations() {
return null;
}
@Override
public String message() {
return null;
}
}
8.1.3. 熔断监控Hystrix-Dashboard和Turbine
Hystrix-dashboard是一款针对Hystrix进行实时监控的工具, 各Hystrix Command的请求响应时间, 请求成功率等数据。(实时监控, 历史熔断数据无法查看)
但是只使用Hystrix Dashboard的话, 你只能看到单个应用内的服务信息, 这明显不够. 我们需要一个工具能让我们汇总系统内多个服务的数据并显示到Hystrix Dashboard上, 这个工具就是Turbine.
Hystrix-Dashboard 可以直接 app 中集成, 监控其所在的那个 app; turbine 新启了一个独立项目, 专门负责监控所有的node;
Netflix提供了一个开源项目(Turbine)来提供把多个hystrix.stream的内容聚合为一个数据源供Dashboard展示
每个使用了 hystrix 的 app 会发布一个接口 http://app-uri/actuator/hystrix.stream (需要引入 actuator, 配置 management.endpoints.web.exposure.include=hystrix.stream, 直接配置为 "*" 暴露全部亦可), 返回 hystrix steam 数据, 在 hystrix dashboard (http://dashboard-uri/hystrix) 输入前面的steam地址呈现图形界面; 查看 Hystrix Dashboard Wiki 可知晓监控画面的含义
访问 http://localhost:8001/turbine.stream 出现stream数据界面(纯数据字符); 访问http://localhost:8001/hystrix 接着输入stream地址, 呈现图形界面;
8.1.4. 自定义隔离策略
@Component
public class FeignHystrixConcurrencyStrategy extends HystrixConcurrencyStrategy {
private static final Logger log = LoggerFactory.getLogger(FeignHystrixConcurrencyStrategy.class);
private HystrixConcurrencyStrategy delegate;
public FeignHystrixConcurrencyStrategy() {
try {
this.delegate = HystrixPlugins.getInstance().getConcurrencyStrategy();
if (this.delegate instanceof FeignHystrixConcurrencyStrategy) {
// Welcome to singleton hell...
return;
}
HystrixCommandExecutionHook commandExecutionHook =
HystrixPlugins.getInstance().getCommandExecutionHook();
HystrixEventNotifier eventNotifier = HystrixPlugins.getInstance().getEventNotifier();
HystrixMetricsPublisher metricsPublisher = HystrixPlugins.getInstance().getMetricsPublisher();
HystrixPropertiesStrategy propertiesStrategy =
HystrixPlugins.getInstance().getPropertiesStrategy();
this.logCurrentStateOfHystrixPlugins(eventNotifier, metricsPublisher, propertiesStrategy);
HystrixPlugins.reset();
HystrixPlugins instance = HystrixPlugins.getInstance();
instance.registerConcurrencyStrategy(this);
instance.registerCommandExecutionHook(commandExecutionHook);
instance.registerEventNotifier(eventNotifier);
instance.registerMetricsPublisher(metricsPublisher);
instance.registerPropertiesStrategy(propertiesStrategy);
} catch (Exception e) {
log.error("Failed to register Sleuth Hystrix Concurrency Strategy", e);
}
}
private void logCurrentStateOfHystrixPlugins(HystrixEventNotifier eventNotifier,
HystrixMetricsPublisher metricsPublisher,
HystrixPropertiesStrategy propertiesStrategy) {
if (log.isDebugEnabled()) {
log.debug("Current Hystrix plugins configuration is [" + "concurrencyStrategy ["
+ this.delegate + "]," + "eventNotifier [" + eventNotifier + "]," + "metricPublisher ["
+ metricsPublisher + "]," + "propertiesStrategy [" + propertiesStrategy + "]," + "]");
log.debug("Registering Sleuth Hystrix Concurrency Strategy.");
}
}
@Override
public <T> Callable<T> wrapCallable(Callable<T> callable) {
RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes();
return new WrappedCallable<>(callable, requestAttributes);
}
@Override
public ThreadPoolExecutor getThreadPool(HystrixThreadPoolKey threadPoolKey,
HystrixProperty<Integer> corePoolSize,
HystrixProperty<Integer> maximumPoolSize,
HystrixProperty<Integer> keepAliveTime,
TimeUnit unit, BlockingQueue<Runnable> workQueue) {
return this.delegate.getThreadPool(threadPoolKey, corePoolSize, maximumPoolSize, keepAliveTime,
unit, workQueue);
}
@Override
public ThreadPoolExecutor getThreadPool(HystrixThreadPoolKey threadPoolKey,
HystrixThreadPoolProperties threadPoolProperties) {
return this.delegate.getThreadPool(threadPoolKey, threadPoolProperties);
}
@Override
public BlockingQueue<Runnable> getBlockingQueue(int maxQueueSize) {
return this.delegate.getBlockingQueue(maxQueueSize);
}
@Override
public <T> HystrixRequestVariable<T> getRequestVariable(HystrixRequestVariableLifecycle<T> rv) {
return this.delegate.getRequestVariable(rv);
}
static class WrappedCallable<T> implements Callable<T> {
private final Callable<T> target;
private final RequestAttributes requestAttributes;
WrappedCallable(Callable<T> target, RequestAttributes requestAttributes) {
this.target = target;
this.requestAttributes = requestAttributes;
}
@Override
public T call() throws Exception {
try {
RequestContextHolder.setRequestAttributes(requestAttributes);
return target.call();
} finally {
RequestContextHolder.resetRequestAttributes();
}
}
}
}
8.2. spring cloud alibaba sentinel
国内使用多
# 启动控制台
# -Dcsp.sentinel.dashboard.server=consoleIp:port 指定控制台地址和端口, 将控制台自身信息注册到 dashboard
# 若启动多个应用,则需要通过 -Dcsp.sentinel.api.port=xxxx 指定客户端监控 API 的端口(默认是 8719)
java -Dserver.port=18888 -Dcsp.sentinel.dashboard.server=localhost:18888 -Dproject.name=sentinel-dashboard -Dsentinel.dashboard.auth.username=rain -Dsentinel.dashboard.auth.password=rain -Dserver.servlet.session.timeout=7200 -jar sentinel-dashboard-1.8.6.jar
@SentinelResource 的 blockHandler 和 fallback 区别
blockHandler 是针对限流降级的处理函数, 需要和 rules 配合使用( 规则触发),并且参数需要和原方法一致
fallback 是针对熔断降级的处理函数, 不需要定义规则,仅当请求抛出异常的时候才会触发(异常触发)。参数可以和原方法不一致。
限流降级 : 控制流量进入资源的速率, 防止服务流量过载
需要设置限流策略,如限流大小、排队长度等。
熔断降级: 拉闸限止流量进入,快速返回错误响应, 快速失败,避免请求积压导致雪崩效应。
需要设置熔断策略,主要是熔断开启的错误率阈值和恢复策略
8.3. resilience4j
国外使用多, 基于Java 8开发的,并且只使用了vavr库
https://segmentfault.com/a/1190000019617975
9. 服务网关
zuul, spring-cloud gateway
用于路由. 前端请求通过网关, 转发给后端具体的 service, 集中进行统一的降级, 限流, 认证授权
9.1. 网关选型
https://codeantenna.com/a/HYlbT1VZT7
API 网关的好处:
简化客户端调用复杂度 (也就是路由功能): 在微服务架构模式下后端服务的实例数一般是动态的,对于客户端而言很难发现动态改变的服务实例的访问地址信息;
数据转换以及聚合: API Gateway可以对通用性的响应数据进行裁剪以适应不同客户端的使用需求。同时还可以将多个API调用逻辑进行聚合,从而减少客户端的请求数,优化客户端用户体验
集中做一些功能: 鉴权, 限流, 监控, 日志
遗留系统的微服务化改造
Zuul 1.x 构建于 Servlet 2.5,兼容 3.x,使用的是阻塞式的 API,不支持长连接,比如 websockets。但是 2.x 版本已经支持异步无阻塞 api (基于netty)
Spring Cloud Gateway构建于 Spring 5+,基于 Spring Boot 2.x 响应式的、非阻塞式的 API。同时,它支持 websockets,和 Spring 框架紧密集成。推荐
9.2. 网关高可用
https://blog.csdn.net/yangwenpei116/article/details/104250006/ https://www.cnblogs.com/SimpleWu/p/11004902.html TODO
9.3. nodejs
9.4. kong
需要 lua 脚本开发
9.5. openResty
就是 nginx + lua
9.6. zuul
进入 maintenance
zuul2 本来有改进, 但是用的不多
9.6.1. 什么是zuul
在Spring Cloud体系中, Spring Cloud Zuul就是提供负载均衡、反向代理、权限认证的一个API gateway。(提供动态路由,监控,弹性,安全等的边缘服务。Zuul是Netflix出品的一个基于JVM路由和服务端的负载均衡器。)
9.6.2. 基本使用
一般是配合注册中心一起使用, 在 eureka 的配合下, 只需要在某个 eureka client 下使用 @EnableZuulProxy (可看作 @EnableZuulServer 的增强), 即可代理所有 eureka 上的服务, 支持负载均衡
网关的默认路由规则: 默认情况下,Zuul会代理所有注册到Eureka Server的微服务,并且Zuul的路由规则如下:http://ZUUL_HOST:ZUUL_PORT/serviceId/** 会被转发到 serviceId 对应的 path。
自定义路由规则: http://ZUUL_HOST:ZUUL_PORT/zuul.routes.xxx.path/** 会被转发到 zuul.routes.xxx.url/**
http://www.ityouknow.com/springcloud/2018/01/20/spring-cloud-zuul.html http://www.ityouknow.com/springcloud/2018/02/02/spring-cloud-sleuth-zipkin.html
9.7. spring-cloud-gateway
9.7.1. 简单介绍
Spring Cloud Gateway requires the Netty runtime provided by Spring Boot and Spring Webflux. It does not work in a traditional Servlet Container or built as a WAR (使用 netty+webflux 实现因此不需要再引入 web 模块, 不能使用 servlet container)
工作流程: 请求进来, 如果在 Gateway Handler Mapping 中通过配置的一些断言, 找到与请求相匹配的路由,将其发送到 Gateway Web Handler, Handler 再通过指定的过滤器链来将请求发送到实际的服务执行业务逻辑,然后返回。
过滤器链条中, 经过 PreFilter —> 微服务 —> PostFilter 的方法,最终返回响应
9.7.2. 和注册中心配合
和 注册中心 一起使用 (动态路由), 需要打开开关, 默认的自动代理请求格式: http://网关地址/服务中心注册 serviceId/具体的path, 如: http://localhost:8888/EUREKA-SINGLE-CLIENT/hah (service name 可以配置小写), 如果路由的service有多个节点, 会自动负载均衡
9.7.3. 路由
route: 将 request 转发到具体的某个 service (id, uri, predicates, [filter])
搭配 predicate 使用
route有两种配置方式, 通过yml,或者 通过@bean自定义 RouteLocator;
一个请求满足多个路由的谓词条件时,请求只会被首个成功匹配的路由转发 (就近匹配);
注册到 registration center 后, 通过配置, 可以自动路由所有已注册的服务
9.7.4. predcates 介绍
predicate: 就是Java8中引入的的 Predicate, 输入是 ServerWebExchange, 可以获取 request, header, params
所有 predicate 返回true, 则当前 route matched
9.7.4.1. 有哪些内置 route predicate factory
Cookie
Cookie=chocolate, ch.p ","前面的为name,逗号后面的为值
Header
Header=X-Request-Id, \d+ ","前面的为name,逗号后面的为值
Host 通过指定 host (还是属于Header验证) 来匹配(多个host 用 "," 分隔, 支持 `**` 通配符, 如 `**.github.io`)
Host=**.somehost.org,**.anotherhost.org
Method
Method=GET,post
Query
Query=aaa,请求参数必须有name为aaa的参数
Query=aaa, 111:请求参数必须有name为aaa的参数,且aaa参数的值为111;
After
After=2021-03-17T15:47:51.534+08:00[Asia/Shanghai],日期时间,在该日期以后请求才被匹配
时间可以使用java.time.ZonedDateTime中的ZonedDateTime.now()获取当前时间
Before
Before=2022-03-17T15:47:51.534+08:00[Asia/Shanghai],日期时间,在该日期之前才被匹配
Between
Between=2021-03-17T15:47:51.534+08:00[Asia/Shanghai],2022-03-17T15:47:51.534+08:00[Asia/Shanghai],使用两个参数用逗号分隔,在两个时间范围内的请求才被匹配
RemoteAddr:通过请求ip匹配
RemoteAddr=192.168.1.1/24
Path 通过请求路径匹配,
Path=/red/{segment},/blue/{segment}
支持 "/foo/{segment}" 模板占位符的形式 在 filter 中可以使用占位符中的变量
如果请求路径是:/red/1或/red/blue或/blue/green,则此路由匹配。
Path=/gateway/**
支持模糊匹配
Weight 权重路由工厂有两个参数:group和Weight(int)。每组计算重量
Weight=group1, 2
9.7.4.2. 断言在代码中配置
9.7.4.3. 断言在yml中配置
两种配置方法
# 键值对方式, 简洁
spring:
cloud:
gateway:
routes:
- id: cookie_route
uri: https://example.org
predicates:
- Cookie=mycookie,mycookievalue
# 完全展开的方式, 标准方式
spring:
cloud:
gateway:
routes:
- id: cookie_route
uri: https://example.org
predicates:
- name: Cookie
args:
name: mycookie
regexp: mycookievalue
9.7.5. filter 介绍
filter: 可以修改请求和响应, 生命周期分为 "pre" 和 "post"
filter 分为: GatewayFilter 与 GlobalFilter。
GlobalFilter 会应用到所有的路由上(无需配置),
GatewayFilter 将应用到单个路由或者一个分组的路由上(需要跟Route绑定使用,不能在application.yml文件中配置使用)
GatewayFilter 亦可 通过 AbstractGatewayFilterFactory, 在内部实现, 不写单独的 Java类(这种方式同样要配置 route)
集成了 Hystrix, 自动进行负载均衡, 集成了 Spring Cloud DiscoveryClient,
使用场景: 鉴权、限流、日志输出
生命周期:
PRE: 这种过滤器在被代理的微服务(Proxied Service)执行之前调用。
我们可利用这种过滤器实现身份验证、在集群中选择请求的微服务、记录调试信息等。
POST:这种过滤器在被代理的微服务(Proxied Service)执行完成后执行。
这种过滤器可用来为响应添加标准的 HTTP Header、收集统计信息和指标、将响应从微服务发送给客户端等。
9.7.5.1. 有哪些 内置 filter
AddRequestHeader
AddResponseHeader
AddRequestHeader=X-Request-red, blue
DedupeResponseHeader
- DedupeResponseHeader=Access-Control-Allow-Credentials Access-Control-Allow-Origin
AddRequestParameter
AddRequestParameter=red, blue
AddRequestFilter
RedirectTo 重定向, 需要两个参数,status和url。status参数应该是300系列重定向HTTP代码,例如301。url参数应该是有效的url
RedirectTo=302, https://acme.org
SetPath 可以使用 Path 中的占位符变量 (通过模板设置路径)
SetPath=/app/{path} {path} 是 Path predicate 里的占位符
RewritePath 重写请求路径
RewritePath=/test, /app/test 访问网关localhost:8888/test, 请求会转发到localhost:8001/app/test
RewritePath=(?<oldPath>^/), /app$\{oldPath}
当请求网关localhost:8888/test时,匹配所有以/开头的路径,然后在前面加上/app,所以现在请求变成了localhost:8888/app/test。然后转发时的url变成了localhost:8001/app/test
(在yml文档中 $ 要写成 $\ )
PrefixPath 在转发后的请求路径前加上自定义的路径
PrefixPath=/app 访问网关 localhost:8888/test, 会被转发成 目标地址 localhost:1234/app/test
StripPrefix 去除Path 中的前缀 (指定级数)
StripPrefix=1 那么 /service1/hello --> /hello
9.7.5.2. 过滤器的配置方法-代码
9.7.5.3. 过滤器配置方法-yml
spring:
cloud:
gateway:
routes:
- id: add_request_header_route
uri: https://example.org
filters:
- AddRequestHeader=X-Request-red, blue
9.7.5.4. 自定义全局 filter
接口 GlobalFilter (定义全局 filter, 需要 @component), 影响所有 route; Ordered 接口定义顺序
// 实现授权、日志等功能
@Component
public class AuthorizeFilter implements GlobalFilter, Ordered {
private static final Logger log = LoggerFactory.getLogger(AuthorizeFilter.class);
private static final String AUTHORIZE_TOKEN = "token";
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain){
String token = exchange.getRequest().getQueryParams()
.getFirst(AUTHORIZE_TOKEN);
if ( StringUtils.isBlank( token )) {
log.info( "token is empty ..." );
exchange.getResponse().setStatusCode( HttpStatus.UNAUTHORIZED );
return exchange.getResponse().setComplete();
}
return chain.filter(exchange);
}
@Override
public int getOrder() {
return 0;
}
}
or
// 统计时间
@Component
class TimeRecordGlobalFilter implements GlobalFilter, Ordered {
private static final String TIME_BEGIN = "time begin";
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// log.info("custom global filter");
// return chain.filter(exchange);
exchange.getAttributes().put(TIME_BEGIN, System.currentTimeMillis());
return chain.filter(exchange).then(Mono.fromRunnable(() -> {
Long timeBegin = exchange.getAttribute(TIME_BEGIN);
if (timeBegin == null) {
throw new RuntimeException(">>> Error when get begin time");
}
System.out.println(">>> " + exchange.getRequest().getURI().getRawPath()
+ ": " + (System.currentTimeMillis() - timeBegin) + "ms");
}));
}
@Override
public int getOrder() {
//可以为负数, 小即首先进入
return 0;
}
}
9.7.5.5. 自定义普通 gateway filter
两种方式:
GatewayFilter, Ordered ( 无需 @component)
需要在 route 中使用代码硬编码配置 `xxx.filters(new MyFilter(), 不能在application.yml文件中配置使用
// 统计某个或者某种路由的处理时长
public class CustomerGatewayFilter implements GatewayFilter, Ordered {
private static final Logger log = LoggerFactory.getLogger( CustomerGatewayFilter.class );
private static final String COUNT_START_TIME = "countStartTime";
@Override
public Mono<Void> filter(ServerWebExchange exch, GatewayFilterChain chain) {
return chain.filter(exch).then(
Mono.fromRunnable(() -> {
long startTime = exch.getAttribute(COUNT_START_TIME);
long endTime=(Instant.now().toEpochMilli() - startTime);
log.info(exch.getRequest().getURI().getRawPath() + ": " + endTime + "ms");
})
);
}
@Override
public int getOrder() {
return 0;
}
}
如果希望在配置文件中配置Gateway Filter, 则通过自定义过滤器工厂实现;
继承抽象类 AbstractGatewayFilterFactory (实现 apply(config), config 为自定义参数)
@Component
public class CustomerGatewayFilterFactory extends AbstractGatewayFilterFactory<CustomerGatewayFilterFactory.Config> {
private static final Logger log = LoggerFactory.getLogger( CustomerGatewayFilterFactory.class );
private static final String COUNT_START_TIME = "countStartTime";
@Override
public List<String> shortcutFieldOrder() {
return Arrays.asList("enabled");
}
public CustomerGatewayFilterFactory() {
super(Config.class);
log.info("Loaded GatewayFilterFactory [CustomerGatewayFilterFactory]");
}
@Override
public GatewayFilter apply(Config config) {
return (exchange, chain) -> {
if (!config.isEnabled()) {
return chain.filter(exchange);
}
exchange.getAttributes().put(COUNT_START_TIME,
System.currentTimeMillis());
return chain.filter(exchange).then(
Mono.fromRunnable(() -> {
Long startTime = exchange.getAttribute(COUNT_START_TIME);
if (startTime != null) {
StringBuilder sb = new StringBuilder(
exchange.getRequest().getURI().getRawPath()
).append(": ")
.append(System.currentTimeMillis() - startTime)
.append("ms");
sb.append(" params:")
.append(exchange.getRequest().getQueryParams());
log.info(sb.toString());
}}));
};
}
public static class Config {
//控制是否开启统计
private boolean enabled;
public Config() {}
// getter setter 省略
}
}
配置:
spring:
cloud:
gateway:
routes:
- id: elapse_route
uri: lb://account-service
filters:
- Customer=true
predicates:
- Method=GET
or
- id: custom-filter-factory
uri: http://localhost:8080
predicates:
- Path=/service/**
filters:
- RewritePath=/service(?<segment>/?.*), $\{segment}
#简单配置, 但是这样就需要额外重写覆盖方法 shortcutFieldOrder()
#- Logging=My Custom Message, true, true
- name: Logging
args:
baseMessage: My Custom Message helloxxxx
preLogger: true
postLogger: true
另外一个例子
// 鉴权
@Component
public class AuthorizeGatewayFilterFactory extends AbstractGatewayFilterFactory<AuthorizeGatewayFilterFactory.Config> {
private static final Log logger = LogFactory.getLog(AuthorizeGatewayFilterFactory.class);
private static final String AUTHORIZE_TOKEN = "token";
private static final String AUTHORIZE_UID = "uid";
@Autowired
private StringRedisTemplate stringRedisTemplate;
public AuthorizeGatewayFilterFactory() {
super(Config.class);
logger.info("Loaded GatewayFilterFactory [Authorize]");
}
@Override
public List<String> shortcutFieldOrder() {
return Arrays.asList("enabled");
}
@Override
public GatewayFilter apply(AuthorizeGatewayFilterFactory.Config config) {
return (exchange, chain) -> {
if (!config.isEnabled()) {
return chain.filter(exchange);
}
ServerHttpRequest request = exchange.getRequest();
HttpHeaders headers = request.getHeaders();
String token = headers.getFirst(AUTHORIZE_TOKEN);
String uid = headers.getFirst(AUTHORIZE_UID);
if (token == null) {
token = request.getQueryParams().getFirst(AUTHORIZE_TOKEN);
}
if (uid == null) {
uid = request.getQueryParams().getFirst(AUTHORIZE_UID);
}
ServerHttpResponse response = exchange.getResponse();
if (StringUtils.isEmpty(token) || StringUtils.isEmpty(uid)) {
response.setStatusCode(HttpStatus.UNAUTHORIZED);
return response.setComplete();
}
String authToken = stringRedisTemplate.opsForValue().get(uid);
if (authToken == null || !authToken.equals(token)) {
response.setStatusCode(HttpStatus.UNAUTHORIZED);
return response.setComplete();
}
return chain.filter(exchange);
};
}
public static class Config {
// 控制是否开启认证
private boolean enabled;
public Config() {}
public boolean isEnabled() {
return enabled;
}
public void setEnabled(boolean enabled) {
this.enabled = enabled;
}
}
}
配置:
spring:
cloud:
gateway:
routes:
- id: user-service
uri: http://localhost:8077/api/user/list
predicates:
- Path=/user/list
filters:
# 关键在下面一句,值为true则开启认证,false则不开启
# 这种配置方式和spring cloud gateway内置的GatewayFilterFactory一致
- Authorize=true
9.7.6. gateway 配置方法
# enable gateway, default to true
spring.cloud.gateway.enabled=true
# route all services that registered in eureka server, default to false
spring.cloud.gateway.discovery.locator.enabled=true
# 具体的路由配置
# , spring.cloud.gateway.routes 是一个 list
# 比如
# route 的 id
spring.cloud.gateway.routes[0].id=demo-route
# Destination uri
# if you visit localhost:8080/hah then the request would be forward to cn.bing.com/hah
# 负载均衡 How to apply the filters to every node of one service? -> lb://spring-cloud-producer, 格式为:lb://应用注册服务名
spring.cloud.gateway.routes[0].uri=cn.bing.com
# 是一个 map, spring.cloud.gateway.routes[0].predicates
# 还有很多, 如 After=2019-07-04T05:50:53.346Z, Method...
spring.cloud.gateway.routes[0].predicates[0].name=Path
spring.cloud.gateway.routes[0].predicates[0].args
# add parameter xxx=yyy
spring.cloud.gateway.routes[0].filters.AddRequestParameter=xxx, yyy
更推荐 yaml 的配置:
spring:
application:
name: spring-cloud-gateway-demo
cloud:
gateway:
discovery:
locator:
# route all services that registered in eureka server, default to false
enabled: true
# 自动代理可以使用小写的 service name
lower-case-service-id: true
# enable gateway, default to true
enabled: true
# config route rule
routes:
- id: demo-route
# Destination uri, if you visit localhost:8080/Path then the request would be forward to cn.bing.com/Path
uri: http://localhost:8090
predicates:
- Path=/hah/**
- Method=GET
#- After=2019-07-04T05:50:53.346Z
filters:
# add parameter xxx=yyy
- AddRequestParameter=xxx, yyy
# How to apply the filters to every node of one service? -> lb://spring-cloud-producer, 格式为:lb://应用注册服务名, 这里其实默认使用了全局过滤器 LoadBalancerClient
- id: apply_filter_to_all_node_route
uri: lb://eureka-single-client
# PrefixPath Filter: add prefix to path, eg: - PrefixPath=/mypath
# StripPrefix Filter: split path, eg: /name/bar/foo -> /foo
# 可以利用这个功能来做特殊业务的转发。
- id: split_request_path
uri: http://eureka-single-client
predicates:
- Path=/name/**
filters:
# element num to be split
- StripPrefix=2
# Retry GatewayFilter:
- id: retry_test
uri: lb://spring-cloud-producer
predicates:
- Path=/retry
filters:
- name: Retry
args:
# retry times, default to 3
retries: 3
# http response status, ref to org.springframework.http.HttpStatus
statuses: BAD_GATEWAY
# which http method should retry, default to GET
methods: GET
#3 hystrix 不带 fallback 的配置
- id: hystrix_route
uri: http://example.org
filters:
# gateway 将使用 myCommandName 作为名称生成 HystrixCommand 对象来进行熔断管理
- Hystrix=myCommandName
# hystrix 带 fallback 的配置
- id: hystrix_route
uri: lb://spring-cloud-producer
predicates:
- Path=/consumingserviceendpoint
filters:
- name: Hystrix
args:
name: fallbackcmd
# 当调用 Hystrix 的 fallback 被调用时,请求将转发到/incaseoffailureuset这个 URI。
fallbackUri: forward:/incaseoffailureusethis
# RequestRateLimiter Filter, work with redis
# 配合 redis
- id: request_rate_limiter_route
uri: http://example.org
filters:
- name: RequestRateLimiter
args:
# Handing 10 request every second
redis-rate-limiter.replenishRate: 10
# Finishing 20 request every second
redis-rate-limiter.burstCapacity: 20
# reference bean with beanName using SpEL grammar
key-resolver: "#{@userKeyResolver}"
predicates:
- Method=GET
server:
port: 8888
通过代码硬编码配置路由:
@Configuration
class GatewayConfig {
@Bean
public RouteLocator routeLocator(RouteLocatorBuilder builder) {
// return builder.routes()
// .route("baidu_guonei", predicateSpec -> predicateSpec
// .path("/guonei").uri("http://news.baidu.com/guonei"))
// .route("baidu_guoji", predicateSpec -> predicateSpec
// .path("/guoji").uri("http://news.baidu.com/guoji"))
// .build();
return builder.routes()
.route("baidu_guonei", predicateSpec -> predicateSpec
.path("/**").uri("http://news.baidu.com"))
.build();
}
}
9.7.7. 网关监控
spring-boot-starter-actuator
management:
endpoints:
web:
exposure:
include: health,info,gateway
9.7.8. 超时配置
# 全局超时
spring:
cloud:
gateway:
# Http超时(响应和连接)可以为所有路由配置,并为每个特定路由重写。
httpclient:
connect-timeout: 1000 # 默认以毫秒为单位指定连接超时
response-timeout: 5s # 以秒为单位的配置方式
# 单个路由超时
- id: per_route_timeouts
uri: https://example.org
predicates:
- name: Path
args:
pattern: /delay/{timeout}
metadata:
response-timeout: 200
connect-timeout: 200
9.7.9. 跨域配置
spring:
cloud:
gateway:
globalcors:
cors-configurations:
# 在当前页面, 允许所有 来自 指定 url 的 get 方法
'[/**]':
allowedOrigins: "https://docs.spring.io"
allowedMethods:
- GET
10. 调用链路追踪
分布式系统下, 某个前端请求可能对应多个后端service, 如何定位这些service呢?
10.1. sleuth 和 zipkin
10.1.1. 分布式追踪
https://toutiao.io/posts/eaiifaf/preview
spring-cloud-sleuth + Zipkin (from twitter, https://zipkin.io/pages/quickstart.html)
分布式服务追踪理论基础来自 Google 的一篇论文
spring-cloud-sleuth: 提供链路追踪, 记录成功与否, 耗时; 一个完整的请求响应链路记录为一个 "trace", 可能包含多个 service调用, 称为 "span", 多个有序的 span 组成一个 trace (通过 parent id 联系起来); 如果仅仅引入 sleuth, 跟踪日志只会打到控制台 (引入即可, 自动记录, 如果只引入了 sleuth, 那么默认打到 控制台); 作为 zipkin 的信息收集器, 只是一个开源实现之一
Zipkin: 利用 zipkin 的存储来存储信息,利用zipkin ui来展示数据。
10.1.2. spring-cloud-sleuth
Trace:由一组 Trace Id 相同的 Span 串联形成一个树状结构。为了实现请求跟踪,当请求到达分布式系统的入口端点时,只需要服务跟踪框架为该请求创建一个唯一的标识(即TraceId)
Span:代表了一组基本的工作单元。为了统计各处理单元的延迟,当请求到达各个服务组件的时候, 通过SpanId 的开始和结束时间戳,就能统计该 span 的调用时间, spanId 也用来区分树结构中同层级节点的先后调用关系
10.1.3. zipkin 使用
zipkin 的使用分为两部分
每个 service 需要引入 zipkin client (spring-cloud-starter-zipkin, 已经包含 sleuth), 配置 zipkin server 地址和采样比例 (默认抽样 0.1 即 10%)
第二部分 zipkin server (
zipkin-server, zipkin-autoconfigure-ui), 配合@EnableZipkinServer, 最新版的 spring cloud 已经无需构建 zipkin server 了, 只需要启动 jar 包 (zipkin-server-xxx-exec.jar, from zipkin.io) 即可如果 zipkin 和 spring cloud stream, kafka 都在 classpath, 默认会将跟踪记录打到 kafka,
spring.zipkin.sender.type=web才会打到服务器日志追踪日志打到 kafka 更好, 相比使用 http 连 zipkin server, 会 更加稳定(因为消息中间件能够抗住短时间的大日志量), 会更解耦合
数据库支持 In-Memory (默认, 测试用)、MySql, Cassandra 以及 Elasticsearch (生产推荐)
链路跟踪有自己的线程池, 对业务线程不会有太大的影响
重要的配置:
spring:
zipkin:
# 指定了Zipkin服务器的地址
base-url: http://localhost:9000
sleuth:
sampler:
# 采样比例设置为1.0,也就是全部都需要。默认的采样比例为: 0.1(即10%)
percentage: 1.0
10.1.4. 使用案例
https://www.extlight.com/sleuth-basic.html
10.2. skyWalking
SkyWalking是一个可观测性分析平台(Observability Analysis Platform 简称OAP)和应用性能管理系统(Application Performance Management 简称 APM)。
两个功能:
- metrics
- tracing (日志追踪)
组件:
- agent : 负责从应用中,收集链路信息,发送给 SkyWalking OAP 服务器。目前支持 SkyWalking、Zikpin、Jaeger 等提供的 Tracing 数据信息。而我们目前采用的是,SkyWalking Agent 收集 SkyWalking Tracing 数据,传递给服务器
- SkyWalking OAP :负责接收 Agent 发送的 Tracing 数据信息,然后进行分析(Analysis Core) , 存储到外部存储器( Storage ),最终提供查询( Query )功能。
- Storage :Tracing 数据存储。目前支持 ES、MySQL、Sharding Sphere、TiDB、H2 多种存储器.
- SkyWalking UI :负责提供控台,查看链路等等
11. 业务日志收集
elk (elasticSearch, logstash, kibana) + kafka
通过 logstash
11.1. 日志怎么搜索 elasticSearch
底层是使用的 lucene 库, 实现全文搜索引擎
11.2. 日志怎么收集
logstash
又有新的替代方案: filebeat
11.3. 日志怎么展示
Kibana
kibana虽灵活,但需学习lucene语法,操作繁锁
12. 运维监控
虚拟机 / 容器 CPU 、Network 、Mem 等基础指标,
K8s 、物理机、虚拟机等管理
做好监控的真正难点不在于技术选型,而在于监控点覆盖、报警阈值调教、值班应急这一整套流程。
12.1. prometheus/thanos
prometheus 不能集群部署,单点有瓶颈
13. 消息总线
13.1. Spring-Cloud-Bus
是一个整合消息中间件进入分布式系统的框架,利用了MQ的广播机制在分布式的系统中传播消息,目前仅仅支持 Kafka 和 RabbitMQ 。
在应用之间传递状态变化 比如可以自己定义事件, 主动刷新缓存
和 spring cloud stream 区别: bus 一般用于基础设施的开发, 如管理配置的动态刷新, stream 用于业务功能的开发.
利用 bus 的机制可以做很多的事情:
配置中心客户端做动态刷新, 也就是全局广播 (可以避免动态刷新配置时, 对高可用部署的每个 service instance 执行 refresh post 请求), 以及热部署
定点通知/局部刷新 (就是指定更新某个具体 service),
http://config-server-address/actuator/bus-refresh/{destination}, 通过 destination 指定需要更新的 service 或者某个 instance如果希望只是通知 serviceA 的所有 instance, destination 即为 serviceA
如果只是希望通知 serviceA 的某个 instance (这个实例端口为 8000), destination 为 serviceA:8000
和配置中心配合的原理图: (不够好)
1、提交代码触发post给客户端A发送bus/refresh 2、客户端A接收到请求从Server端更新配置并且发送给Spring Cloud Bus 3、Spring Cloud bus接到消息并通知给其它客户端 (前提是所有节点都订阅二了同一个 topic, 默认是 springCloudBus) 4、其它客户端接收到通知,请求Server端获取最新配置 5、全部客户端均获取到最新的配置
更新git中的数据后, 访问client, 任然是旧的数据, 这时候, 向任意client实例发送一个 /actuator/bus-refresh 的post请求 curl -X POST http://...., 然后访问任意client, 数据均为latest的了
但这种方式并不优雅。原因如下:
打破了微服务的职责单一性。微服务本身是业务模块,它本不应该承担配置刷新的职责。
破坏了微服务各节点的对等性。
有一定的局限性。例如,微服务在迁移时,它的网络地址常常会发生变化,此时如果想要做到自动刷新,那就不得不修改 WebHook 的配置 (即 refresh post 发送给的对象地址会变化, 不得不修改))
现在将架构模式改成这样: (client引入mq支持消息总线, server端也要引入消息总线), 改为向 config server 发送 refresh 请求
和 spring cloud config 整合详细步骤: 在 config server 和每个 client 引入 spring cloud starter bus amqp (kafka 则就是 spring cloud starter bus kafka ), 有如下的默认配置, 如果自定义需要修改
spring.rabbitmq.host=localhost
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
spring.rabbitmq.port=5672
config server 还需 引入 spring boot starter actuator 然后配置如下以暴露 refresh 端点
# 如果是 yml 则需要加单引号
# health,info,bus-refresh
management.endpoints.web.exposure.include=*
怎么验证生效了呢? git repo 中 application.yml 中配置 common.aaa=hah, 启动 eureka, serviceA, serviceB, config server, 修改 common.aaa, 然后 commit/push, 向 config server 发送 curl -X POST http://config-server-address/actuator/bus-refresh, 然后分别通过两个 service 获取 common.aaa (注意类上加上 @refreshScope), 发现已经更新了.
跟踪总线事件: 只需设置spring.cloud.bus.trace.enabled=true,这样在/bus/refresh端点被请求后,访问/trace端点就可获得类似如下的结果:...
13.2. alibaba nacos 作为消息总线
14. spring-cloud-stream 消息驱动
是一个构建消息驱动微服务的框架, 将项目和具体的某个消息中间件解耦(如 rabbitqm, Kafka), 屏蔽底层消息中间件细节, 就像使用 jdbc 的 api 之后, 不必关心使用哪种具体的数据库
目前仅仅支持 rabbitmq, kafka
原理: 应用通过 spring cloud stream 提供的 input Chanel (app 通过它从 mq 中接收消息) 和 output Chanel (向 mq 发送消息) 来和 binder 交互. 有多种具体的 binder 实现, 分别对应不同的 mq;
遵循发布订阅模式, 通过 topic 进行广播 (topic 相当于 rabbit 中的 exchange, Kafka 中的 topic),
通过 @Input, @output 表示输入输出通道, 消费者使用 @streamListener 监听队列进行消息接收(用在方法上), @enableBinding 实现 Chanel 和 exchange 的绑定 (发送和接受的类上都有, 使用 Souce.class 发送源和 Sink.class接收区分)
使用细节 (以 rabbit 为例): 引入 spring-cloud-starter-stream-rabbit,
解决消息重复消费:
消息持久化:
动态创建通道
15. spring-cloud-data-flow
16. 分布式事务
16.1. seata
Seata 基本介绍
支持 XA, AT, TCC, SAGA 模式
AT 模式是无侵入的分布式事务解决方案,适用于不希望对业务进行改造的场景,几乎0学习成本。
XA
TCC 模式是高性能分布式事务解决方案,适用于核心系统等对性能有很高要求的场景。
Saga 模式是长事务解决方案,适用于业务流程长且需要保证事务最终一致性的业务系统,Saga 模式一阶段就会提交本地事务,无锁,长流程情况下可以保证性能,多用于渠道层、集成层业务系统。事务参与者可能是其它公司的服务或者是遗留系统的服务,无法进行改造和提供 TCC 要求的接口,也可以使用 Saga 模式
基本组件:
- seata server, 服务后端, 用来做分布式事务的全局管理
- 事务发起者, 就是分布式事务是从哪里发起的
比如一个接口A会调用其他服务 B, C, 那 a 就是事务发起者
- 事务参与者 即上面的 B, C
全局事务ID XID
16.2. 本地消息表
17. spring cloud alibaba 配合 dubbo
https://www.cnblogs.com/babycomeon/p/11546737.html rpc + restful 优雅的实现
https://www.bilibili.com/video/BV1B5411h71j
18. 实际设计案例 票务网站
票务类网站 (比如猫眼电影)
18.1. 业务架构
梳理功能
使用者: 面向海量的互联网用户
划分的模块: 支付, 用户, 商品, 订单, 排期... (以业务划分模块)
- 用户: 注册, 登录, 注销
- 商品: 搜索, 详情, 排期, 选座
- 订单: 生成, 取消
- 支付: 微信/支付宝支付
- 排期
- 基础模块 (如 区域, 图片)
18.2. 应用架构
划分职责, 拆分模块, 每个 module 有自己独立的 git 仓库, 独立的负责团队
前端应用
反向代理组件 (nginx)
网关
消费者app (消费应用) , 如 用户消费, 订单消费...
生产者app (服务应用), 如 用户服务, 订单服务...
微服务基础服务
如 注册中心, 配置中心, 链路跟踪中心, 限流中心
基础公共模块, 环境支持组件
如 缓存, 持续集成, 部署, 数据库, 日志, 消息 ... redis, jenkins, MySQL, nexus, elk, rabbitmq, kafka, nginx
为什么后台要分 消费者应用 和 服务提供者应用? 比如 用户模块会分为 用户消费模块和用户服务模块
如果不区分消费者module 和 service provider module 会造成:
调用关系混乱 (会相互调用)
某个module崩了, 会连累其他module
每个业务模块区分为 provider 和 consumer 后, 前端只和所有 consumer 交互
会有哪些好处:
调用关系清晰, 没有相互调用
消除了 某个 module 崩了带来的级联影响
比如 user service consumer 挂了, 还有 user service provider , 其他的 consumer 还能正常工作
(consumer 直接面向 外界, 出错几率大, provider 和数据库打交道, 出错几率小)
18.3. 技术架构
在应用架构基础上落地具体的技术
框架组件: spring boot, mybatis, MySQL
技术点: spring cloud技术栈, elk+kafka (日志), elasticSearch (搜索), rabbitmq (分布式事务), redis(缓存, setnx分布式锁), mycat (分库分表), docker+Jenkins (持续集成)
18.4. 数据库架构
- 基础库: 区域表, 图片表
- 节目库: 节目表, 提供方表, 类型表
- 订单库: 订单表, 订单联系人表; 订单表分库分表 order1, order2, order3
- 支付库: 交易表
- 排期库: 排期表, 座位表, 排期座位表
- 用户库: 用户表, 联系人表
18.5. 项目管理
git
sonarQube 代码缺陷, 规范
scrum 敏捷开发, 多个工期, 层层迭代, 持续交付
19. 案例 在线教育
19.1. 行业背景 and 商业模式
- c2c , 系统作为交易平台, 有视频提供者 (可能是个人提供者, 或者是专业的课程制作公司), 视频学习者, 如 51cto, 腾讯课堂
- b2c, 系统自己制作课程, 上传系统, 给学习者学习,
- 垂直领域, 专供一个方向的学习课程, 如 网易云课堂的微专业
- 直播/互动 (一对多模式), 为老师提供直播服务
- 1 对 1 模式, 如vipkid, 学而思
- 免费增值, 通过提供免费课程, 吸引用户, 通过提供一些增值服务赚钱, 如制作学位证书
20. 案例 聚合支付
20.1. 聚合支付概念
对接 微信, 支付宝, 银联, 提供统一的支付入口
主要做法/商业模式有这么几种:
- 提供线上聚合收银台(开放 api)
- 线下提供一码多付(消费者扫一个二维码就能微信支付宝...), 或者反过来商家扫码消费者完成支付
- 以 SaaS 服务交付给商户使用, 提供 订单管理, /门店管理/财务数据统计等基础服务, 以支付为入口, 提供 支付页广告营销/金融贷款...等服务
20.2. 集合支付项目架构
包括这些子系统: 官网/开放平台, 商户系统, 运营系统
架构:
- 用户层: app, h5, pc
- cdn: 分发静态资源, 如 js, css, 图片, 视频
- load balance: 4 层负载均衡, 7 层负载均衡
- UI 层: 前端页面
- 接入层: 网关, oauth2
- 服务层: 基础服务, 业务服务
- 数据层: MySQL, 缓存, 队列, 索引(es), 文件存储
20.3. 支付业务流程
- 商户注册
- 后台审核 (查资质, 营业执照...)
- 通过则放行
- 不通过则通知申请商户
- 商户购买套餐, 创建应用(即在聚合支付平台创建一个业务标识, 表示支付服务要用到什么业务), 填写支付渠道参数(若商户涉及到自己开发应用, 还需要集成)
- 商户测试/上线
- 消费者消费支付给商户
21. 案例 广告系统
https://www.modb.pro/db/32755 https://www.cnblogs.com/zhangpan1244/category/1522751.html
21.1. 广告概念
ad system: 终端根据条件数据请求广告系统, 返回合适的广告数据, 展示给浏览者
角色: 平台方, 广告主, 媒体方, 广告消费者
因为媒体数量会不断增长,因此广告投放系统是具有高并发、低延迟的特点
功能:
- 广告主的广告投放, 如
- 用户账户, 如宝马公司
- 推广计划, 如广告主制定了一个计划, 宝马 x6 推广计划, 这个推广计划包含多个推广单元
- 推广单元, 用来做限制动作, 请求命中一个推广单元后, 会返回一个/多个创意物料
- 关键词推广单元, 如, 只有包含指定关键词的请求才会命中这个广告单元
- 地域推广单元, 如只有来自指定区域的请求才会命中广告单元
- 兴趣推广单元,
- 人群推广单元
- 创意物料, 文本, 图片, 视频..., 每个创意都可以添加到一个/多个推广单元上
- 媒体方的广告曝光 (排序: 平台方收益依次减少, 广告主收益一次增加);
- cpt 按时间收费 cost per time (https://zhuanlan.zhihu.com/p/146391463 概念梳理, https://zhuanlan.zhihu.com/p/25265028 投放经验)
- cpm 按千次展现收费 cost per mille
- cpc 按点击收费 cost per click
- 超投: 对于CPC广告来说,即使计费系统及时发出下线反馈,但那些已经投放出去、尚未产生点击的广告仍然会可能产生超投。因此超投只能控制在一定范围之内,并不能完全杜绝
- 基于Kafka Streams构建广告消耗预测系统
- 对预算将近的广告计划,投放系统也应该降低投放频率,使预算极可能平滑地达到上限。
- cpa 按行为收费 如注册.下载
之所以有不同的结算方式,其实也是随着广告市场的发展逐渐衍生出来的,最开始流量稀缺,平台占优势,再到今天逐渐成了买方市场,广告主作为需求方的谈判权变大。 按CPA结算时对广告主最有利,但是对平台最不利。结算方式演进到今天,其实也是一种平衡,所以处于平衡点附近的CPM和CPC是最常见的结算方式。
21.2. 系统组成
- 投放系统, 最前端, 给广告主使用;
- 会员续费、广告库管理、设定推广条件、设置广告出价、查看投放效果
- 检索系统, 负责承接C端的流量请求,从海量广告库中筛选出最合适的前N个广告,并在几十毫秒内返回结果,它是一个多级筛选和排序的过程。
- 媒体方使用, 比如 app, 地铁通道大屏, 网页边栏
- 关注请求响应时间
- 倒排索引: 主要用于各个广告限制维度的检索; 如, 对于 table(unit_id, province, city), 根据地域 province/city 找到 unitID;
- 初期考虑存在 redis, 广告数据多了, 上 elasticsearch
- 索引维护方式: 全量索引 + 增量索引; 检索系统启动, 加载全量索引(启动时间点前的数据全部导出到文件中成为全量索引), 之后检索系统运行过程中不断添加增量索引(各个表的写操作)
- 计费系统, 核心任务是保证广告投放在预算范围之内,尽可能地避免发生超投 强调数据实时性
- 广告主需要预先充值一定的预算, 扣光了就不给他展现广告了
- 面向C端/媒体方,负责实时扣费,和收入直接挂钩,可用性要求高
- 结算系统, 结算系统提供的是广告平台与广告主之间费用结算服务,强调数据准确度, 包括充值、冻结、扣费等。
- 一般会以离线数据为基础进行计算,首先,这样可以以较少的成本保证数据完整性,因为如果像计费系统那样一来实时流计算,就不可避免地要面临服务可用性问题
- 结算系统与计费系统虽然都提供了费用计算的功能,但侧重点不同。
- 通常会引入“反作弊”的功能(比如一个用户短时间内多次点击,只收取一次点击的费用)
- 曝光检测系统, 给两拨人看的, 包含有我们自身的检测系统和第三方的监测系统 (可能广告主不信任平台, 需要请第三方参与监控, 对比第三方和我们自己的监测, 差别不大才会心甘情愿付费 )
- 运营后台, 给运营人员查看效果报表系统, 如展示了多少, 曝光了多少, 有多少广告请求没有检索到广告数据, 再就是
- 核心功能包括广告位管理、广告策略管理、以及各种运营工具
- AB实验平台, 广告业务的稳定器,任何广告策略上的调整均可以通过此平台进行灰度实验,观察收入指标的变化
- 大数据平台: 整个广告系统的底盘,需要聚合各种异构数据源,完成离线和实时数据分析和统计,产出业务报表,生产模型特征等
拓展:
- 添加更多的广告检索维度, 如地域, 兴趣
- 用户画像
- ai
21.3. 广告的核心业务流程
精准定向以及实时竞价是目前最主流的业务形态, 随着平台流量以及广告主规模进一步增大,往往会从「自营型竞价网络」逐渐向「联盟广告以及RTB实时竞价」方向发展,类似于阿里妈妈、腾讯广点通、头条巨量引擎
- 广告主先通过投放平台发布广告,可设置一系列的定向条件,比如投放城市、投放时间段、人群标签、出价等
- 投放动作完成后,广告会被存放到广告库、同时进入索引库,以便能被广告检索系统检索。
- C端请求过来后,广告检索系统会完成召回、算法策略、竞价排序等一系列的逻辑,最终筛选出Top N个广告,实现广告的千人千面
- 媒体方需要先行在广告检索系统中注册, 请求时, 携带这些参数: 媒体方标识, 匹配信息 (地域/兴趣/关键字, 逻辑操作符 and/or), 基本信息(请求 id, 设备信息, 广告位信息...)
- 响应: 广告创意(一个或多个)
- 用户点击广告后,会触发广告扣费流程,这时候平台才算真正获得收益
21.4. 技术难点
21.4.1. 广告数据的存储
- OLTP场景, 存储在支持事务的 db 中,包括广告库、创意库、会员库、广告产品库、广告策略库等,这些都存储在MySQL中,数据规模较大的广告库和创意库,按照广告主ID Hash做分库分表。
- OLAP场景,涉及到非常多的报表,聚合维度多,单表的记录数可能达到百亿级别,底层采用HDFS和HBase存储。
- 面向广告检索场景的索引数据,包括正排索引和倒排索引,采用Redis和ES来存储
- 广告的同步问题。广告投放完成后,首先会存储在MySQL数据库中,接下来需要把广告实时传输到检索系统中,完成正排索引以及倒排索引的更新
- 各个业务系统在推广、余额等信息变更时,发MQ消息,索引更新服务订阅MQ来感知变化,完成增量同步
- 变更的消息体中,不传递实际变更的字段,仅通知有变化的广告ID,索引更新服务实时读取最新数据完成更新,这样可以有效的解决消息乱序引起的数据不一致问题
- 当更新索引的并发达到一定量级后,可通过合并相同广告的变更、或者将倒排和正排更新分离的方式来提升整体的更新速度。
21.4.2. 广告数据检索
采用Redis缓存,缓存可按业务规划多套,进行分流。精简RPC返回结果或者Redis缓存对象的结构,去掉不必要的字段,减少IO数据包大小。
热点数据建立本地索引 (即内存 map, 使用 concurrentmap),比如广告位的配置信息以及策略配置信息,在服务启动时就可以预加载到本地,然后定时进行同步。(启动时, 加载全量索引, 运行中, 不断加载增量索引)
- 增量索引: 订阅 MySQL 的 binglog
采用多线程并行化某些子流程,比如多路召回逻辑、多模型打分逻辑
和主流程无关的逻辑异步执行,比如扣费信息缓存、召回结果缓存等
非核心流程设置超时熔断走降级逻辑,比如溢价策略(不溢价只是少赚了,不影响广告检索召回)。
GC优化,包括JVM堆内存的设置、垃圾收集器的选择、GC频次优化和GC耗时优化。
21.4.3. 计费平台的技术方案
- 扣费流程做了异步化处理,当收到实时扣费请求后,系统先将扣费时用到的信息缓存到Redis,然后发送MQ消息,这两步完成后扣费动作就算结束了, 利用MQ的可靠性投递和重试机制确保整个扣费流程的最终一致性
- 为了提高可用性,针对Redis和MQ不可用的情况均采用了降级方案。Redis不可用时,切换到TiKV(分布式键值对存储数据库)进行持久化;MQ投递失败时,改成线程池异步处理。
- 每次有效点击都需要生成1条扣费订单,面临大数据量的存储问题。目前我们采用的是MySQL分库分表; 后期考虑使用HBase等分布式存储
- 订单和结算系统数据同步, 通过Hive任务完成对账和监控。
21.5. 广告表设计
21.6. MySQL 的 binlog 实现增量索引
21.6.1. java 组件实现监控
mysql-binlog-connector-java
相关:
https://github.com/zendesk/maxwell a mysql-to-json kafka producer 这个也不错, 可以通过 kafka 实现分发
https://github.com/apache/nifi process and distribute data
21.6.2. binlog 配置 SQL
MySQL 配置文件中:
log_bin , binlog switch,
show variables like 'log_bin'binlog_format , binglog format,
show variables like 'binlog_format'ROW , binlog 会记录每行数据修改的细节, 如前后的值, 不记录 SQL;
binlog 巨大
数据一定可以被恢复
statement , 记录写操作的 SQL,
binlog 不大
SQL 中某些涉及到上下文的 函数/触发器 在恢复数据的时候可能出现问题
mixed, 两者的混合
show master logs; -- check binlog list
-- 常用
show master status; -- check number of the last binlog file and view the position where the last event ended
flush logs; -- generate a new binlog with a new number
reset master; -- clear all binlogs
/*
-- Event_type 列 (常用的Binlog event)
query_event 数据无关的操作, 如drop table, truncate table...
table_map_event 记录后续操作涉及到的表信息, 如dbname, tblname
xid_event 标记事务提交
write_rows_event 插入操作
update_rows_event 更新
delete_rows_event 删除
*/
show binlog events; -- view the first binlog
show binlog events in 'binlog.00030'; -- view specified binlog
show binlog events in 'binlog.00030' from 931 ; -- view specified binlog start from specified position
show binlog events in 'binlog.00030' from 931 limit 2; -- view specified binlog start from specified position and limit 2 lines
show binlog events in 'binlog.00030' from 931 limit 1, 2; -- view specified binlog start from specified position and limit 2 lines
22. 案例 电商类网站
22.1. 开发环境搭建
# 我是用的 respberrypi, MySQL 镜像需要使用 hypriot/rpi-mysql
docker run -d --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root -v /mydata/mysql/log:/var/log/mysql -v /mydata/mysql/data:/var/lib/mysql -v /mydata/mysql/conf:/etc/mysql hypriot/rpi-mysql
# nacos
# docker run -d --name nacos -p 8848:8848 -e MODE=standalone -v ~/docker_data/nacos/logs:/home/nacos/logs -v ~/docker_data/nacos/init.d/custom.properties:/home/nacos/init.d/custom.properties nacos/nacos-server
docker run -d --name nacos -p 8848:8848 -e MODE=standalone -v ~/docker_data/nacos/logs:/home/nacos/logs nacos/nacos-server
# 先创建 /mydata/redis/conf/redis.conf, 否则 文件挂载时 redis.conf 被识别为 目录
mkdir -p /docker-data/reids/conf
touch /docker-data/reids/conf/redis.conf
sudo docker run -d --name redis -p 6379:6379 -v /mydata/redis/data:/data -v /mydata/redis/conf/redis.conf:/etc/redis/redis.conf redis /etc/redis/redis.conf
# redis 可视化管理界面
docker run -d --name redis-cmder -p 8079:8081 --link redis:re -e REDIS_HOSTS=re:6379 rediscommander/redis-commander
22.2. 行业术语
- spu (standard product unit) 标准化产品单元, 是一组商品特性的集合, 是商品信息聚合的最小单位, 通俗说就是商品名称, 如 iPhone X, Mi 8 , 类比 Java 中的 class
- sku (stock keeping unit) 库存单元, 是库存计量的基本单位, 是销售属性的集合(颜色, 内存..., 其他属性属于通用属性如网络, 像素..可以直接和 spu 关联), 如 iPhone X 64G 黑色, Mi8+64G+黑色, 类比 Java 中的 实例对象, 同个 spu 有多个不同 sku; 可以决定价格
22.3. 业务流程分析
22.3.1. 商品新增
22.3.2. 商品上架
给定一个 spu id, 将相关数据存入 es, 以便检索
哪些数据进入 es?
- spu, 商品规格(普通属性)检索时需要, 分类检索时也需要
- sku, 进入商品主页, 选择颜色, 屏幕 是需要检索, 此外还要检索 sku标题, 价格, 销量
22.4. elasticsearch 数据建模分析
商品上架: spu 相关信息会被存储到 es, 如 颜色, 内存, ram, 标题
比较分析:
- 对于 模型 1: 若有 100万商品, 每个商品基本属性占用存储 2kb, 1000000 0.002mb == 2000mb == 2000 0.001 G == 2G, 就是加一个内存条的事儿, 完全可以接受
- 对于 模型 2: 假如某个人搜索小米, 向 es 发送一个请求, 可能会出现很多 spu, 如 手机/电器/路由器/床垫..., 假设有 4000 个 spu, 接下来根据 spuId 查对应 基础属性显示在过滤栏位, 4000spuId 每个id 是 Long 类型 8 个字节 == 4000 8 byte == 32000 byte == 32 kb. 即一个请求至少会向 es 发送 32kb 数据, 假设 10000 人并发检索小米, 10000*32kb === 320mb, 百万人并发就直接是 32G 了, 这完全不可接受
所以选择模型 1, 以空间换时间
// 模型 1: 只有一个索引
// 方便检索, 但是有数据冗余, 如 同一个 spu 下不同的 spu 商品的 attr 都相同
{
"spuId": 11, // 如 iPhone X
"skuId": 1, // 64G, 黑色
"skuTitle": "iPhone x 64G 黑色",
"price": 1000,
"saleCount": 20000,
"attrs": [
{"尺寸": 4.5},
{"CPU": "高通"},
{"分辨率": "高清"}
]
}
// 模型 2: 分为两个索引
// 没有数据冗余, 但是检索时更耗时, 因为数据传输量大大增加了
// sku 索引
{
"spuId": 11, // 如 iPhone X
"skuId": 1, // 64G, 黑色
"skuTitle": "iPhone x 64G 黑色",
"price": 1000,
"saleCount": 20000
}
// attr 索引
{
"spuId": 11, // 如 iPhone X
"attrs": [
{"尺寸": 4.5},
{"CPU": "高通"},
{"分辨率": "高清"}
]
}
最终 product index 导入是这样的:
PUT product
{
"mapping":{
"properties":{
"skuId":{
"type":"long"
},
"spuId":{
"type":"keyword"// 类似 text, 不分词
},
"skuTitle":{
"type":"text", //分词
"analyzer":"ik_smart"
},
"skuPrice":{
"type":"keyword"
},
"skuImg":{// 图片链接
"type":"keyword",
"index":false, // // 不可检索
"doc_values":false // 不需要 聚合操作, 省空间, 默认 true
},
"saleCount":{// 销量
"type":"long"
},
"hasStock":{
"type":"boolean"
},
"hotScore":{
"type":"long"
},
"brandId":{
"type":"long"
},
"categoryId":{
"type":"long"
},
"brandName":{
"type":"keyword",
"index":false,
"doc_values":false
},
"brandImg":{
"type":"keyword",
"index":false,
"doc_values":false
},
"categoryName":{
"type":"keyword",
"index":false,
"doc_values":false
},
"attrs":{
"type":"nested" , // 这属性是嵌入式的, 表示 attrs 是一个 对象 or 对象组成的数组
// 如果不指定的话 es 会将这个属性扁平化处理, 将对象内的属性抽取到外层形成多个这样的属性 attrs.attrId, attrs.attrName, ....
"properties":{
"attrId":{
"type":"long"
},
"attrName":{
"type":"keyword",
"index":false,
"doc_values":false
},
"attrValue":{
"type":"keyword"
}
}
}
}
}
}
22.5. 缓存分析
哪些数据适合放入缓存? (不经常改变, 访问量大, 一致性要求不高的数据), 失效时间根据业务需求定
- 商品分类, 商品列表
缓存一致性方案:
- 对于用户相关的数据(订单数据, 个人信息...), 并发读写几率很小, 基本上没有缓存不一致问题, 采用设置缓存过期的策略
- 首页菜单, 商品介绍这类数据, 能够容忍一定的不一致, 使用 canal订阅 binlog 的方式
- 通过加读写锁, 保证并发读写
22.6. 部署架构分析
client(browser...) --> nginx --> 网关集群 --> services
22.7. 异步处理分析
一个是可以通过 completableFuture
一个是通过 mq
22.7.1. mq
异步: 处理注册流程 (异步发送短信)
解耦: 下单后的出库操作, 通过 mq 调用减库存接口, 使得订单系统和库存系统解耦
流量控制: 对于瞬时大量请求, 先堆积在 mq, 后面慢慢处理
23. 案例 物联网平台
https://github.com/jetlinks/jetlinks-community https://open.iot.10086.cn/